




I. Introduction▲
Ce tutoriel est (très) long. J'ai essayé d'expliquer toutes les notions rencontrées dans le détail. Si vous n'avez pas le temps, allez directement à la fin de l'article pour télécharger le zip du projet. Vous pourrez ainsi décortiquer le code et revenir sur cette page pour avoir des explications sur la partie qui vous intéresse.
Si vous êtes ici, c'est que vous avez lu la première partie du tutoriel. Si ce n'est pas le cas, faites-le maintenant, cela ne pourra que vous être utile. Nous avons donc notre éditeur Assembleur qui ne fait pas grand-chose, si ce n'est afficher du texte noir sur fond blanc et une jolie icône à côté des documents ayant une extension .asm.
Cette partie contient un volume de code nouveau assez important. Aussi, j'ai préféré ne présenter ici que l'essentiel. Le projet Eclipse correspondant à ce qui est développé ici est fourni dans un zip en bas de cette page. Si vous préférez que tout le code soit présenté et détaillé dans le tutoriel, faites-le-moi savoir, j'effectuerai les modifications. Contrairement à la première partie où tout le travail a été fait par Eclipse, ici le programmeur/concepteur est beaucoup plus mis à contribution.
Comme pour le premier, la majeure partie de ce tutoriel est en fait une explication des concepts mis en œuvre qui sont appliqués via le plug-in d'éditeur Assembleur.
Comme d'habitude, je ne prétends pas que les solutions données ici sont les meilleures, si vous avez des suggestions quant à l'amélioration des méthodes utilisées, je me ferais un plaisir de les intégrer.
Un dernier petit détail, la coloration syntaxique sera plus efficace (coloration des directives, etc.) sur du code écrit pour le compilateur NASM. Adapter la coloration à d'autres syntaxes (MASM, TASM, FASM, etc.) peut être un bon exercice de prise en main.
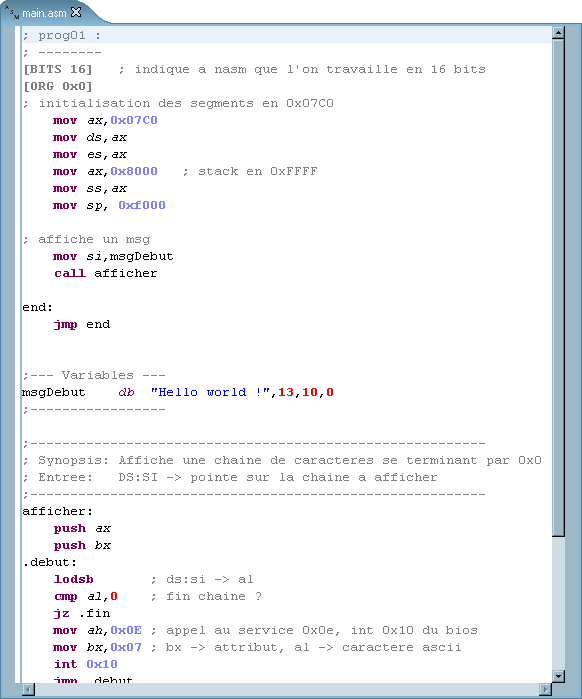
Voici ce à quoi nous allons arriver… (code extrait de Bosokernel).
II. DocumentSetup, partitions et Cie▲
II-A. Personnaliser la gestion des documents : DocumentSetup▲
Le point d'extension org.eclipse.core.filebuffers.documentSetup est utilisé pour ajouter des composants réalisant des opérations particulières lors de l'initialisation du document. Il permet de définir un DocumentSetupParticipant qui gérera l'enchaînement de ces opérations en fonction du type de fichier, de son extension ou de son nom.
L'utilisation d'un DocumentSetupParticipant est utile pour mettre en place certains mécanismes, notamment ceux nécessaires à la coloration syntaxique, qui ont besoin d'être initialisés dès la création du document. Par création, on entend création dans Eclipse, c'est-à-dire création physique ou ouverture d'un document existant.
Les DocumentSetupParticipant doivent implémenter l'interface org.eclipse.core.filebuffers.IDocumentSetupParticipant qui ne définit qu'une seule méthode, setup(IDocument document), dont le but est d'effectuer toutes les initialisations nécessaires à l'utilisation du document par l'éditeur.
II-B. Les documents textes et Eclipse : les partitions▲
Avant de nous plonger plus avant dans la mise en place de la coloration syntaxique, il faut comprendre la façon dont Eclipse "voit" un document texte. Pour lui, il s'agit d'une suite de partitions. Celles-ci ont la même définition qu'en mathématiques : il s'agit d'un ensemble de régions qui couvrent la totalité du document sans jamais se chevaucher. À une partition on affecte un déplacement (décalage par rapport au début du fichier), une longueur et un type. Elles sont représentées par l'interface org.eclipse.jface.text.ITypedRegion dont une implémentation standard est fournie (org.eclipse.jface.text.TypedRegion).
