I. PrĂŠface▲
I-A. Objectif▲
L'objectif de ce livre est de permettre au lecteur de mieux comprendre comment les ordinateurs fonctionnent rÊellement à un niveau plus bas que les langages de programmation comme Pascal. En ayant une comprÊhension plus profonde de la façon dont fonctionnent les ordinateurs, le lecteur peut devenir plus productif dans le dÊveloppement de logiciels dans des langages de plus haut niveau comme le C et le C++.
Apprendre Ă programmer en assembleur est un excellent moyen d'atteindre ce but. Les autres livres d'assembleur pour PC apprennent toujours Ă programmer le processeur 8086 qu'utilisait le PC originel de 1981 ! Le processeur 8086 ne supportait que le mode rĂŠel.
Dans ce mode, tout programme peut adresser n'importe quel endroit de la mÊmoire ou n'importe quel pÊriphÊrique de l'ordinateur. Ce mode n'est pas utilisable pour un système d'exploitation sÊcurisÊ et multitâche. Ce livre parle plutôt de la façon de programmer les processeurs 80386 et plus rÊcents en mode protÊgÊ (le mode dans lequel fonctionnent Windows et Linux). Ce mode supporte les fonctionnalitÊs que les systèmes d'exploitation modernes offrent, comme la mÊmoire virtuelle et la protection mÊmoire. Il y a plusieurs raisons d'utiliser le mode protÊgÊ :
1. Il est plus facile de programmer en mode protĂŠgĂŠ qu'en mode rĂŠel 8086 que les autres livres utilisent ;
2. Tous les systèmes d'exploitation PC modernes fonctionnent en mode protÊgÊ ;
3. Il y a des logiciels libres disponibles qui fonctionnent dans ce mode.
Le manque de livres sur la programmation en assembleur PC en mode protĂŠgĂŠ est la principale raison qui a conduit l'auteur Ă ĂŠcrire ce livre.
Comme nous y avons fait allusion ci-dessus, ce texte utilise des logiciels Libres/Open Source : l'assembleur NASM et le compilateur C/C++ DJGPP. Les deux sont disponibles en tĂŠlĂŠchargement sur Internet. Ce texte parle ĂŠgalement de l'utilisation de code assembleur NASM sous Linux et avec les compilateurs C/C++ de Borland et Microsoft sous Windows. Les exemples pour toutes ces plateformes sont disponibles sur mon site Web : http://www.drpaulcarter.com/pcasm.
Vous devez tĂŠlĂŠcharger le code exemple si vous voulez assembler et exĂŠcuter la plupart des exemples de ce tutoriel.
Soyez conscient que ce texte ne tente pas de couvrir tous les aspects de la programmation assembleur. L'auteur a essayĂŠ de couvrir les sujets les plus importants avec lesquels tous les programmeurs devraient ĂŞtre familiers.
I-B. Remerciements▲
L'auteur voudrait remercier les nombreux programmeurs qui ont contribuĂŠ au mouvement Libre/Open Source. Tous les programmes et mĂŞme ce livre lui-mĂŞme ont ĂŠtĂŠ crĂŠĂŠs avec des logiciels gratuits. L'auteur voudrait remercier en particulier John S. Fine, Simon Tatham, Julian Hall et les autres dĂŠveloppeurs de l'assembleur NASM sur lequel tous les exemples de ce livre sont basĂŠs ; DJ Delorie pour le dĂŠveloppement du compilateur C/C++ DJGPP utilisĂŠ ; les nombreuses personnes qui ont contribuĂŠ au compilateur GNU gcc sur lequel DJGPP est basĂŠ ; Donald Knuth et les autres pour avoir dĂŠveloppĂŠ les langages composition TEX et LATEX2" qui ont ĂŠtĂŠ utilisĂŠs pour produire le livre ; Richard Stallman (fondateur de la Free Software Foundation), Linus Torvalds (crĂŠateur du noyau Linux) et les autres qui ont crĂŠĂŠ les logiciels sous-jacents utilisĂŠs pour ce travail.
Merci aux personnes suivantes pour leurs corrections :
John S. Fine ; Marcelo Henrique Pinto de Almeida ; Sam Hopkins ; Nick D'Imperio ; Jeremiah Lawrence ; Ed Beroset ; Jerry Gembarowski ; Ziqiang Peng ; Eno Compton ; Josh I Cates ; Mik Miin ; Luke Wallis ; Gaku Ueda ; Brian Heward ; Chad Gorshing ; F. Gotti ; Bob Wilkinson ; Markus Koegel ;Louis Taber.
I-C. Ressources sur Internet▲
Page de l'auteur : http://www.drpaulcarter.com/.
Page NASM sur SourceForge : http://sourceforge.net/projects/nasm/.
DJGPP : http://www.delorie.com/djgpp.
Assembleur Linux : http://www.linuxassembly.org/.
The Art of Assembly : http://webster.cs.ucr.edu/.
USENET comp.lang.asm.x86
Documentation Intel : http://developer.intel.com/design/Pentium4/documentation.htm.
I-D. RĂŠactions▲
L'auteur accepte toute rĂŠaction sur ce travail.
E-mail : pacman128@gmail.com.
WWW : http://www.drpaulcarter.com/pcasm
II. Introduction▲
II-A. Systèmes numĂŠriques▲
La mÊmoire d'un ordinateur est constituÊe de nombres. Cette mÊmoire ne stocke pas ces nombres en dÊcimal (base 10). Comme cela simplifie grandement le matÊriel, les ordinateurs stockent toutes les informations au format binaire (base 2). Tout d'abord, revoyons ensemble le système dÊcimal.
II-A-1. DĂŠcimal▲
Les nombres en base 10 sont constituĂŠs de 10 chiffres possibles (0-9).
Chaque chiffre d'un nombre est associĂŠ Ă une puissance de 10 selon sa position dans le nombre. Par exemple :
234 = 2 x 102 + 3 Ă 101 + 4 Ă 100
II-A-2. Binaire▲
Les nombres en base 2 sont composĂŠs de deux chiffres possibles (0 et 1). Chaque chiffre est associĂŠ Ă une puissance de 2 selon sa position dans le nombre (un chiffre binaire isolĂŠ est appelĂŠ bit). Par exemple :
110012 = 1 Ă 24+ 1 Ă 23 + 0 Ă 22 + 0 Ă 21 + 1 Ă 20
= 16 + 8 + 1
= 25
Cet exemple montre comment passer du binaire au dĂŠcimal. Le tableau 1.1 montre la reprĂŠsentation binaire des premiers nombres.
La figure 1.1 montre comment des chiffres binaires individuels (i.e., des bits) sont additionnĂŠs. Voici un exemple :

Si l'on considère la division dÊcimale suivante :
1234 á 10 = 123 r 4
on peut voir que cette division sĂŠpare le chiffre le plus Ă droite du nombre et dĂŠcale les autres chiffres d'une position vers la droite. Diviser par deux effectue une opĂŠration similaire, mais pour les chiffres binaires du nombre.
ConsidĂŠrons la division binaire suivante(1) :
11012 á 102 = 1102 r 1
Cette propriĂŠtĂŠ peut ĂŞtre utilisĂŠe pour convertir un nombre dĂŠcimal en son ĂŠquivalent binaire comme le montre la Figure 1.2. Cette mĂŠthode trouve le chiffre binaire le plus Ă droite en premier, ce chiffre est appelĂŠ le bit le moins signicatif (lsb, least signicant bit). Le chiffre le plus Ă gauche est appelĂŠ le bit le plus signicatif (msb, most signicant bit). L'unitĂŠ de base de la mĂŠmoire consiste en un jeu de 8 bits appelĂŠ octet (byte).

II-A-3. HexadĂŠcimal▲
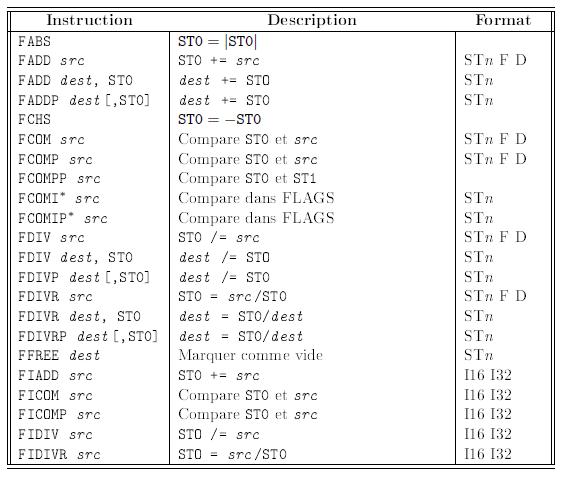
Les nombres hexadÊcimaux utilisent la base 16. L'hexadÊcimal (ou hexa en abrÊgÊ) peut être utilisÊ comme notation pour les nombres binaires. L'hexa a 16 chiffres possibles. Cela pose un problème, car il n'y a pas de symbole à utiliser pour les chiffres supplÊmentaires après 9. Par convention, on utilise des lettres pour les reprÊsenter. Les 16 chiffres de l'hexa sont 0-9 puis A, B, C, D, E et F. Le chiffre A Êquivaut à 10 en dÊcimal, B à 11, etc. Chaque chiffre d'un nombre en hexa est associÊ à une puissance de 16. Par exemple :
2BD16 = 2 Ă 162 + 11 Ă 161 + 13 Ă 160
= 512 + 176 + 13
= 701
Pour convertir un nombre hexa en binaire, convertissez simplement chaque chiffre hexa en un nombre binaire de 4 bits. Par exemple, 24D16 est converti en 0010 0100 11012. Notez que les 0 de tĂŞte des 4 bits sont importants ! Si le 0 de tĂŞte pour le chiffre du milieu de 24D16 n'est pas utilisĂŠ, le rĂŠsultat est faux. La conversion du binaire vers l'hexa est aussi simple. On effectue la mĂŞme chose, dans l'autre sens. Convertissez chaque segment de 4 bits du binaire vers l'hexa. Commencez Ă droite, pas Ă gauche, du nombre binaire.
Cela permet de s'assurer que le procĂŠdĂŠ utilise les segments de 4 bits corrects(2)
Exemple :
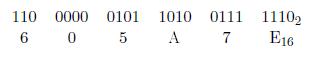
Un nombre de 4 bits est appelĂŠ quadruplet(nibble). Donc, chaque chiffre hexa correspond Ă un quadruplet. Deux quadruplets forment un octet et donc un octet peut ĂŞtre reprĂŠsentĂŠ par un nombre hexa Ă deux chiffres. La valeur d'un bit va de 0 Ă 11111111 en binaire, 0 Ă FF en hexa et 0 Ă 255 en dĂŠcimal.