Ce concept est très important pour la coloration syntaxique, car celle-ci est appliquée en fonction des partitions : les mots-clés, couleurs, etc. varient selon le contexte.
L'entité qui s'occupe de découper le document en partitions est appelée Partitioner, elle doit étendre l'interface org.eclipse.jface.text.IDocumentPartitioner. Eclipse nous fournit un DocumentPartitioner par défaut qui utilise un IPartitionTokenScanner. Ce type d'entité renvoie une suite de Tokens correspondant aux partitions, ainsi que différentes informations (déplacement, taille, etc.). Eclipse propose une implémentation de IPartitionTokenScanner qui utilise des règles définies par le développeur pour analyser le document, le RuleBasedPartitionScanner. Nous utiliserons ces mécanismes plus loin dans ce tutoriel.
Depuis la version 3 d'Eclipse, il est possible d'ajouter plusieurs Partitioner à un même document. Aussi, chaque partitionnement est identifié par un String. De même, chaque type de partition est identifié par un String qui est ensuite repris pour paramétrer les actions spécifiques à ce type de partition.
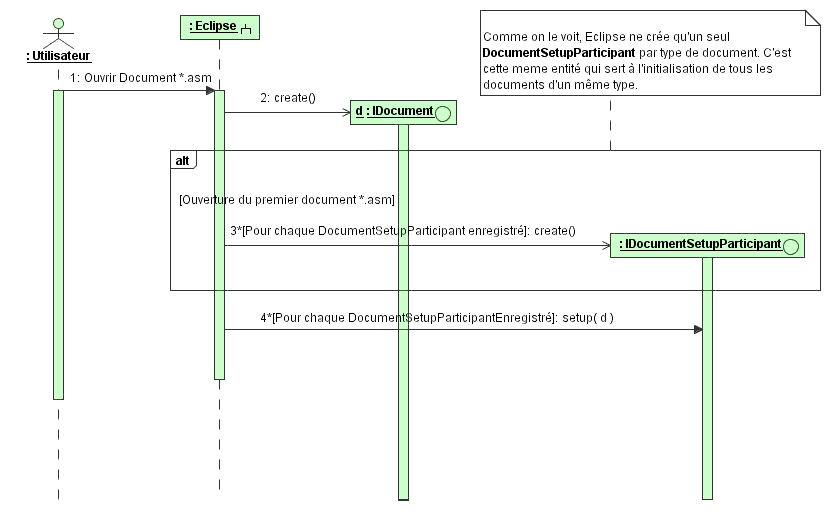
Mécanisme des DocumentSetupParticipant dans le cadre des documents *.asm
II-C. Configurer la présentation : la SourceViewerConfiguration▲
Nous n'aborderons pas ici la totalité des utilisations de la SourceViewerConfiguration, en effet, cette entité nous servira à plusieurs reprises dans la suite de cette série et nous la détaillerons au fur et à mesure. Cette classe sert, comme son nom l'indique, à configurer l'affichage du texte. C'est elle qui gère la coloration syntaxique (ou du moins qui en met en place les mécanismes), l'auto-indentation, le formatage (Ctrl + I sur Eclipse 3), la complétion automatique, etc.
La classe org.eclipse.jface.text.source.SourceViewerConfiguration fournie par Eclipse ne fait pratiquement rien. Elle se contente de gérer la sélection d'un mot lorsque l'on double-clique dessus. Elle n'est donc là que par défaut et il faut en dériver sa propre classe pour adapter son comportement.
Pour ce tutoriel, nous ne nous préoccuperons que des méthodes concernant le partitionnement et la coloration syntaxique en fonction des partitions.
II-C-1. Information sur les partitions▲
Comme nous l'avons dit, la configuration des partitions se fait au niveau du DocumentSetupParticipant. Toutefois, la SourceViewerConfiguration doit fournir des informations quant au type de partitionnement mis en place et aux partitions qu'il est possible de rencontrer. Les deux méthodes qui en ont la charge sont respectivement getConfiguredDocumentPartitioner et getConfiguredContentTypes. La première renvoie l'identifiant du partitionnement géré par la configuration, la seconde renvoie tous les types de partition qu'il est possible de rencontrer dans le document.
II-C-2. Adapter la coloration aux modifications : Damager et Repairer▲
Afin d'appliquer une coloration syntaxique lorsque le document est ouvert ou modifié, Eclipse utilise ce que l'on appelle des Damagers et des Repairers. Les premiers sont chargés de déterminer quelle partie du document est impactée par une modification donnée, tandis que les seconds doivent reconstruire la région indiquée comme endommagée.
L'entité coordonnant les Damagers et les Repairers est le Reconciler. Le damager lui indique la région endommagée par une modification, cette région est ensuite passée au repairer pour qu'il applique les changements nécessaires au document.
C'est la méthode getPresentationReconciler(ISourceViewer) de la SourceViewerConfiguration qui renvoie le Reconciler utilisé pour un document donné. Une fois le partitionnement mis en place, c'est au niveau de cette méthode qu'il nous faudra agir pour paramétrer les différents mécanismes utiles à la coloration syntaxique proprement dite.