II-B. Organisation de l'ordinateur▲
II-B-1. MĂŠmoire▲
La mĂŠmoire est mesurĂŠe en kilo-octets ( 210= 1024 octets), mega octets (220= 1 048 576 octets) et gigaoctets (230 = 1 073 741 824 octets).
L'unitĂŠ mĂŠmoire de base est l'octet. Un ordinateur avec 32 mĂŠgaoctets de mĂŠmoire peut stocker jusqu'Ă environ 32 millions d'octets d'informations.
Chaque octet en mĂŠmoire est ĂŠtiquetĂŠ par un nombre unique appelĂŠ son adresse comme le montre la Figure 1.4.

Souvent, la mĂŠmoire est utilisĂŠe par bouts plus grands que des octets isolĂŠs. Sur l'architecture PC, on a donnĂŠ des noms Ă ces portions de mĂŠmoire plus grandes, comme le montre le Tableau 1.2.

Toutes les donnĂŠes en mĂŠmoire sont numĂŠriques. Les caractères sont stockĂŠs en utilisant un code caractère qui fait correspondre des nombres aux caractères. Un des codes caractère les plus connus est appelĂŠ ASCII (American Standard Code for Information Interchange, Code AmĂŠricain Standard pour l'Ăchange d'Informations). Un nouveau code, plus complet, qui supplante l'ASCII est l'Unicode. Une des diffĂŠrences-clĂŠs entre les deux codes est que l'ASCII utilise un octet pour encoder un caractère alors que l'Unicode en utilise deux (ou un mot). Par exemple, l'ASCII fait correspondre l'octet 4116 (6510) au caractère majuscule A ; l'Unicode y fait correspondre le mot 004116. Comme l'ASCII n'utilise qu'un octet, il est limitĂŠ Ă 256 caractères diffĂŠrents au maximum(3). L'Unicode ĂŠtend les valeurs ASCII Ă des mots et permet de reprĂŠsenter beaucoup plus de caractères. C'est important afin de reprĂŠsenter les caractères de tous les langages du monde.
II-B-2. Le CPU (processeur)▲
Le processeur (CPU, Central Processing Unit) est le dispositif physique qui exÊcute les instructions. Les instructions que les processeurs peuvent exÊcuter sont gÊnÊralement très simples. Elles peuvent nÊcessiter que les donnÊes sur lesquelles elles agissent soient prÊsentes dans des emplacements de stockage spÊciques dans le processeur lui-même appelÊs registres. Le processeur peut accÊder aux donnÊes dans les registres plus rapidement qu'aux donnÊes en mÊmoire. Cependant, le nombre de registres d'un processeur est limitÊ, donc le programmeur doit faire attention à n'y conserver que les donnÊes actuellement utilisÊes.
Les instructions que peut exÊcuter un type de processeur constituent le langage machine. Les programmes machine ont une structure beaucoup plus basique que les langages de plus haut niveau. Les instructions du langage machine sont encodÊes en nombres bruts, pas en format texte lisible. Un processeur doit être capable de dÊcoder les instructions très rapidement pour fonctionner efficacement. Le langage machine est conçu avec ce but en tête, pas pour être facilement dÊchiffrable par les humains. Les programmes Êcrits dans d'autres langages doivent être convertis dans le langage machine programme qui traduit les programmes Êcrits dans un langage de programmation en langage machine d'une architecture d'ordinateur particulière. En gÊnÊral, chaque type de processeur a son propre langage machine unique. C'est une des raisons pour lesquelles un programme Êcrit pour Mac ne peut pas être exÊcutÊ sur un PC.
Les ordinateurs utilisent une horloge pour synchroniser l'exĂŠcution des instructions. L'horloge tourne Ă une frĂŠquence fixĂŠe (appelĂŠe vitesse d'horloge). Lorsque vous achetez un ordinateur Ă 1,5GHz, 1,5GHz est la frĂŠquence de cette horloge.
GHz signifie gigahertz ou un milliard de cycles par seconde. Un processeur Ă 1,5GHz a 1,5 milliard d'impulsions horloge par seconde.
L'horloge ne dÊcompte pas les minutes et les secondes. Elle bat simplement à un rythme constant. Les composants Êlectroniques du processeur utilisent les pulsations pour effectuer leurs opÊrations correctement, comme le battement d'un mÊtronome aide à jouer de la musique à un rythme correct. Le nombre de battements (ou, comme on les appelle couramment cycles) que requiert une instruction dÊpend du modèle et de la gÊnÊration du processeur. Le nombre de cycles dÊpend de l'instruction.
II-B-3. La famille des processeurs 80x86▲
Les PC contiennent un processeur de la famille des Intel 80x86 (ou un clone). Les processeurs de cette famille ont tous des fonctionnalitĂŠs en commun, y compris un langage machine de base. Cependant, les membres les plus rĂŠcents amĂŠliorent grandement les fonctionnalitĂŠs.
8088,8086 : ces processeurs, du point de vue de la programmation sont identiques. Ils Êtaient les processeurs utilisÊs dans les tout premiers PC. Ils offrent plusieurs registres 16 bits : AX, BX, CX, DX, SI, DI, BP, SP, CS, DS, SS, ES, IP, FLAGS. Ils ne supportent que jusqu'à 1Mo de mÊmoire et n'opèrent qu'en mode rÊel. Dans ce mode, un programme peut accÊder à n'importe quelle adresse mÊmoire, même la mÊmoire des autres programmes ! Cela rend le dÊbogage et la sÊcuritÊ très difficiles ! De plus, la mÊmoire du programme doit être divisÊe en segments. Chaque segment ne peut pas dÊpasser les 64 Ko.
80286 : ce processeur ĂŠtait utilisĂŠ dans les PC de type AT. Il apporte quelques nouvelles instructions au langage machine de base des 8088/86. Cependant, sa principale nouvelle fonctionnalitĂŠ est le mode protĂŠgĂŠ 16 bits. Dans ce mode, il peut accĂŠder jusqu'Ă 16 Mo de mĂŠmoire et empĂŞcher les programmes d'accĂŠder Ă la mĂŠmoire des uns et des autres. Cependant, les programmes sont toujours divisĂŠs en segments qui ne peuvent pas dĂŠpasser les 64 Ko.
80386 : ce processeur a grandement amĂŠliorĂŠ le 80286. Tout d'abord, il ĂŠtend la plupart des registres Ă 32 bits (EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP, EIP) et ajoute deux nouveaux registres 16 bits : FS et GS.

Il ajoute ĂŠgalement un nouveau mode protĂŠgĂŠ 32 bits. Dans ce mode, il peut accĂŠder jusqu'Ă 4 Go de mĂŠmoire. Les programmes sont encore divisĂŠs en segments, mais maintenant chaque segment peut ĂŠgalement faire jusqu'Ă 4 Go !
80486/Pentium/Pentium Pro : ces membres de la famille 80x86 apportent très peu de nouvelles fonctionnalitÊs. Ils accÊlèrent principalement l'exÊcution des instructions.
Pentium MMX : ce processeur ajoute les instructions MMX (Multi Media eXentions) au Pentium. Ces instructions peuvent accĂŠlĂŠrer des opĂŠrations graphiques courantes.
Pentium II : c'est un processeur Pentium Pro avec les instructions MMX (le Pentium III est grossièrement un Pentium II plus rapide).
II-B-4. Regitres 16 bits du 8086▲
Le processeur 8086 original fournissait quatre registres gĂŠnĂŠraux de 16 bits : AX, BX, CX et DX. Chacun de ces registres peut ĂŞtre dĂŠcomposĂŠ en deux registres de 8 bits. Par exemple, le registre AX pouvait ĂŞtre dĂŠcomposĂŠ en AH et AL comme le montre la Figure 1.5. Le registre AH contient les 8 bits de poids fort de AX et AL contient les 8 bits de poids faible. Souvent, AH et AL sont utilisĂŠs comme des registres d'un octet indĂŠpendants ; cependant, il est important de rĂŠaliser qu'ils ne sont pas indĂŠpendants de AX. Changer la valeur de AX changera les valeurs de AL et BL et vice versa. Les registres gĂŠnĂŠraux sont utilisĂŠs dans beaucoup de dĂŠplacements de donnĂŠes et instructions arithmĂŠtiques.
Il y a deux registres d'index de 16 bits : SI et DI. Ils sont souvent utilisĂŠs comme des pointeurs, mais peuvent ĂŞtre utilisĂŠs pour la plupart des mĂŞmes choses que les registres gĂŠnĂŠraux. Cependant, ils ne peuvent pas ĂŞtre dĂŠcomposĂŠs en registres de 8 bits.
Les registres 16 bits BP et SP sont utilisĂŠs pour pointer sur des donnĂŠes dans la pile du langage machine et sont appelĂŠs le pointeur de base et le pointeur de pile, respectivement. Nous en reparlerons plus tard.
Les registres 16 bits CS, DS, SS et ES sont des registres de segment. Ils indiquent quelle zone de la mĂŠmoire est utilisĂŠe pour les diffĂŠrentes parties d'un programme. CS signifie Code Segment, DS Data Segment, SS Stack Segment (segment de pile) et ES Extra Segment. ES est utilisĂŠ en tant que registre de segment temporaire. Des dĂŠtails sur ces registres se trouvent dans les sections II.B.6 et II.B.7.
Le registre de pointeur d'instruction (IP) est utilisĂŠ avec le registre CS pour mĂŠmoriser l'adresse de la prochaine instruction Ă exĂŠcuter par le processeur.
Normalement, lorsqu'une instruction est exĂŠcutĂŠe, IP est incrĂŠmentĂŠ pour pointer vers la prochaine instruction en mĂŠmoire.
Le registre FLAGS stocke des informations importantes sur les rĂŠsultats d'une instruction prĂŠcĂŠdente. Ces rĂŠsultats sont stockĂŠs comme des bits individuels dans le registre. Par exemple, le bit Z est positionnĂŠ Ă 1 si le rĂŠsultat de l'instruction prĂŠcĂŠdente ĂŠtait 0 ou Ă 0 sinon. Toutes les instructions ne modifient pas les bits dans FLAGS, consultez le tableau dans l'appendice pour voir comment chaque instruction affecte le registre FLAGS.
II-B-5. Registres 32 bits du 80386▲
Les processeurs 80386 et plus rĂŠcents ont des registres ĂŠtendus. Par exemple le registre AX 16 bits est ĂŠtendu Ă 32 bits. Pour la compatibilitĂŠ ascendante, AX fait toujours rĂŠfĂŠrence au registre 16 bits et on utilise EAX pour faire rĂŠfĂŠrence au registre 32 bits. AX reprĂŠsente les 16 bits de poids faible de EAX tout comme AL reprĂŠsente les 8 bits de poids faible de AX (et de EAX). Il n'y a pas moyen d'accĂŠder aux 16 bits de poids fort de EAX directement. Les autres registres ĂŠtendus sont EBX, ECX, EDX, ESI et EDI.
La plupart des autres registres sont ĂŠgalement ĂŠtendus. BP devient EBP ; SP devient ESP ; FLAGS devient EFLAGS et IP devient EIP. Cependant, contrairement aux registres gĂŠnĂŠraux et d'index, en mode protĂŠgĂŠ 32 bits (dont nous parlons plus loin) seules les versions ĂŠtendues de ces registres sont utilisĂŠes.
Les registres de segment sont toujours sur 16 bits dans le 80386. Il y a Êgalement deux registres de segment supplÊmentaires : FS et GS. Leurs noms n'ont pas de signification particulière. Ce sont des segments temporaires supplÊmentaires (comme ES).
Une des dÊfinitions du terme mot se rÊfère à la taille des registres de donnÊes du processeur. Pour la famille du 80x86, le terme est dÊsormais un peu confus. Dans le Tableau 1.2, on voit que le terme mot est dÊni comme faisant 2 octets (ou 16 bits). Cette signification lui a ÊtÊ attribuÊe lorsque le premier 8086 est apparu. Lorsque le 80386 a ÊtÊ dÊveloppÊ, il a ÊtÊ dÊcidÊ de laisser la dÊfinition de mot inchangÊe, même si la taille des registres avait changÊ.
II-B-6. Mode rĂŠel▲
En mode rĂŠel, la mĂŠmoire est limitĂŠe Ă seulement un mĂŠgaoctet (220 octets).
Alors d'oÚ vient l'infâme limite des 640 Ko du DOS ? Le BIOS requiert une partie des 1 Mo pour son propre code et pour les pÊriphÊriques matÊriels comme l'Êcran.
Les adresses valides vont de 00000 à FFFFF (en hexa). Ces adresses nÊcessitent un nombre sur 20 bits. Cependant, un nombre de 20 bits ne tiendrait dans aucun des registres 16 bits du 8086. Intel a rÊsolu le problème, en utilisant deux valeurs de 16 bits pour dÊterminer une adresse. La première valeur de 16 bits est appelÊe le sÊlecteur. Les valeurs du sÊlecteur doivent être stockÊes dans des registres de segment. La seconde valeur de 16 bits est appelÊe le dÊplacement (offset). L'adresse physique identifiÊe par un couple sÊlecteur/dÊplacement 32 bits est calculÊe par la formule
16 * sĂŠlecteur + dĂŠplacement
Multiplier par 16 en hexa est facile, il suffit d'ajouter un 0 à la droite du nombre. Par exemple, l'adresse physique rÊfÊrencÊe par 047C:0048 est obtenue de la façon suivante :
047C0
+0048
04808
De fait, la valeur du sĂŠlecteur est un numĂŠro de paragraphe (voir Tableau 1.2).
Les adresses rĂŠelles segmentĂŠes ont des inconvĂŠnients :
- une seule valeur de sÊlecteur peut seulement rÊfÊrencer 64Ko de mÊmoire (la limite supÊrieure d'un dÊplacement de 16 bits). Que se passe-t-il si un programme a plus de 64 Ko de code ? Une seule valeur de CS ne peut pas être utilisÊe pour toute l'exÊcution du programme. Le programme doit être divisÊ en sections (appelÊes segments) de moins de 64 Ko. Lorsque l'exÊcution passe d'un segment à l'autre, la valeur de CS doit être changÊe. Des problèmes similaires surviennent avec de grandes quantitÊs de donnÊes et le registre DS. Cela peut être très gênant ! ;
- chaque octet en mĂŠmoire n'a pas une adresse segmentĂŠe unique. L'adresse physique 04808 peut ĂŞtre rĂŠfĂŠrencĂŠe par 047C:0048, 047D:0038, 047E:0028 ou 047B:0058. Cela complique la comparaison d'adresses segmentĂŠes.
II-B-7. Mode protĂŠgĂŠ 16 bits▲
Dans le mode protÊgÊ 16 bits du 80286, les valeurs du sÊlecteur sont interprÊtÊes de façon totalement diffÊrente par rapport au mode rÊel. En mode rÊel, la valeur d'un sÊlecteur est un numÊro de paragraphe en mÊmoire.
En mode protĂŠgĂŠ, un sĂŠlecteur est un indice dans un tableau de descripteurs. Dans les deux modes, les programmes sont divisĂŠs en segments. En mode rĂŠel, ces segments sont Ă des positions fixes en mĂŠmoire et le sĂŠlecteur indique le numĂŠro de paragraphe auquel commence le segment. En mode protĂŠgĂŠ, les segments ne sont pas Ă des positions fixes en mĂŠmoire physique. De fait, ils n'ont mĂŞme pas besoin d'ĂŞtre en mĂŠmoire du tout !
Le mode protÊgÊ utilise une technique appelÊe mÊmoire virtuelle. L'idÊe de base d'un système de mÊmoire virtuelle est de ne garder en mÊmoire que les programmes et les donnÊes actuellement utilisÊs. Le reste des donnÊes et du code sont stockÊs temporairement sur le disque jusqu'à ce qu'on ait à nouveau besoin d'eux. Dans le mode protÊgÊ 16 bits, les segments sont dÊplacÊs entre la mÊmoire et le disque selon les besoins. Lorsqu'un segment est rechargÊ en mÊmoire depuis le disque, il est très probable qu'il sera à un endroit en mÊmoire diffÊrent de celui oÚ il Êtait avant d'être placÊ sur le disque.
Tout ceci est effectuÊ de façon transparente par le système d'exploitation. Le programme n'a pas à être Êcrit diffÊremment pour que la mÊmoire virtuelle fonctionne.
En mode protÊgÊ, chaque segment est assignÊ à une entrÊe dans un tableau de descripteurs. Cette entrÊe contient toutes les informations dont le système a besoin à propos du segment. Ces informations indiquent : s'il est actuellement en mÊmoire ; s'il est en mÊmoire, oÚ il se trouve ; les droits d'accès (p.e., lecture seule). L'indice de l'entrÊe du segment est la valeur du sÊlecteur stockÊe dans les registres de segment.
Un journaliste PC bien connu a baptisĂŠ le processeur 286 ÂŤ cerveau mort Âť (brain dead).
Un gros inconvĂŠnient du mode protĂŠgĂŠ 16 bits est que les dĂŠplacements sont toujours des quantitĂŠs sur 16 bits. En consĂŠquence, les tailles de segment sont toujours limitĂŠes au plus Ă 64 Ko. Cela rend l'utilisation de grands tableaux problĂŠmatique.
II-B-8. Mode protĂŠgĂŠ 32 bits▲
Le 80386 a introduit le mode protĂŠgĂŠ 32 bits. Il y a deux diffĂŠrences majeures entre les modes protĂŠgĂŠs 32 bits du 386 et 16 bits du 286 :
1. Les dĂŠplacements sont ĂŠtendus Ă 32 bits. Cela permet Ă un dĂŠplacement d'aller jusqu'Ă 4 milliards. Ainsi, les segments peuvent avoir des tailles jusqu'Ă 4 Go ;
2. Les segments peuvent être divisÊs en unitÊs plus petites de 4 Ko appelÊes pages. Le système de mÊmoire virtuelle fonctionne maintenant avec des pages plutôt qu'avec des segments. Cela implique que seules certaines parties d'un segment peuvent être prÊsentes en mÊmoire à un instant donnÊ. En mode 16 bits du 286, soit le segment en entier est en mÊmoire, soit rien n'y est. Ce qui n'aurait pas ÊtÊ pratique avec les segments plus grands que permet le mode 32 bits.
Dans Windows 3.x, le mode standard fait rĂŠfĂŠrence au mode protĂŠgĂŠ 16 bits du 286 et le mode amĂŠliorĂŠ (enhanced) fait rĂŠfĂŠrence au mode 32 bits.
Windows 9X, Windows NT/2000/XP, OS/2 et Linux fonctionnent tous en mode protĂŠgĂŠ 32 bits paginĂŠ.
II-B-9. Interruptions▲
Quelques fois, le flot ordinaire d'un programme doit être interrompu pour traiter des Êvènements qui requièrent une rÊponse rapide. Le matÊriel d'un ordinateur offre un mÊcanisme appelÊ interruptions pour gÊrer ces Êvènements.
Par exemple, lorsqu'une souris est dĂŠplacĂŠe, la souris interrompt le programme en cours pour gĂŠrer le dĂŠplacement de la souris (pour dĂŠplacer le curseur, etc.). Les interruptions provoquent le passage du contrĂ´le Ă un gestionnaire d'interruptions. Les gestionnaires d'interruptions sont des routines qui traitent une interruption. Chaque type d'interruption est assignĂŠe Ă un nombre entier. Au dĂŠbut de la mĂŠmoire physique, rĂŠside un tableau de vecteurs d'interruptions qui contient les adresses segmentĂŠes des gestionnaires d'interruptions. Le numĂŠro d'une interruption est essentiellement un indice dans ce tableau.
Les interruptions externes proviennent de l'extÊrieur du processeur (la souris est un exemple de ce type). Beaucoup de pÊriphÊriques d'E/S soulèvent des interruptions (p.e., le clavier, le timer, les lecteurs de disque, le CD-ROM et les cartes son). Les interruptions internes sont soulevÊes depuis le processeur, à cause d'une erreur ou d'une instruction d'interruption.
Les interruptions erreur sont Êgalement appelÊes traps. Les interruptions gÊnÊrÊes par l'instruction d'interruption sont Êgalement appelÊes interruptions logicielles. Le DOS utilise ce type d'interruption pour implÊmenter son API (Application Programming Interface). Les systèmes d'exploitation plus rÊcents (comme Windows et Unix) utilisent une interface basÊe sur C(4).
Beaucoup de gestionnaires d'interruptions redonnent le contrĂ´le au programme interrompu lorsqu'ils se terminent. Ils restaurent tous les registres aux valeurs qu'ils avaient avant l'interruption. Ainsi, le programme interrompu s'exĂŠcute comme si rien n'ĂŠtait arrivĂŠ (exceptĂŠ qu'il perd quelques cycles processeur). Les traps ne reviennent gĂŠnĂŠralement jamais. Souvent, elles arrĂŞtent le programme.
II-C. Langage assembleur▲
II-C-1. Langage machine▲
Chaque type de processeur comprend son propre langage machine. Les instructions dans le langage machine sont des nombres stockĂŠs sous la forme d'octets en mĂŠmoire. Chaque instruction a son propre code numĂŠrique unique appelĂŠ code d'opĂŠration ou opcode (operation code) en raccourci. Les instructions des processeurs 80x86 varient en taille. L'opcode est toujours au dĂŠbut de l'instruction. Beaucoup d'instructions comprennent ĂŠgalement les donnĂŠes (p.e. des constantes ou des adresses) utilisĂŠes par l'instruction.