N'ayez pas peur, l'API Eclipse est bien fournie et nous n'aurons pas à aborder les mécanismes relativement complexes utilisés par toutes ces entités. Comme pour le partitionnement, nous utiliserons des règles nous permettant d'appliquer une coloration en fonction du contexte.
III. Présentation de NASM▲
Comme je l'ai dit en introduction, la coloration syntaxique que nous allons mettre en place s'applique principalement à NASM. En ce qui concerne les opcodes (instructions assembleur), elle sera bien sûr compatible quel que soit le compilateur, mais pour tout ce qui est directives préprocesseur, macros, etc. seules les caractéristiques de NASM seront prises en compte.
Pour ceux qui ne connaissent pas du tout l'assembleur, il existe des tutoriels sur developpez.com. Je présenterai au fur et à mesure les notions importantes (en ce qui concerne la coloration). Pour ce qui est de NASM en particulier, je vous invite à consulter le site officiel et à télécharger le manuel. J'ai indiqué dans les commentaires du code les pages dont je me suis servi pour récupérer les informations.
Pour faire court, l'assembleur est aussi appelé langage machine, il s'agit du langage le plus proche de la machine et il est donc, syntaxiquement, assez simple. On trouve une instruction par ligne (nous occultons ici le fait qu'il soit possible de prolonger la même instruction sur plusieurs lignes). Les commentaires sont précédés d'un point-virgule (;) et finissent avec la ligne, c'est ce qui nous importe dans un premier temps pour mettre en place le partitionnement.
IV. Partitionnement▲
IV-A. Détermination des partitions possibles▲
Comme je l'ai dit précédemment, les commentaires sont précédés d'un point-virgule, bien entendu, la coloration à l'intérieur de ceux-ci ne sera pas la même que celle du code. Cela nous fait donc déjà deux partitions (deux types de contenus) :
- le code (type de contenu par défaut) ;
- les commentaires.
Le fait que le code soit le type de contenu par défaut induit simplement que l'on n'a pas à définir de règle pour lui. En effet, si aucune règle n'est déclenchée lors de l'analyse, c'est un token du type IDocument.DEFAULT_CONTENT_TYPE qui est renvoyé. Ce comportement nous convient très bien, il suffit de s'en souvenir pour le moment où nous appliquerons la coloration (puisque, je le rappelle, celle-ci se fait en fonction du type de partition).
On pourrait penser que la définition de ces deux partitions est suffisante, néanmoins, ce serait une erreur. En effet, si l'on ne considère que le code et les commentaires avec le passage de l'un à l'autre par un point-virgule ou une fin de ligne, la présence d'un point-virgule au sein d'une chaîne entraine le passage en commentaire, ce qui n'est pas souhaitable. Il faut donc définir un type de partition "virtuel" pour les chaînes de caractères (dans NASM, elles sont définies indifféremment par des simples ou des doubles quotes) afin d'éviter ce genre de désagréments. Je dis virtuel, car en fait, nous allons faire en sorte que les chaînes soient traitées comme le code assembleur (ce qui est logique puisqu'elles en font partie).
IV-B. Création du partitioner▲
IV-B-1. Ajout des dépendances et création de la classe▲
Nous allons maintenant mettre en place le partitionnement. Pour cela, nous allons utiliser l'API d'Eclipse. Tout d'abord, il faut ajouter une dépendance à notre plug-in afin de disposer de toutes les classes adéquates. Ajoutez la dépendance org.eclipse.jface.text (si vous ne vous souvenez plus comment procéder, jetez un œil à la première partie de ce tutoriel). Elle nous servira tout au long de cette partie, car c'est elle qui définit les interfaces à implémenter, ainsi que des implémentations par défaut et les classes de règles qui simplifient la gestion de la coloration.
Une fois la dépendance ajoutée, créez une nouvelle classe nommée, par exemple, ASMPartitionScanner qui étend org.eclipse.jface.text.rules.RuleBasedPartitionScanner. La seule chose que nous avons à faire ici est de définir un constructeur par défaut qui positionnera les règles nécessaires au partitionnement en appelant la méthode setRules.
IV-B-2. Règles utilisées▲
Nous n'utilisons dans ce constructeur que deux types de règles :
- EndOfLineRule qui définit une règle commençant par une chaine donnée et se terminant avec la ligne. Il est possible d'indiquer un caractère d'échappement afin de faire en sorte que la ligne suivante soit considérée comme le prolongement de la ligne en cours. Cette règle est utilisée pour les commentaires ;
- SingleLineRule est similaire à EndOfLineRule excepté qu'elle commence par une chaîne donnée et se finit par une autre chaîne ou avec la fin de la ligne. Il est possible d'indiquer un caractère d'échappement et de spécifier si la détection de la fin du fichier termine la règle ou non.