Le langage machine est très difficile à programmer directement. DÊchiffrer la signification d'instructions codÊes numÊriquement est fatigant pour des humains. Par exemple, l'instruction qui dit d'ajouter les registres EAX et EBX et de stocker le rÊsultat dans EAX est encodÊe par les codes hexadÊcimaux suivants :
03 C3
C'est très peu clair. Heureusement, un programme appelÊ un assembleur peut faire ce travail laborieux à la place du programmeur.
II-C-2. Langage d'assembleur▲
Un programme en langage d'assembleur est stockĂŠ sous la forme de texte (comme un programme dans un langage de plus haut niveau). Chaque instruction assembleur reprĂŠsente exactement une instruction machine. Par exemple, l'instruction d'addition dĂŠcrite ci-dessus serait reprĂŠsentĂŠe en langage assembleur comme suit :
add eax, ebx
Ici, la signification de l'instruction est beaucoup plus claire qu'en code machine.
Le mot add est un mnĂŠmonique pour l'instruction d'addition. La forme gĂŠnĂŠrale d'une instruction assembleur est :
mnĂŠmonique opĂŠrande(s)
Un assembleur est un programme qui lit un fichier texte avec des instructions assembleur et convertit l'assembleur en code machine. Les compilateurs sont des programmes qui font des conversions similaires pour les langages de programmation de haut niveau. Un assembleur est beaucoup plus simple qu'un compilateur.
Cela a pris plusieurs annĂŠes aux scientifiques de l'informatique pour concevoir le simple fait d'ĂŠcrire un compilateur !
Chaque instruction du langage d'assembleur reprĂŠsente directement une instruction machine. Les instructions d'un langage de plus haut niveau sont beaucoup plus complexes et peuvent requĂŠrir beaucoup d'instructions machine.
Une autre diffĂŠrence importante entre l'assembleur et les langages de haut niveau est que comme chaque type de processeur a son propre langage machine, il a ĂŠgalement son propre langage d'assemblage. Porter des programmes assembleur entre diffĂŠrentes architectures d'ordinateur est beaucoup plus difficile qu'avec un langage de haut niveau.
Les exemples de ce livre utilisent le Netwide Assembler ou NASM en
raccourci. Il est disponible gratuitement sur Internet (voyez la prĂŠface pour l'URL). Des assembleurs plus courants sont l'Assembleur de Microsoft (MASM) ou l'Assembleur de Borland (TASM). Il y a quelques diffĂŠrences de syntaxe entre MASM/TASM et NASM.
II-C-3. OpĂŠrandes d'instruction▲
Les instructions en code machine ont un nombre et un type variables d'opĂŠrandes ; cependant, en gĂŠnĂŠral, chaque instruction a un nombre fixĂŠ d'opĂŠrandes (0 Ă 3). Les opĂŠrandes peuvent avoir les types suivants :
registre : ces opĂŠrandes font directement rĂŠfĂŠrence au contenu des registres du processeur ;
mĂŠmoire : ils font rĂŠfĂŠrence aux donnĂŠes en mĂŠmoire. L'adresse de la donnĂŠe peut ĂŞtre une constante codĂŠe en dur dans l'instruction ou calculĂŠe en utilisant les valeurs des registres. Les adresses sont toujours des dĂŠplacements relatifs au dĂŠbut d'un segment ;
immĂŠdiat : ce sont des valeurs fixes qui sont listĂŠes dans l'instruction elle-mĂŞme. Elles sont stockĂŠes dans l'instruction (dans le segment de code), pas dans le segment de donnĂŠes ;
implicite : ces opĂŠrandes ne sont pas entrĂŠs explicitement. Par exemple, l'instruction d'incrĂŠmentation ajoute 1 Ă un registre ou Ă la mĂŠmoire. Le 1 est implicite.
II-C-4. Instructions de base▲
L'instruction la plus basique est l'instruction MOV. Elle dĂŠplace les donnĂŠes d'un endroit Ă un autre (comme l'opĂŠrateur d'assignement dans un langage de haut niveau). Elle prend deux opĂŠrandes :
mov dest, srcLa donnĂŠe spĂŠcifiĂŠe par src est copiĂŠe vers dest. Une restriction est que les deux opĂŠrandes ne peuvent pas ĂŞtre tous deux des opĂŠrandes mĂŠmoire.
Cela nous montre un autre caprice de l'assembleur. Il y a souvent des règles quelque peu arbitraires sur la façon dont les diffÊrentes instructions sont utilisÊes. Les opÊrandes doivent Êgalement avoir la même taille. La valeur de AX ne peut pas être stockÊe dans BL.
Voici un exemple (les points-virgules marquent un commentaire) :
mov eax, 3 ; stocke 3 dans le registre EAX (3 est un operande immediat)
mov bx, ax ; stocke la valeur de AX dans le registre BXL'instruction ADD est utilisĂŠe pour additionner des entiers.
add eax, 4 ; eax = eax + 4
add al, ah ; al = al + ahL'instruction SUB soustrait des entiers.
sub bx, 10 ; bx = bx - 10
sub ebx, edi ; ebx = ebx - ediLes instructions INC et DEC incrĂŠmentent ou dĂŠcrĂŠmentent les valeurs de 1. Comme le 1 est un opĂŠrande implicite, le code machine pour INC et DEC est plus petit que celui des instructions ADD et SUB ĂŠquivalentes.
inc ecx ; ecx++
dec dl ; dl--II-C-5. Directives▲
Une directive est destinĂŠe Ă l'assembleur, pas au processeur. Les directives sont gĂŠnĂŠralement utilisĂŠes pour indiquer Ă l'assembleur de faire quelque chose ou pour l'informer de quelque chose. Elles ne sont pas traduites en code machine. Les utilisations courantes des directives sont :
- la dĂŠfinition de constantes ;
- la dĂŠfinition de mĂŠmoire pour stocker des donnĂŠes ;
- grouper la mĂŠmoire en segment ;
- inclure des codes source de façon conditionnelle ;
- inclure d'autres fichiers.
Le code NASM est analysĂŠ par un prĂŠprocesseur, exactement comme en C. Il y a beaucoup de commandes identiques Ă celles du prĂŠprocesseur C.
Cependant, les directives du prĂŠprocesseur NASM commencent par un % au lieu d'un # comme en C.
II-C-5-a. La directive equ▲
La directive equ peut ĂŞtre utilisĂŠe pour dĂŠfinir un symbole. Les symboles sont des constantes nommĂŠes qui peuvent ĂŞtre utilisĂŠes dans le programme assembleur. Le format est le suivant :
symbole equ valeurLes valeurs des symboles ne peuvent pas ĂŞtre redĂŠfinies plus tard.
II-C-5-b. La directive ?ne▲
Cette directive est semblable Ă la directive #define du C. Elle est le plus souvent utilisĂŠe pour dĂŠfinir des macros, exactement comme en C.
?fine SIZE 100
mov eax, SIZE
Le code ci-dessus dÊfinit une macro appelÊe SIZE et montre son utilisation dans une instruction MOV. Les macros sont plus flexibles que les symboles de deux façons. Elles peuvent être redÊfinies et peuvent être plus que de simples nombres constants.
II-C-5-c. Directives de donnĂŠes▲
Les directives de donnÊes sont utilisÊes dans les segments de donnÊes pour rÊserver de la place en mÊmoire. Il y a deux façons de rÊserver de la mÊmoire. La première ne fait qu'allouer la place pour les donnÊes ; a seconde alloue la place et donne une valeur initiale. La première mÊthode utilise une des directives RESX. Le X est remplacÊ par une lettre qui dÊtermine la taille de l'objet (ou des objets) qui sera stockÊ. Le Tableau 1.3 montre les valeurs possibles.
La seconde mĂŠthode (qui dĂŠfinit une valeur initiale) utilise une des directives DX. Les lettres X sont les mĂŞmes que celles de la directive RESX.
Il est très courant de marquer les emplacements mÊmoire avec des labels (Êtiquettes). Les labels permettent de faire rÊfÊrence facilement aux emplacements mÊmoire dans le code. Voici quelques exemples :
L1 db 0 ; octet libelle L1 avec une valeur initiale de 0
L2 dw 1000 ; mot labelle L2 avec une valeur initiale de 1000
L3 db 110101b ; octet initialise a la valeur binaire 110101 (53 en decimal)
L4 db 12h ; octet initialise a la valeur hexa 12 (18 en decimal)
L5 db 17o ; octet initialise a la valeur octale 17 (15 en decimal)
L6 dd 1A92h ; double mot initialise a la valeur hexa 1A92
L7 resb 1 ; 1 octet non initialise
L8 db "A" ; octet initialise avec le code ASCII du A (65)Les doubles et simples quotes sont traitÊes de la même façon. Les dÊfinitions de donnÊes consÊcutives sont stockÊes sÊquentiellement en mÊmoire. C'est-à -dire que le mot L2 est stockÊ immÊdiatement après L1 en mÊmoire. Des sÊquences de mÊmoire peuvent Êgalement être dÊfinies.
L9 db 0, 1, 2, 3 ; definit 4 octets
L10 db "w", "o", "r", 'd', 0 ; definit une chaine C = "word"
L11 db 'word', 0 ; idem L10La directive DD peut ĂŞtre utilisĂŠe pour dĂŠfinir Ă la fois des entiers et des constantes Ă virgule flottante en simple prĂŠcision(5). Cependant, la directive DQ ne peut ĂŞtre utilisĂŠe que pour dĂŠfinir des constantes Ă virgule flottante en double prĂŠcision.
Pour les grandes sÊquences, la directive de NASM TIMES est souvent utile. Cette directive rÊpète son opÊrande un certain nombre de fois. Par exemple :
L12 times 100 db 0 ; equivalent a 100 (db 0)
L13 resw 100 ; reserve de la place pour 100 motsSouvenez-vous que les labels peuvent être utilisÊs pour faire rÊfÊrence à des donnÊes dans le code. Il y a deux façons d'utiliser les labels. Si un label simple est utilisÊ, il fait rÊfÊrence à l'adresse (ou offset) de la donnÊe.
Si le label est placĂŠ entre crochets ([ ]), il est interprĂŠtĂŠ comme la donnĂŠe Ă cette adresse. En d'autres termes, il faut considĂŠrer un label comme un pointeur vers la donnĂŠe et les crochets dĂŠrĂŠfĂŠrencent le pointeur, exactement comme l'astĂŠrisque en C (MASM/TASM utilisent une convention diffĂŠrente).
En mode 32 bits, les adresses sont sur 32 bits. Voici quelques exemples :
2.
3.
4.
5.
6.
7.
mov al, [L1] ; Copie l'octet situe en L1 dans AL
mov eax, L1 ; EAX = addresse de l'octet en L1
mov [L1], ah ; copie AH dans l'octet en L1
mov eax, [L6] ; copie le double mot en L6 dans EAX
add eax, [L6] ; EAX = EAX + double mot en L6
add [L6], eax ; double mot en L6 += EAX
mov al, [L6] ; copie le premier octet du double mot en L6 dans AL
La ligne 7 de cet exemple montre une propriÊtÊ importante de NASM. L'assembleur ne garde pas de trace du type de donnÊes auquel se rÊfère le label. C'est au programmeur de s'assurer qu'il (ou elle) utilise un label correctement.
Plus tard, il sera courant de stocker des adresses dans les registres et utiliser les registres comme un pointeur en C. LĂ encore, aucune vĂŠrification n'est faite pour savoir si le pointeur est utilisĂŠ correctement. Ă ce niveau, l'assembleur est beaucoup plus sujet Ă erreur que le C.
ConsidĂŠrons l'instruction suivante :
mov [L6], 1 ; stocke 1 en L6
Cette instruction produit une erreur operation size not specified. Pourquoi ?
Parce que l'assembleur ne sait pas s'il doit considĂŠrer 1 comme un octet, un mot ou un double mot. Pour rĂŠparer cela, il faut ajouter un spĂŠcificateur de taille :
mov dword [L6], 1 ; stocke 1 en L6
Cela indique Ă l'assembleur de stocker un 1 dans le double mot qui commence en L6. Les autres spĂŠcificateurs de taille sont : BYTE, WORD, QWORD et TWORD(6).
II-C-6. EntrĂŠes et sorties▲
Les entrÊes et sorties sont des activitÊs très dÊpendantes du système. Cela implique un interfaçage avec le matÊriel. Les langages de plus haut niveau, comme C, fournissent des bibliothèques standard de routines pour une interface de programmation simple, uniforme pour les E/S. Les langages d'assembleur n'ont pas de bibliothèque standard. Ils doivent soit accÊder directement au matÊriel (avec une opÊration privilÊgiÊe en mode protÊgÊ) ou utiliser les routines de bas niveau Êventuellement fournies par le système d'exploitation.
Il est très courant pour les routines assembleur d'être interfacÊes avec du C. Un des avantages de cela est que le code assembleur peut utiliser les routines d'E/S de la bibliothèque standard du C. Cependant, il faut connaÎtre les règles de passage des informations aux routines que le C utilise.
Ces règles sont trop compliquÊes pour en parler ici (nous en parlerons plus tard !). Pour simplifier les E/S, l'auteur a dÊveloppÊ ses propres routines qui masquent les règles complexes du C et fournissent une interface beaucoup plus simple. Le Tableau 1.4 dÊcrit les routines fournies. Toutes les routines prÊservent les valeurs de tous les registres, exceptÊ les routines read. Ces routines modifient la valeur du registre EAX. Pour utiliser ces routines, il faut inclure un fichier contenant les informations dont l'assembleur a besoin pour les utiliser. Pour inclure un fichier dans NASM, utilisez la directive du prÊprocesseur %include. La ligne suivante inclut le fichier requis par les routines d'E/S de l'auteur(7) :
%include "asm_io.inc"
Pour utiliser une de ces routines d'affichage, il faut charger EAX avec la valeur correcte et utiliser une instruction CALL pour l'invoquer. L'instruction CALL est ĂŠquivalente Ă un appel de fonction dans un langage de haut niveau.
Elle saute Ă une autre portion de code, mais revient Ă son origine une fois la routine terminĂŠe. Le programme d'exemple ci-dessous montre plusieurs exemples d'appel Ă ces routines d'E/S.

II-C-7. DĂŠbogage▲
La bibliothèque de l'auteur contient Êgalement quelques routines utiles pour dÊboguer les programmes. Ces routines de dÊbogage affichent des informations sur l'Êtat de l'ordinateur sans le modifier. Ces routines sont en fait des macros qui sauvegardent l'Êtat courant du processeur puis font appel à une sous-routine. Les macros sont dÊfinies dans le fichier asm_io.inc dont nous avons parlÊ plus haut. Les macros sont utilisÊes comme des instructions ordinaires. Les opÊrandes des macros sont sÊparÊs par des virgules.
Il y a quatre routines de dĂŠbogage nommĂŠes dump_regs, dump_mem, dump_stack et dump_math ; elles affichent respectivement les valeurs des registres, de la mĂŠmoire, de la pile et du coprocesseur arithmĂŠtique.
dump_regs : cette macro affiche les valeurs des registres (en hexadĂŠcimal) de l'ordinateur sur stdout (i.e. l'ĂŠcran). Elle affiche ĂŠgalement les bits positionnĂŠs dans le registre FLAGS(8). Par exemple, si le drapeau zĂŠro (zero ag) est Ă 1, ZF est affichĂŠ. S'il est Ă 0, il n'est pas affichĂŠ. Elle prend en argument un entier qui est affichĂŠ ĂŠgalement. Cela peut aider Ă distinguer la sortie de diffĂŠrentes commandes dump_regs.
dump_mem : cette macro affiche les valeurs d'une rÊgion de la mÊmoire (en hexadÊcimal et Êgalement en caractères ASCII). Elle prend trois arguments sÊparÊs par des virgules. Le premier est un entier utilisÊ pour Êtiqueter la sortie (comme l'argument de dump_regs). Le second argument est l'adresse à afficher (cela peut être un label). Le dernier argument est le nombre de paragraphes de 16 octets à afficher après l'adresse. La mÊmoire affichÊe commencera au premier multiple de paragraphe avant l'adresse demandÊe.
dump_stack : cette macro affiche les valeurs de la pile du processeur (la pile sera prÊsentÊe dans le Chapitre V). La pile est organisÊe en doubles-mots et cette routine les affiche de cette façon. Elle prend trois arguments dÊlimitÊs par des virgules. Le premier est un entier (comme pour
dump_regs). Le second est le nombre de doubles-mots à afficher après l'adresse que le registre EBP contient et le troisième argument est le nombre de doubles-mots à afficher avant l'adresse contenue dans EBP.
dump_math : cette macro affiche les valeurs des registres du coprocesseur arithmĂŠtique. Elle ne prend qu'un entier en argument qui est utilisĂŠ pour ĂŠtiqueter la sortie comme le fait l'argument de dump_regs.
II-D. CrĂŠer un programme▲
Aujourd'hui, il est très peu courant de crÊer un programme autonome Êcrit complètement en langage assembleur. L'assembleur est habituellement utilisÊ pour optimiser certaines routines critiques. Pourquoi ? Il est beaucoup plus simple de programmer dans un langage de plus haut niveau qu'en assembleur.
De plus, utiliser l'assembleur rend le programme très dur à porter sur d'autres plateformes. En fait, il est rare d'utiliser l'assembleur tout court.
Alors, pourquoi apprendre l'assembleur ?
1. Quelques fois, le code ĂŠcrit en assembleur peut ĂŞtre plus rapide et plus compact que le code gĂŠnĂŠrĂŠ par un compilateur.
2. L'assembleur permet l'accès à des fonctionnalitÊs matÊrielles du système directement qu'il pourrait être difficile ou impossible à utiliser depuis un langage de plus haut niveau.
3. Apprendre à programmer en assembleur aide à acquÊrir une comprÊhension plus profonde de la façon dont fonctionne un ordinateur.
4. Apprendre Ă programmer en assembleur aide Ă mieux comprendre comment les compilateurs et les langages de haut niveau comme C fonctionnent.
Ces deux derniers points dÊmontrent qu'apprendre l'assembleur peut être utile même si on ne programme jamais dans ce langage plus tard. En fait, l'auteur programme rarement en assembleur, mais il utilise les leçons qu'il en a tirÊes tous les jours.
II-D-1. Premier programme▲
Les programmes qui suivront dans ce texte partiront tous du programme de lancement en C de la Figure 1.6.

Il appelle simplement une autre fonction nommÊe asm_main. C'est la routine qui sera Êcrite en assembler proprement dit. Il y a plusieurs avantages à utiliser un programme de lancement en C. Tout d'abord, cela laisse le système du C initialiser le programme de façon à fonctionner correctement en mode protÊgÊ. Tous les segments et les registres correspondants seront initialisÊs par le C. L'assembleur n'aura pas à se prÊoccuper de cela. Ensuite, la bibliothèque du C pourra être utilisÊe par le code assembleur. Les routines d'E/S de l'auteur en tirent parti. Elles utilisent les fonctions d'E/S du C (printf, etc.). L'exemple suivant montre un programme assembleur simple.
asm
1 ; fichier : first.asm
2 ; Premier programme assembleur. Ce programme attend la saisie de deux
3 ; entiers et affiche leur somme.
4 ;
5 ; Pour creer l'executable en utilisant djgpp :
6 ; nasm -f coff first.asm
7 ; gcc -o first first.o driver.c asm_io.o
8
9 %include "asm_io.inc"
10 ;
11 ; Les donnees initialisees sont placees dans le segment .data
12 ;
13 segment .data
14 ;
15 ; Ces labels referencent les chaines utilisees pour l'affichage
16 ;
17 prompt1 db "Entrez un nombre : ", 0 ; N'oubliez pas le 0 final
18 prompt2 db "Entrez un autre nombre : ", 0
19 outmsg1 db "Vous avez entre ", 0
20 outmsg2 db " et ", 0
21 outmsg3 db ", leur somme vaut ", 0
22
23 ;
24 ; Les donnees non initialisees sont placees dans le segment .bss
25 ;
26 segment .bss
27 ;
28 ; Ces labels referencent les doubles-mots utilises pour stocker les entrees
29 ;
30 input1 resd 1
31 input2 resd 1
32
33 ;
34 ; Le code est place dans le segment .text
35 ;
36 segment .text
37 global _asm_main
38 _asm_main :
39 enter 0,0 ; initialisation
40 pusha
41
42 mov eax, prompt1 ; affiche un message
43 call print_string
44
45 call read_int ; lit un entier
46 mov [input1], eax ; le stocke dans input1
47
48 mov eax, prompt2 ; affiche un message
49 call print_string
50
51 call read_int ; lit un entier
52 mov [input2], eax ; le stocke dans input2
53
54 mov eax, [input1] ; eax = dword en input1
55 add eax, [input2] ; eax += dword en input2
56 mov ebx, eax ; ebx = eax
57
58 dump_regs 1 ; affiche les valeurs des registres
59 dump_mem 2, outmsg1, 1 ; affiche le contenu de la memoire
60 ;
61 ; Ce qui suit affiche le message resultat en plusieurs etapes
62 ;
63 mov eax, outmsg1
64 call print_string ; affiche le premier message
65 mov eax, [input1]
66 call print_int ; affiche input1
67 mov eax, outmsg2
68 call print_string ; affiche le second message
69 mov eax, [input2]
70 call print_int ; affiche input2
71 mov eax, outmsg3
72 call print_string ; affiche le troisieme message
73 mov eax, ebx
74 call print_int ; affiche la somme (ebx)
75 call print_nl ; affiche une nouvelle ligne
76
77 popa
78 mov eax, 0 ; retourne dans le programme C
79 leave
80 retLa ligne 13 du programme dĂŠfinit une section qui spĂŠcifie la mĂŠmoire Ă stocker dans le segment de donnĂŠes (dont le nom est .data). Seules les donnĂŠes initialisĂŠes doivent ĂŞtre dĂŠfinies dans ce segment.