Pour chaque règle, on indique le type de token retourné lorsqu'elle est détectée. Un token est une entité implémentant l'interface org.eclipse.jface.text.rules.IToken. À cette entité est rattaché un Object (donc n'importe quelle classe). Dans le cas du découpage d'un document en partitions, cet objet est une chaîne contenant l'identifiant de la partition.
Comme je l'ai dit précédemment, il faut éviter que des commentaires puissent être commencés dans des chaînes. Pour cela on ajoute deux règles particulières. Il s'agit de SingleLineRule commençant par des quotes ou des doubles quotes et qui renvoient un Token indéfini (Token.UNDEFINED). Cela entraîne que le type de contenu est considéré comme étant le type de contenu par défaut (et donc comme du code) mais empêche le déclenchement d'une autre règle (en particulier celle des commentaires).
Voici le code de l'ASMPartitionScanner :
/**
* Classe en charge du partitionnement des fichiers assembleur.
* @author Sébastien Le Ray
*/
public class ASMPartitionScanner extends RuleBasedPartitionScanner {
/** Identifiant de la partition de commentaires (valeur : "__pos_asm_comment") */
public final static String ASM_COMMENT = "__pos_asm_comment";
/** Tableau contenant tous les types de partitions possibles */
public final static String[] ASM_PARTITION_TYPES =
new String[] {
ASM_COMMENT,
};
/**
* Constructeur par défaut. Positionne les différentes règles.
*/
public ASMPartitionScanner() {
super();
// Token renvoyé dans le cas d'un commentaire
IToken asmComment = new Token(ASM_COMMENT);
/* Nous sommes obligés d'avoir des règles pour les
* chaînes afin d'éviter que des commentaires ne soient
* démarrés à l'intérieur de chaînes ("eoi ; toto", toto
* passe en commentaires ce qui n'est pas souhaité). */
IPredicateRule[] rules = new IPredicateRule[] {
// Règle pour les commentaires
new EndOfLineRule(";", asmComment),
/* On met un token UNDEFINED pour traiter les chaînes en tant
* que code Java.
*/
new SingleLineRule("\"", "\"", Token.UNDEFINED, '\0', true),
new SingleLineRule("'", "'", Token.UNDEFINED, '\0', true)
};
// Prend en compte les règles
setPredicateRules(rules);
}
}IV-C. Intégration du partitionnement▲
IV-C-1. Création du DocumentSetupParticipant▲
Il faut encore faire en sorte que le partitionnement soit pris en compte au niveau de l'éditeur. Pour cela, nous devons indiquer le Partitioner à utiliser en fonction du type de document. La façon la plus propre de faire cela est de définir un DocumentSetupParticipant pour les fichiers asm.
Créez donc une classe implémentant org.eclipse.core.filebuffers.IDocumentSetupParticipant. Il faut implémenter la méthode setup(IDocument) dans laquelle on instancie un nouveau partitioner qui utilise le PartitionScanner que nous avons créé précédemment. Le partitioner est ensuite positionné comme partitioner pour le type de partition correspondant à l'assembleur. On finit par connecter le document au partitioner.
Comme il est possible d'utiliser le même Partitioner pour plusieurs documents en parallèle, nous ajoutons un getter dans la classe gérant le comportement du plug-in. Ainsi, un seul Partitioner sera instancié pour tous les éditeurs.
Voici le code du DocumentSetupParticipant :
/**
* Classe participant à l'initialisation du document.
* @author Sébastien Le Ray
*/
public class ASMDocumentSetupParticipant implements
IDocumentSetupParticipant {
/**
* Méthode appelée pour l'initialisation du document.
* Positionne le DocumentPartitioner pour l'assembleur.
* @param document Document à initialiser.
* @see org.eclipse.core.filebuffers.IDocumentSetupParticipant#setup(org.eclipse.jface.text.IDocument)
*/
public void setup(IDocument document) {
if (document instanceof IDocumentExtension3) { // Notion de partitionnements multiples
IDocumentExtension3 extension3= (IDocumentExtension3) document;
// Crée le partitioner
IDocumentPartitioner partitioner= new DefaultPartitioner(
ASMEditorPlugin.getDefault().getASMPartitionScanner(),
ASMPartitionScanner.ASM_PARTITION_TYPES);
// Attache le partitioner au document.
extension3.setDocumentPartitioner(ASMEditorPlugin.ASM_PARTITIONING, partitioner);
// Attache le document au partitioner.
partitioner.connect(document);
}
}
}IV-C-2. Ajout du point d'extension▲
Pour que le partitioner soit associé aux fichiers assembleur, il faut que le DocumentSetupParticipant soit reconnu par Eclipse. Pour cela, on procède comme dans la première partie de ce tutoriel. Le point d'extension est org.eclipse.core.filebuffers.documentSetup, on y crée un nouveau participant avec les attributs suivants :
- class : indique la classe à utiliser pour l'initialisation du document. Elle doit implémenter IDocumentSetupPartitipant, il s'agit de celle que nous venons de créer ;
- extensions permet d'indiquer les extensions que l'on veut voir traitées par le DocumentSetupParticipant (pour nous asm) ;
- fileNames spécifie des noms de fichiers plutôt que des extensions ;
- contentTypeId correspond à un type de contenu auquel on veut attacher le DocumentSetupParticipant, celui-ci doit être défini au niveau du point d'extension org.eclipse.core.runtime.contentTypes.