Dans les lignes 17 à 21, plusieurs chaÎnes sont dÊclarÊes. Elles seront affichÊes avec la bibliothèque C et doivent donc se terminer par un caractère null (code ASCII 0). Souvenez-vous qu'il y a une grande diffÊrence entre 0 et '0'.
Les donnĂŠes non initialisĂŠes doivent ĂŞtre dĂŠclarĂŠes dans le segment bss (appelĂŠ .bss Ă la ligne 26). Ce segment tient son nom d'un vieil opĂŠrateur assembleur UNIX qui signifiait block started by symbol. Il y a ĂŠgalement un segment de pile. Nous en parlerons plus tard.
Le segment de code est appelÊ .text historiquement. C'est là que les instructions sont placÊes. Notez que le label de code pour la routine main (ligne 38) a un prÊfixe de soulignement. Cela fait partie de la convention d'appel C. Cette convention spÊcifie les règles que le C utilise lorsqu'il compile le code. Il est très important de connaÎtre cette convention lorsque l'on interface du C et de l'assembleur. Plus loin, la convention sera prÊsentÊe dans son intÊgralitÊ ; cependant, pour l'instant, il suffit de savoir que tous les symboles C (i.e., les fonctions et les variables globales) ont un prÊfixe de soulignement qui leur est ajoutÊ par le compilateur C (cette règle s'applique spÊcifiquement pour DOS/Windows, le compilateur C Linux n'ajoute rien du tout aux noms des symboles).
La directive global ligne 37 indique Ă l'assembleur de rendre le label _asm_main global. Contrairement au C, les labels ont une portĂŠe interne par dĂŠfaut. Cela signifie que seul le code du mĂŞme module peut utiliser le label.
La directive global donne au(x) label(s) spĂŠcifiĂŠ(s) une portĂŠe externe. Ce type de label peut ĂŞtre accĂŠdĂŠ par n'importe quel module du programme.
Le module asm_io dĂŠclare les labels print_int, et.al. comme ĂŠtant globaux. C'est pourquoi l'on peut les utiliser dans le module first.asm.
II-D-2. DĂŠpendance vis-Ă -vis du compilateur▲
Le code assembleur ci-dessus est spĂŠcifique au compilateur C/C++ GNU(9) gratuit DJGPP(10).
Ce compilateur peut ĂŞtre tĂŠlĂŠchargĂŠ gratuitement depuis Internet. Il nĂŠcessite un PC Ă base de 386 ou plus et tourne sous DOS, Windows 95/98 ou NT. Ce compilateur utilise des fichiers objet au format COFF (Common Object File Format). Pour assembler le fichier au format COFF, utilisez l'option -f coff avec nasm (comme l'indiquent les commentaires du code). L'extension du fichier objet sera o.
Le compilateur C Linux est ĂŠgalement un compilateur GNU. Pour convertir le code ci-dessus afin qu'il tourne sous Linux, retirez simplement les prĂŠfixes de soulignement aux lignes 37 et 38. Linux utilise le format ELF (Executable and Linkable Format) pour les fichiers objet. Utilisez l'option -f elf pour Linux. Il produit ĂŠgalement un fichier objet avec l'extension o.
Les fichiers spĂŠcifiques aucompilateur, disponibles sur le site de l'auteur, ont dĂŠjĂ ĂŠtĂŠ modifiĂŠs pour fonctionner avec le compilateur appropriĂŠ.
Borland C/C++ est un autre compilateur populaire. Il utilise le format Microsoft OMF pour les fichiers objets. Utilisez l'option -f obj pour les compilateurs Borland. L'extension du fichier objet sera obj. Le format OMF utilise des directives segment diffĂŠrentes de celles des autres formats objet.
Le segment data (ligne 13) doit ĂŞtre changĂŠ en :
segment _DATA public align=4 class=DATA use32Le segment bss (ligne 26) doit ĂŞtre changĂŠ en :
segment _BSS public align=4 class=BSS use32Le segment text (ligne 36) doit ĂŞtre changĂŠ en :
segment _TEXT public align=1 class=CODE use32De plus, une nouvelle ligne doit ĂŞtre ajoutĂŠe avant la ligne 36 :
group DGROUP _BSS _DATALe compilateur Microsoft C/C++ peut utiliser soit le format OMF, soit le format Win32 pour les fichiers objet (si on lui passe un format OMF, il convertit les informations au format Win32 en interne). Le format Win32 permet de dĂŠfinir les segments comme pour DJGPP et Linux. Utilisez l'option -f win32 pour produire un fichier objet dans ce format. L'extension du fichier objet sera obj.
II-D-3. Assembler le code▲
La première Êtape consiste à assembler le code. Depuis la ligne de commande, saisissez :
nasm -f format-objet first.asmoĂš format-objet est soit co , soit elf , soit obj soit win32 selon le compilateur C utilisĂŠ (souvenez-vous que le fichier source doit ĂŞtre modifiĂŠ pour Linux et pour Borland).
II-D-4. Compiler le code C▲
Compilez le fichier driver.c en utilisant un compilateur C. Pour DJGPP, utilisez :
gcc -c driver.cL'option -c signifie de compiler uniquement, sans essayer de lier. Cette option fonctionne Ă la fois sur les compilateurs Linux, Borland et Microsoft.
II-D-5. Lier les fichiers objet▲
L'Êdition de liens est le procÊdÊ qui consiste à combiner le code machine et les donnÊes des fichiers objet et des bibliothèques afin de crÊer un fichier exÊcutable. Comme nous allons le voir, ce processus est compliquÊ.
Le code C nÊcessite la bibliothèque standard du C et un code de dÊmarrage spÊcial afin de s'exÊcuter. Il est beaucoup plus simple de laisser le compilateur C appeler l'Êditeur de liens avec les paramètres corrects que d'essayer d'appeler l'Êditeur de liens directement. Par exemple, pour lier le code du premier programme en utilisant DJGPP, utilisez :
gcc -o first driver.o first.o asm_io.oCela crĂŠe un exĂŠcutable appelĂŠ first.exe (ou juste first sous Linux).
Avec Borland, on utiliserait :
bcc32 first.obj driver.obj asm_io.objBorland utilise le nom du premier fichier afin de dĂŠterminer le nom de l'exĂŠcutable. Donc, dans le cas ci-dessus, le programme s'appellera first.exe.
Il est possible de combiner les ĂŠtapes de compilation et d'ĂŠdition de liens.
Par exemple :
gcc -o first driver.c first.o asm_io.oMaintenant gcc compilera driver.c puis liera.
II-D-6. Comprendre un listing assembleur▲
L'option -l fichier-listing peut ĂŞtre utilisĂŠe pour indiquer Ă nasm de crĂŠer un fichier listing avec le nom donnĂŠ. Ce fichier montre comment le code a ĂŠtĂŠ assemblĂŠ. Voici comment les lignes 17 et 18 (dans le segment data) apparaissent dans le fichier listing (les numĂŠros de ligne sont dans le
fichier listing ; cependant, notez que les numĂŠros de ligne dans le fichier source peuvent ne pas ĂŞtre les mĂŞmes).
48 00000000 456E7465722061206E- prompt1 db "Entrez un nombre : ", 0
49 00000009 756D6265723A2000
50 00000011 456E74657220616E6F- prompt2 db "Entrez un autre nombre : ", 0
51 0000001A 74686572206E756D62-
52 00000023 65723A2000Les nombres diffèrent sur la version française, car ce ne sont pas les mêmes caractères.
La première colonne de chaque ligne est le numÊro de la ligne et la seconde est le dÊplacement (en hexa) de la donnÊe dans le segment. La troisième colonne montre les donnÊes hexa brutes qui seront stockÊes. Dans ce cas, les donnÊes hexa correspondent aux codes ASCII. Enfin, le texte du fichier source est affichÊ sur la droite. Les dÊplacements listÊs dans la seconde colonne ne sont très probablement pas les dÊplacements rÊels auxquels les donnÊes seront placÊes dans le programme terminÊ. Chaque module peut dÊfinir ses propres labels dans le segment de donnÊes (et les autres segments Êgalement). Lors de l'Êtape d'Êdition de liens (voir Section II.D.5), toutes ces dÊfinitions de labels de segment de donnÊes sont combinÊes pour ne former qu'un segment de donnÊes. Les dÊplacements finals sont alors calculÊs par l'Êditeur de liens.
Voici une petite portion (lignes 54 Ă 56 du fichier source) du segment text dans le fichier listing :
94 0000002C A1[00000000] mov eax, [input1]
95 00000031 0305[04000000] add eax, [input2]
96 00000037 89C3 mov ebx, eaxLa troisième colonne montre le code machine gÊnÊrÊ par l'assembleur. Souvent le code complet pour une instruction ne peut pas encore être calculÊ.
Par exemple, ligne 94, le dÊplacement (ou l'adresse) de input1 n'est pas connu avant que le code ne soit liÊ. L'assembleur peut calculer l'opcode pour l'instruction mov (qui, d'après le listing, est A1), mais il Êcrit le dÊplacement entre crochets, car la valeur exacte ne peut pas encore être calculÊe. Dans ce cas, un dÊplacement temporaire de 0 est utilisÊ, car input1 est au dÊbut du segment bss dÊclarÊ dans ce fichier. Souvenez-vous que cela ne signifie pas qu'il sera au dÊbut du segment bss final du programme. Lorsque le code est liÊ, l'Êditeur de liens insÊrera le dÊplacement correct à la place.
D'autres instructions, comme ligne 96, ne font rĂŠfĂŠrence Ă aucun label. Dans ce cas, l'assembleur peut calculer le code machine complet.
ReprĂŠsentations Big et Little Endian
Endian est prononcĂŠ comme indian.
Si l'on regarde attentivement la ligne 95, quelque chose semble très bizarre à propos du dÊplacement entre crochets dans le code machine. Le label input2 est au dÊplacement 4 (comme dÊfini dans ce fichier) ; cependant, le dÊplacement qui apparaÎt en mÊmoire n'est pas 00000004, mais 04000000.