Une fois le point d'extension renseigné, le partitioner est pris en compte par Eclipse et nous pouvons passer à la coloration syntaxique.
V. Coloration▲
V-A. Classe utilitaire▲
La mise en place de la coloration syntaxique nécessite la création de diverses classes, SourceViewerConfiguration, CodeScanners, Rules, etc. Mais nous allons commencer par créer une classe qui nous servira de conteneur pour les attributs des différentes entités. Cela permet de les centraliser et facilite donc les modifications (ou la mise en place d'une gestion de la personnalisation par les utilisateurs).
Cette classe se contente de déclarer des chaînes constantes correspondant à chacun des types d'entités que l'on souhaite colorer. La seule méthode accessible à l'utilisateur est getAttribute qui renvoie le TextAttribute correspondant à l'identifiant qu'on lui passe en paramètre. Un TextAttribute contient des informations sur la couleur de texte, la couleur de fond et le style de la police à utiliser.
V-B. CodeScanner▲
Puisque nous allons utiliser les Damagers et les Repairers par défaut d'Eclipse, l'entité qui applique la coloration syntaxique à chaque partition doit implémenter org.eclipse.jface.text.rules.ITokenScanner. Cette interface définit des méthodes qui ont pour charge d'analyser le document sur des intervalles donnés et de renvoyer des Tokens. En ce qui concerne la coloration syntaxique, ces Tokens contiennent le TextAttribute à appliquer au texte concerné.
Comme pour le partitionnement nous n'allons pas implémenter directement l'interface mais dériver une classe à partir de org.eclipse.jface.text.rules.RuleBasedScanner. Le RuleBasedScanner est très similaire au RuleBasedPartitionScanner excepté qu'il n'est pas destiné à scanner les partitions. La méthode à utiliser pour définir les règles change de nom et s'appelle setPredicateRules (si vous appelez setRules, une exception UnsupportedOperationException est levée). Les règles sont analysées selon leur position dans le tableau qui est passé à la méthode setPredicateRules, cela peut être important pour certains langages où un type de commentaires commence par /* et un autre par /**, il faut faire passer la règle concernant /** avant sinon elle est occultée par l'autre.
V-B-1. WordRule▲
V-B-1-a. Présentation▲
Le plus gros du travail consiste en fait à répertorier tous les mots-clés et à les intégrer dans le code sous forme de chaînes constantes. Ensuite, il faut les faire prendre en compte au Scanner. Pour cela, on utilise un nouveau type de règles, la WordRule.
Une règle de type WordRule peut être utilisée de différentes façons :
- soit pour colorer des mots particuliers que l'on indique à la règle ;
- soit pour colorer tous les mots commençant par un caractère donné.
Nous utiliserons ces deux méthodes de fonctionnement dans l'éditeur assembleur.
V-B-1-b. Détection de mots particuliers▲
La mise en place de la détection d'une liste de mots se fait en deux temps : tout d'abord, on indique à la règle les caractères valides en début de mots ainsi que les caractères faisant partie d'un mot au moyen d'une classe implémentant IWordDetector. Ensuite, on ajoute à la règle la liste des mots en précisant pour chacun quel Token doit être renvoyé (et donc quel style doit être appliqué au texte).
L'interface IWordDetector définit deux méthodes : isWordStart(char c), qui renvoie true si le caractère analysé est valide en début de mot, et isWordPart(char c) qui indique si le caractère doit être considéré comme faisant partie d'un mot.
Cette notion de partie d'un mot est subtile. En fait la WordRule va boucler et comparer à sa liste de mot tant que les caractères sont valides en tant que partie d'un mot. Cela signifie que si vous avez une liste avec des mots qui ne contiennent que des lettres, vous pourriez vous dire que les chiffres ne sont pas valides en tant que parties de mots et donc renvoyer false dans ce cas lorsque isWordPart recoit '1' ou '2'. Imaginons que vous procédiez comme ceci, vous avez dans votre liste de mots "carotte" et vous désirez que ce mot apparaisse en gras. Vous testez en tapant "carotte", tout marche bien, il s'affiche carotte. Mais si maintenant vous tappez "carotte1", vous verrez s'afficher carotte1 et non pas carotte1.
Vous devez donc créer pour votre langage (comme nous allons le faire pour l'assembleur) un détecteur adapté qui renvoie true lorsque isWordPart reçoit un identifiant valable en tant que partie de variable.
La deuxième subtilité est de passer un Token par défaut au constructeur de la WordRule. Ce Token contient dans notre cas un attribut de texte standard (texte noir sur fond blanc). Si vous ne le faites pas et que vous utilisez l'autre constructeur, vous pourriez avoir des surprises. En reprenant l'exemple précédent, si l'on ne spécifie pas de Token par défaut, une saisie du type "radiscarotte" (sans espace) s'affichera radiscarotte, ce qui n'est pas (forcément) souhaitable. Cela s'explique par le fait que par défaut, si aucun mot ne correspond, les caractères ne sont pas consommés par la règle qui passe la main à la suivante. Si aucune règle n'est déclenchée, en arrivant au c de carotte, la WordRule se déclenche et colore carotte. Tandis que si l'on précise un token par défaut, la WordRule va consommer tous les caractères jusqu'à la fin du mot et renvoyer le Token que l'on a spécifié.
Nous créons donc une WordRule qui utilise le même WordDetector pour les opcodes, les registres et les pseudoinstructions. Ces trois types d'entités sont colorées différemment, car c'est au moment de l'ajout du mot que l'on précise le Token renvoyé lors de sa détection. Malheureusement, l'implémentation de WordRule tient compte de la casse lors de la recherche d'un mot ce qui n'est pas le cas de l'assembleur.
L'ajout de mots se fait simplement en appelant la méthode addWord et en lui passant le mot ainsi que le Token à renvoyer lorsque ce mot est détecté.
Voici un extrait du code de l'ASMCodeScanner qui renseigne les différents mots :
/*
* Création de la règle pour les mots-clés. En deux temps :
* Tout d'abord on paramètre un détecteur qui va indiquer les
* caractères valides pour le début et le contenu d'un mot,
* puis on ajoute une liste de mots en indiquant quel token doit
* être renvoyé pour chacun.
*/
// Si le mot n'est pas dans la liste, renvoie undefined
WordRule wr = new WordRule(new ASMWordDetector(), undefined);
// Ajout des opcodes
for(int i = 0 ; i < fgOpcodes.length ; ++i) {
wr.addWord(fgOpcodes[i], opcode);
// Cas des majuscules
wr.addWord(fgOpcodes[i].toUpperCase(), opcode);
}
// Ajout des registres
for(int i = 0 ; i < fgRegisters.length ; ++i) {
wr.addWord(fgRegisters[i], register);
wr.addWord(fgRegisters[i].toUpperCase(), register);
}
// Ajout des pseudoInstructions
for(int i = 0 ; i < fgPseudoInsts.length ; ++i) {
wr.addWord(fgPseudoInsts[i], pseudoInst);
wr.addWord(fgPseudoInsts[i].toUpperCase(), pseudoInst);
}
// Ajout des macros prédéfinies
for(int i = 0 ; i < fgMacros.length ; ++i) {
wr.addWord(fgMacros[i], macro);
wr.addWord(fgMacros[i].toUpperCase(), macro);
}
rules.add(wr);rules est simplement une liste contenant toutes les règles qui seront appliquées, les champs commençant par fg sont des tableaux statics contenant les mots-clés. L'ASMWordDetector se présente comme suit :
/**
* Détecteur de "mots" Assembleur (opcodes, registres, variables).
* cf. Manuel NASM, p.31
* @author Sébastien Le Ray
*/
static class ASMWordDetector implements IWordDetector {
/**
* Indique si le caractère passé en paramètre est valide à
* l'intérieur d'un mot.
* @param character Caractère à analyser.
* @return true si le caractère est valide.
* false sinon.
* @see org.eclipse.jface.text.rules.IWordDetector#isWordPart(char)
*/
public boolean isWordPart(char c) {
return (Character.isLetterOrDigit(c) ||
c == '_' ||
c == '$' ||
c == '#' ||
c == '@' ||
c == '~' ||
c == '.' ||
c == '?');
}
/**
* Indique si le caractère passé en paramètre est valide au
* début d'un mot.
* @param character Caractère à analyser.
* @return true si le caractère est valide.
* false sinon.
* @see org.eclipse.jface.text.rules.IWordDetector#isWordStart(char)
*/
public boolean isWordStart(char c) {
return (Character.isLetter(c) ||
c == '.' ||
c == '_' ||
c == '?' ||
c == '$');
}
}V-B-1-c. Détection de catégories de mots▲
Dans notre cas, la détection d'une catégorie de mots est utilisée pour les directives du préprocesseur NASM qui commencent par le symbole '%'. On crée donc un WordDetector qui ne prend en compte que les mots commençant par % (c'est-à-dire que isWordStart ne renvoie true que dans ce cas).
La création de la WordRule se fait simplement en lui passant notre WordDetector et le Token contenant l'attribut de texte à appliquer aux mots reconnus :
// Règle détectant les directives préprocesseur (commençant par %)
rules.add(new WordRule(new PreprocessorWordDetector(), directive));V-B-2. Autres règles▲
V-B-2-a. Règles standards▲
Les autres règles standards utilisées ont déjà été vues lors de la mise en place du partitionnement. Notez que l'on retrouve une règle pour les chaînes de caractères qui suit la même définition que dans le partitionnement, mais renvoie un Token contenant l'attribut à appliquer (souvenez-vous, nous avions fait en sorte que les chaînes soient traitées comme le code assembleur).