Pourquoi ? Des processeurs diffĂŠrents stockent les entiers multioctets dans des ordres diffĂŠrents en mĂŠmoire. Il y a deux mĂŠthodes populaires pour stocker : big endian et little endian. Le big endian est la mĂŠthode qui semble la plus naturelle. L'octet le plus fort (i.e. le plus significatif) est stockĂŠ en premier, puis le second plus fort, etc. Par exemple, le dword 00000004 serait stockĂŠ sous la forme des quatre octets suivants : 00 00 00 04.
Les mainframes IBM, la plupart des processeurs RISC et les processeurs Motorola utilisent tous cette mĂŠthode big endian. Cependant, les processeurs de type Intel utilisent la mĂŠthode little endian ! Ici, l'octet le moins significatif est stockĂŠ en premier. Donc, 00000004 est stockĂŠ en mĂŠmoire sous la forme 04 00 00 00. Ce format est codĂŠ en dur dans le processeur et ne peut pas ĂŞtre changĂŠ. Normalement, le programmeur n'a pas besoin de s'inquiĂŠter du format utilisĂŠ. Cependant, il y a des circonstances oĂš c'est important.
1. Lorsque des donnĂŠes binaires sont transfĂŠrĂŠes entre diffĂŠrents ordinateurs (soit via des fichiers, soit via un rĂŠseau).
2. Lorsque des donnĂŠes binaires sont ĂŠcrites en mĂŠmoire comme un entier multioctet puis relues comme des octets individuels ou vice versa.
Le caractère big ou little endian ne s'applique pas à l'ordre des ÊlÊments d'un tableau. Le premier ÊlÊment d'un tableau est toujours à l'adresse la plus petite. C'est Êgalement valable pour les chaÎnes (qui sont juste des tableaux de caractères). Cependant, le caractère big ou little endian s'applique toujours aux ÊlÊments individuels des tableaux.
II-E. Fichier squelette▲
La Figure 1.7 montre un fichier squelette qui peut ĂŞtre utilisĂŠ comme point de dĂŠpart pour l'ĂŠcriture de programmes assembleur.

III. Bases du langage assembleur▲
III-A. Travailler avec les entiers▲
III-A-1. ReprĂŠsentation des entiers▲
Les entiers se dÊcomposent en deux catÊgories : signÊs et non signÊs. Les entiers non signÊs (qui sont positifs) sont reprÊsentÊs d'une manière binaire très intuitive. Le nombre 200 en tant qu'entier non signÊ sur un octet serait reprÊsentÊ par 11001000 (ou C8 en hexa).
Les entiers signÊs (qui peuvent être positifs ou nÊgatifs) sont reprÊsentÊs d'une façon plus compliquÊe. Par exemple, considÊrons ?56. +56 serait reprÊsentÊ par l'octet 00111000. Sur papier, on peut reprÊsenter ?56 comme ?111000, mais comment cela serait-il reprÊsentÊ dans un octet en mÊmoire de l'ordinateur. Comment serait stockÊ le signe moins ?
Il y a trois techniques principales qui ont ĂŠtĂŠ utilisĂŠes pour reprĂŠsenter les entiers signĂŠs dans la mĂŠmoire de l'ordinateur. Toutes ces mĂŠthodes utilisent le bit le plus significatif de l'entier comme bit de signe. Ce bit vaut 0 si le nombre est positif et 1 s'il est nĂŠgatif.
III-A-1-a. Grandeur signĂŠe▲
La première mÊthode est la plus simple, elle est appelÊe grandeur signÊe.
Elle reprÊsente l'entier en deux parties. La première partie est le bit de signe et la seconde est la grandeur entière. Donc 56 serait reprÊsentÊ par l'octet 00111000 (le bit de signe est soulignÊ) et ?56 serait 10111000. La valeur d'octet la plus grande serait 01111111 soit +127 et la plus petite valeur sur un octet serait 11111111 soit ?127. Pour obtenir l'opposÊ d'une valeur, on inverse le bit de signe. Cette mÊthode est intuitive, mais a ses inconvÊnients. Tout d'abord, il y a deux valeurs possibles pour 0 : +0 (00000000) et ?0 (10000000). Comme zÊro n'est ni positif ni nÊgatif, ces deux reprÊsentations devraient se comporter de la même façon. Cela complique la logique de l'arithmÊtique pour le processeur. De plus, l'arithmÊtique gÊnÊrale est Êgalement compliquÊe. Si l'on ajoute 10 à ?56, cela doit être transformÊ en 10 moins 56. Là encore, cela complique la logique du processeur.
III-A-1-b. ComplĂŠment Ă 1▲
La seconde mĂŠthode est appelĂŠe reprĂŠsentation en complĂŠment Ă un.
Le complÊment à un d'un nombre est trouvÊ en inversant chaque bit du nombre (une autre façon de l'obtenir est que la valeur du nouveau bit est 1 ? anciennevaleurdubit). Par exemple, le complÊment à un de 00111000 (+56) est 11000111. Dans la notation en complÊment à un, calculer le complÊment à un est Êquivalent à la nÊgation. Donc 11000111 est la reprÊsentation de ?56. Notez que le bit de signe a ÊtÊ automatiquement changÊ par le complÊment à un et que, comme l'on s'y attendait, appliquer le complÊment à un deux fois redonne le nombre de dÊpart. Comme pour la première mÊthode, il y a deux reprÊsentations pour 0 : 00000000 (+0) et 11111111 (?0).
L'arithmĂŠtique des nombres en complĂŠment Ă 1 est compliquĂŠe. Voici une astuce utile pour trouver le complĂŠment Ă 1 d'un nombre en hexadĂŠcimal sans repasser en binaire. L'astuce est d'Ă´ter le chiffre hexa de F (ou 15 en dĂŠcimal). Cette mĂŠthode suppose que le nombre de bits dans le nombre est multiple de 4. Voici un exemple : +56 est reprĂŠsentĂŠ par 38 en hexa. Pour trouver le complĂŠment Ă 1, Ă´tez chaque chiffre de F pour obtenir C7 en hexa. Cela concorde avec le rĂŠsultat ci-dessus.
III-A-1-c. ComplĂŠment Ă 2▲
Les deux premières mÊthodes dÊcrites ont ÊtÊ utilisÊes sur les premiers ordinateurs. Les ordinateurs modernes utilisent une troisième mÊthode appelÊe reprÊsentation en complÊment à 2. On trouve le complÊment à 2 d'un nombre en effectuant les deux opÊrations suivantes :
1. Trouver le complĂŠment Ă un du nombre ;
2. Ajouter 1 au rĂŠsultat de l'ĂŠtape 1.
Voici un exemple en utilisant 00111000 (56). Tout d'abord, on calcule le complĂŠment Ă 1 : 11000111. Puis, on ajoute 1 :
11000111
+ 1
11001000
Dans la notation en complĂŠment Ă 2, calculer le complĂŠment Ă 2 est ĂŠquivalent Ă trouver l'opposĂŠ d'un nombre. Donc, 11001000 est la reprĂŠsentation en complĂŠment Ă 2 de ?56. Deux nĂŠgations devraient reproduire le nombre original. Curieusement le complĂŠment Ă 2 ne remplit pas cette condition. Prenez le complĂŠment Ă 2 de 11001000 en ajoutant 1 au complĂŠment Ă 1.
00110111
+ 1
00111000
Lorsque l'on effectue l'addition dans l'opĂŠration de complĂŠmentation Ă 2, l'addition du bit le plus Ă gauche peut produire une retenue. Cette retenue n'est pas utilisĂŠe. Souvenez-vous que toutes les donnĂŠes sur un ordinateur sont d'une taille fixe (en termes de nombre de bits). Ajouter deux octets produit toujours un rĂŠsultat sur un octet (comme ajouter deux mots donne un mot, etc.) Cette propriĂŠtĂŠ est importante pour la notation en complĂŠment Ă 2. Par exemple, considĂŠrons zĂŠro comme un nombre en complĂŠment Ă 2 sur un octet (00000000). Calculer son complĂŠment Ă 2 produit la somme :
11111111
+ 1
c 00000000
oĂš c reprĂŠsente une retenue (plus tard, nous montrerons comment dĂŠtecter cette retenue, mais elle n'est pas stockĂŠe dans le rĂŠsultat). Donc, en notation en complĂŠment Ă 2, il n'y a qu'un zĂŠro. Cela rend l'arithmĂŠtique en complĂŠment Ă 2 plus simple que les mĂŠthodes prĂŠcĂŠdentes.
En utilisant la notation en complĂŠment Ă 2, un octet signĂŠ peut ĂŞtre utilisĂŠ pour reprĂŠsenter les nombres ?128 Ă +127.
Le Tableau 2.1 montre quelques valeurs choisies. Si 16 bits sont utilisĂŠs, les nombres signĂŠs ?32 768 Ă +32 767 peuvent ĂŞtre reprĂŠsentĂŠs. +32 767 est reprĂŠsentĂŠ par 7FFF, ?32 768
par 8000, -128 par FF80 et -1 par FFFF. Les nombres en complĂŠment Ă 2 sur 32 bits vont de ?2 milliards Ă +2 milliards environ.
Le processeur n'a aucune idÊe de ce qu'un octet en particulier (ou un mot ou un double-mot) est supposÊ reprÊsentÊ. L'assembleur n'a pas le concept de types qu'un langage de plus haut niveau peut avoir. La façon dont les donnÊes sont interprÊtÊes dÊpend de l'instruction dans laquelle on les utilise. Que la valeur FF soit considÊrÊe comme reprÊsentant un ?1 signÊ ou 1 +255 non signÊ dÊpend du programmeur. Le langage C dÊfinit des types entiers signÊs et non signÊs. Cela permet au compilateur C de dÊterminer les instructions correctes à utiliser avec les donnÊes.
III-A-2. Extension de signe▲
En assembleur, toutes les donnĂŠes ont une taille bien spĂŠcifiĂŠe. Il n'est pas rare de devoir changer la taille d'une donnĂŠe pour l'utiliser avec d'autres. RĂŠduire la taille est le plus simple.
III-A-2-a. RĂŠduire la taille des donnĂŠes▲
Pour rĂŠduire la taille d'une donnĂŠe, il suffit d'en retirer les bits les plus significatifs. Voici un exemple trivial :
mov ax, 0034h ; ax = 52 (stockĂŠ sur 16 bits)
mov cl, al ; cl = les 8 bits de poids faible de axBien sĂťr, si le nombre ne peut pas ĂŞtre reprĂŠsentĂŠ correctement dans une plus petite taille, rĂŠduire la taille ne fonctionne pas. Par exemple, si AX valait 0134h (ou 308 en dĂŠcimal) alors le code ci-dessus mettrait quand mĂŞme CL Ă 34h. Cette mĂŠthode fonctionne Ă la fois avec les nombres signĂŠs et non signĂŠs. ConsidĂŠrons les nombres signĂŠs, si AX valait FFFFh (?1 sur un mot), alors CL vaudrait FFh (?1 sur un octet). Cependant, notez que si la valeur dans AX ĂŠtait signĂŠe, elle aurait ĂŠtĂŠ tronquĂŠe et le rĂŠsultat aurait ĂŠtĂŠ faux !