En ce qui concerne les directives de l'Assembleur (pas du préprocesseur), il faut prendre en compte deux types de directives :
- les directives dites utilisateur qui sont de la forme DIRECTIVE VALEUR ;
- les directives dites primitives qui sont de la forme [DIRECTIVE VALEUR].
On pourrait penser que pour les directives primitives, on peut utiliser une SingleLineRule qui débuterait sur le caractère [ et finirait sur le caractère ]. Le problème c'est que NASM utilise également cette notation pour les adresses effectives, qui n'ont rien à voir avec les directives. Aussi, on utilisera des SingleLineRule qui commencent par [DIRECTIVE et finissent par ]. Pour les directives utilisateur il n'est pas possible d'utiliser des WordRule, car les mots contiennent des espaces et les valeurs des directives ne sont pas connues. Nous allons donc contourner le problème en utilisant des EndOfLineRule qui commencent sur DIRECTIVE. De cette façon, nous couvrons tous les cas possibles.
Nous ajoutons ensuite la règle concernant les adresses effectives qui est une SingleLineRule commençant sur [ et finissant sur ]. Voilà un exemple où l'ordre est important, si l'on met la détection des adresses effectives avant celle des directives, aucune directive n'est détectée puisque les conditions des adresses effectives englobent celles des directives.
Pour consommer les espaces et les tabulations, on utilise une WhiteSpaceRule. On fournit à celle-ci une classe implémentant org.eclipse.jface.text.rules.IWhitespaceDetector.IWordSpaceDetector. L'interface ne définit qu'une seule méthode : isWhiteSpace(char c) qui doit renvoyer true si le caractère passé en paramètre est considéré comme un espace, false sinon.
V-B-2-b. Règles personnalisées▲
Pour la détection de certains modèles particuliers, il peut être nécessaire de développer ses propres règles en implémentant l'interface org.eclipse.jface.text.rules.IRule;. Celle-ci ne définit qu'une seule méthode : evaluate(CharacterScanner scanner). La règle va consommer les caractères du CharacterScanner pour déterminer si ses critères sont remplis ou non. La consommation se fait caractère par caractère. Si la règle n'est pas satisfaite, il faut bien faire attention à rembobiner le CharacterScanner en appelant sa méthode unread() autant de fois que nécessaire (une fois par caractère) afin de permettre aux autres règles d'analyser le flux.
Cette méthode a été utilisée pour les règles de détection des nombres hexadécimaux, octaux, binaires et à virgule flottante. Une règle pour les nombres classiques est fournie avec Eclipse (NumberRule). La présentation dans le détail de ces règles ne semble pas utile, reportez-vous au code contenu dans le zip pour plus de détails.
Là encore, l'ordre d'ajout des règles est important. Si l'on met la NumberRule en premier, celle-ci va consommer tous les chiffres, empêchant les autres règles de fonctionner.
V-B-3. Règles non utilisées▲
Il existe d'autres règles fournies en standard avec Eclipse qui n'ont pas été utilisées ici, mais qui peuvent être utiles. Elles se trouvent toutes dans le package org.eclipse.jface.text.rules. En voici une présentation rapide.
V-B-3-a. PatternRule▲
La classe PatternRule est la classe mère de la plupart des autres règles offertes par Eclipse. En effet, ses sous-classes se contentent d'appeler son constructeur avec les paramètres appropriés.
Normalement, vous ne devriez pas avoir à vous servir de cette classe, utilisez les sous-classes spécialisées appropriées.
Une PatternRule est définie par une séquence de début, une séquence de fin, un caractère d'échappement et une indication sur son achèvement avec la ligne. Il est également possible de préciser si la règle se termine correctement avec la fin de fichier et si le caractère d'échappement peut être utilisé pour répartir la règle sur plusieurs lignes.
V-B-3-b. MultiLineRule▲
La classe MultiLineRule permet comme son nom l'indique de définir une règle qui va s'étendre sur plusieurs lignes. Elle est plus utile au niveau des partitions (par exemple pour les commentaires multilignes). Elle est définie par une séquence de début et une séquence de fin, il est possible de préciser un caractère d'échappement et d'indiquer si la fin de fichier remplit la règle ou non.
V-B-3-c. WordPatternRule▲
La WordPatternRule permet de détecter des mots qui commencent par une séquence donnée et finissent par une autre. Les caractères valides en tant que partie d'un mot sont détectés par un WordDetector.
V-C. Mise en place de la SourceViewerConfiguration▲
Maintenant que les mécanismes utilisés pour la coloration syntaxique sont prêts, il faut comme d'habitude faire le lien avec Eclipse. Si vous vous souvenez du début de ce tutoriel, c'est au niveau de la SourceViewerConfiguration que cela s'effectue.
Comme pour le partitioner, nous créons un getter pour l'ASMCodeScanner dans la classe du plug-in afin de réutiliser la même instance.
Créez une classe nommée ASMSourceViewerConfiguration qui étend SourceViewerConfiguration. Les méthodes getConfiguredDocumentPartitioning et getConfiguredContentTypes renvoient toutes deux des constantes définies soit dans le plug-in soit dans partitioner. Notez que l'on trouve IDocument.DEFAULT_CONTENT_TYPE dans le tableau renvoyé par la seconde méthode, il s'agit du type de contenu renvoyé lorsqu'aucune règle particulière n'est définie dans le partitioner (ce qui est le cas pour le code assembleur dans notre exemple).
Comme les commentaires sont colorés de façon uniforme, nous allons créer un scanner qui renvoie toujours le même Token (il s'agit d'une classe interne à notre SourceViewerConfiguration) :
/**
* Classe utilisée lorsque l'on ne désire pas affiner la coloration syntaxique
* (ie. toute la partition de la même couleur). Utilisée pour les partitions
* de commentaires.
*/
static class SingleTokenScanner extends BufferedRuleBasedScanner {
/**
* Constructeur. Définit le token renvoyé.
* @param attribute Attribut du Token.
*/
public SingleTokenScanner(TextAttribute attribute) {
setDefaultReturnToken(new Token(attribute));
}
}Nous disposons maintenant de tout ce qu'il faut pour la coloration syntaxique. Nous allons donc redéfinir la méthode getPresentationReconciler de la classe mère SourceViewerConfiguration. Celle-ci crée un nouveau PresentationReconciler qui est l'implémentation de référence fournie par Eclipse pour l'interface org.eclipse.jface.text.presentation.IPresentationReconciler.
Nous utilisons ensuite un DefaultDamagerRepairer pour gérer les changements apportés au document. Lors de la création de l'entité, on spécifie un ITokenScanner (dont le RuleBasedScanner, et donc l'ASMCodeScanner, est une sous-classe) qui analyse le texte. Enfin, on indique au Reconciler qu'il doit utiliser le DefaultDamagerRepairer en tant que Damager et en tant que Repairer pour un certain type de partition.
Enfin, lorsqu'on a attribué un scanner à chaque type de partition on renvoie le reconciler. Voici le code complet de la méthode.
/**
* Met en place la coloration syntaxique.
* Attribue des damagers et des repairers à chaque type de partition.
* @param sourceViewer SourceViewer pour lequel on configure le reconciler.
* @return Le reconciler à utiliser avec les damagers et les repairers configurés.
* @see org.eclipse.jface.text.source.SourceViewerConfiguration#getPresentationReconciler
*/
public IPresentationReconciler getPresentationReconciler(ISourceViewer sourceViewer) {
ASMTextAttributeProvider provider= ASMEditorPlugin.getDefault().getTextAttributeProvider();
PresentationReconciler reconciler= new PresentationReconciler();
reconciler.setDocumentPartitioning(getConfiguredDocumentPartitioning(sourceViewer));
// Crée le damager/repairer pour le code
DefaultDamagerRepairer dr = new DefaultDamagerRepairer(ASMEditorPlugin.getDefault().getASMCodeScanner());
reconciler.setDamager(dr, IDocument.DEFAULT_CONTENT_TYPE);
reconciler.setRepairer(dr, IDocument.DEFAULT_CONTENT_TYPE);
// Crée le damager/repairer pour les commentaires
dr= new DefaultDamagerRepairer(
new SingleTokenScanner(provider.getAttribute(ASMTextAttributeProvider.COMMENT_ATTRIBUTE))
);
reconciler.setDamager(dr, ASMPartitionScanner.ASM_COMMENT);
reconciler.setRepairer(dr, ASMPartitionScanner.ASM_COMMENT);
return reconciler;
}VI. Conclusion▲
Voilà, j'espère que vous avez saisi la majorité des concepts exposés ici. Vous pouvez obtenir la totalité du projet Eclipse pour en décortiquer le code au bas de cette page. Ce chapitre est très long alors, essayez d'apporter des modifications pour voir l'impact sur la coloration. Si certaines parties ne sont pas claires, faites-le-moi savoir, j'apporterai les corrections nécessaires.
La série des tutoriels Eclipse va s'interrompre le temps d'en commencer une autre traitant des API commons du projet Jakarta. La prochaine partie devrait être consacrée à la complétion automatique.
VII. Remerciements▲
Merci à vedaer pour sa relecture et ses conseils. Merci à Bestiol pour ses corrections.
VIII. Téléchargements & Liens▲
- L'article au format HTML zippé ;
- L'article au format PDF ;
- Le projet Eclipse correspondant ;
- Le plug-in au format ZIP (à extraire dans le répertoire racine d'Eclipse) ;
- Le site de Bosokernel (d'où est extrait le code assembleur présenté dans l'exemple).
| Articles sur la création de plug-in Eclipse : |
| Création d'un éditeur |
| Mise en place de la coloration syntaxique |