La règle pour les nombres non signÊs est que tous les bits retirÊs soient à 0 afin que la conversion soit correcte. La règle pour les nombres signÊs est que les bits retirÊs doivent soit tous être des 1 soit tous des 0. De plus, le premier bit à ne pas être retirÊ doit valoir la même chose que ceux qui l'ont ÊtÊ. Ce bit sera le bit de signe pour la valeur plus petite. Il est important qu'il ait la même valeur que le bit de signe original !
III-A-2-b. Augmenter la taille des donnĂŠes▲
Augmenter la taille des donnÊes est plus compliquÊ que la rÊduire. ConsidÊrons l'octet hexa FF. S'il est Êtendu à un mot, quelle valeur aura-t-il ? Cela dÊpend de la façon dont FF est interprÊtÊ. Si FF est un octet non signÊ (255 en dÊcimal), alors le mot doit être 00FF ; cependant, s'il s'agit d'un octet signÊ (?1 en dÊcimal), alors le mot doit être FFFF.
En gĂŠnĂŠral, pour ĂŠtendre un nombre non signĂŠ, on met tous les bits supplĂŠmentaires du nouveau nombre Ă 0. Donc, FF devient 00FF. Cependant, pour ĂŠtendre un nombre signĂŠ, on doit ĂŠtendre le bit de signe. Cela signifie que les nouveaux bits deviennent des copies du bit de signe. Comme le bit de signe de FF est Ă 1, les nouveaux bits doivent ĂŠgalement ĂŞtre des 1, pour donner FFFF. Si le nombre signĂŠ 5A (90 en dĂŠcimal) ĂŠtait ĂŠtendu, le rĂŠsultat serait 005A.
Il y a plusieurs instructions fournies par le 80386 pour ĂŠtendre les nombres.
Souvenez-vous que l'ordinateur ne sait pas si un nombre est signÊ ou non. C'est au programmeur d'utiliser l'instruction adÊquate. Pour les nombres non signÊs, on peut placer des 0 dans les bits de poids fort de façon simple en utilisant l'instruction MOV. Par exemple pour Êtendre l'octet de AL en un mot non signÊ dans AX :
mov ah, 0 ; met les 8 bits de poids fort à 0Cependant, il n'est pas possible d'utiliser une instruction MOV pour convertir le mot non signÊ de AX en un double-mot non signÊ dans EAX. Pourquoi pas ? Il n'y a aucune façon d'accÊder aux 16 bits de poids fort de EAX dans un MOV. Le 80386 rÊsout ce problème en fournissant une nouvelle instruction : MOVZX. Cette instruction a deux opÊrandes. La destination (premier opÊrande) doit être un registre de 16 ou 32 bits. La source (deuxième opÊrande) doit être un registre 8 ou 16 bits. L'autre restriction est que la destination doit être plus grande que la source (la plupart des instructions requièrent que la source soit de la même taille que la destination). Voici quelques exemples :
movzx eax, ax ; ĂŠtend ax Ă eax
movzx eax, al ; ĂŠtend al Ă eax
movzx ax, al ; ĂŠtend al Ă ax
movzx ebx, ax ; Êtend ax à ebxPour les nombres signÊs, il n'y a pas de façon simple d'utiliser l'instruction MOV quel que soit le cas. Le 8086 fournit plusieurs instructions pour Êtendre les nombres signÊs. L'instruction CBW (Convert Byte to Word, Convertir un Octet en Mot) Êtend le signe du registre AL dans AX. Les opÊrandes sont implicites. L'instruction CWD (Convert Word to Double word, Convertir un Mot en Double-mot) Êtend le signe de AX dans DX:AX. La notation DX:AX signifie qu'il faut considÊrer les registres DX et AX comme un seul registre 32 bits avec les 16 bits de poids forts dans DX et les bits de poids faible dans AX (souvenez-vous que le 8086 n'avait pas de registre 32 bits du tout !). Le 80386 a apportÊ plusieurs nouvelles instructions. L'instruction CWDE (Convert Word to Double word Extended, convertir un mot en double mot Êtendue) Êtend le signe de AX dans EAX. L'instruction CDQ (Convert Double word to Quad word, Convertir un Double-mot en Quadruple-mot) Êtend le signe de EAX dans EDX:EAX (64 bits !) Enn, l'instruction MOVSX fonctionne comme MOVZX exceptÊ qu'elle utilise les règles des nombres signÊs.
III-A-2-c. Application Ă la programmation en C▲
L'extension d'entiers signĂŠs et non signĂŠs a ĂŠgalement lieu en C. Les variables en C peuvent ĂŞtre dĂŠclarĂŠes soit comme signĂŠes soit comme non signĂŠes (les int sont signĂŠs).

Le C ANSI ne dĂŠfinit pas si le type char est signĂŠ ou non, c'est Ă chaque compilateur de le dĂŠcider. C'est pourquoi on dĂŠfinit le type explicitement dans la Figure 2.1.
ConsidÊrons le code de la Figure 2.1. à la ligne 3, la variable a est Êtendue en utilisant les règles pour les valeurs non signÊes (avec MOVZX), mais à la ligne 4, les règles signÊes sont utilisÊes pour b (avec MOVSX).
Il existe un bogue de programmation courant en C qui est directement liĂŠ Ă notre sujet. ConsidĂŠrons le code de la Figure 2.2. Le prototype de fgetc()est :
int fgetc( FILE * );On peut se demander pourquoi la fonction renvoie un int puisqu'elle lit des caractères. La raison est qu'elle renvoie normalement un char (Êtendu à une valeur int en utilisant l'extension de zÊro). Cependant, il y a une valeur qu'elle peut retourner qui n'est pas un caractère, EOF. C'est une macro habituellement dÊfinie comme valant ?1. Donc, fgetc() retourne soit un char Êtendu à une valeur int (qui ressemble à 000000xx en hexa) soit EOF (qui ressemble à FFFFFFFF en hexa).
Le problème avec le programme de la Figure 2.2 est que fgetc() renvoie un int, mais cette valeur est stockÊe dans un char. Le C tronquera alors les bits de poids fort pour faire tenir la valeur de l'int dans le char. Le seul problème est que les nombres (en hexa) 000000FF et FFFFFFFF seront tous deux tronquÊs pour donner l'octet FF. Donc, la boucle while ne peut pas distinguer la lecture de l'octet FF dans le fichier et la fin de ce fichier.
Ce que fait exactement le code dans ce cas change selon que le char est signÊ ou non. Pourquoi ? Parce que ligne 2, ch est comparÊ avec EOF. Comme EOF est un int(11), ch sera Êtendu à un int afin que les deux valeurs comparÊes soient de la même taille(12). Comme la Figure 2.1 le montrait, le fait qu'une variable soit signÊe ou non est très important.
Si le char n'est pas signĂŠ, FF est ĂŠtendu et donne 000000FF. Cette valeur est comparĂŠe Ă EOF (FFFFFFFF) et est diffĂŠrente. Donc la boucle ne finit jamais !
Si le char est signĂŠ, FF est ĂŠtendu et donne FFFFFFFF. Les deux valeurs sont alors ĂŠgales et la boucle se termine. Cependant, comme l'octet FF peut avoir ĂŠtĂŠ lu depuis le fichier, la boucle peut se terminer prĂŠmaturĂŠment.
La solution à ce problème est de dÊfinir la variable ch comme un int, pas un char. Dans ce cas, aucune troncature ou extension n'est effectuÊe à la ligne 2. Dans la boucle, il est sans danger de tronquer la valeur puisque ch doit alors être rÊellement un octet.
III-A-3. ArithmĂŠtique en complĂŠment Ă 2▲
Comme nous l'avons vu plus tôt, l'instruction add effectue une addition et l'instruction sub effectue une soustraction. Deux des bits du registre EFLAGS que ces instructions positionnent sont overow (dÊpassement de capacitÊ) et carry ag (retenue). Le drapeau d'overow est à 1 si le rÊsultat rÊel de l'opÊration est trop grand et ne tient pas dans la destination pour l'arithmÊtique signÊe. Le drapeau de retenue est à 1 s'il y a une retenue dans le bit le plus significatif d'une addition d'une soustraction. Donc, il peut être utilisÊ pour dÊtecter un dÊpassement de capacitÊ en arithmÊtique non signÊe. L'utilisation du drapeau de retenue pour l'arithmÊtique signÊe va être vue sous peu. Un des grands avantages du complÊment à 2 est que les règles pour l'addition et la soustraction sont exactement les mêmes que pour les entiers non signÊs. Donc, add et sub peuvent être utilisÊes pour les entiers signÊs ou non.
002C 44
+ FFFF + (?1)
002B 43
Il y a une retenue de gĂŠnĂŠrĂŠe, mais elle ne fait pas partie de la rĂŠponse.
Il y a deux instructions de multiplication et de division diffÊrentes. Tout d'abord, pour multiplier, utilisez les instructions MUL ou IMUL. L'instruction MUL est utilisÊe pour multiplier les nombres non signÊs et IMUL est utilisÊe pour multiplier les entiers signÊs. Pourquoi deux instructions diffÊrentes sont nÊcessaires ? Les règles pour la multiplication sont diffÊrentes pour les nombres non signÊs et les nombres signÊs en complÊment à 2. Pourquoi cela ?
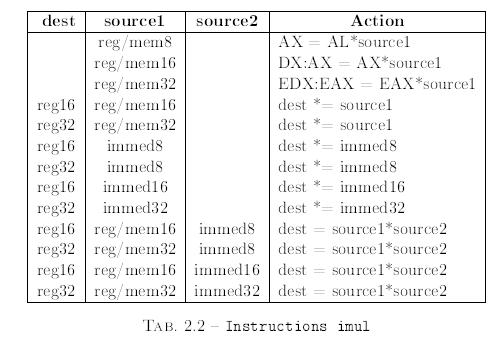
ConsidĂŠrons la multiplication de l'octet FF avec lui-mĂŞme donnant un rĂŠsultat sur un mot. En utilisant la multiplication non signĂŠe, il s'agit de 255 fois 255 soit 65 025 (ou FE01 en hexa). En utilisant la multiplication signĂŠe, il s'agit de ?1 fois ?1 soit 1 (ou 0001 en hexa).
Il y a plusieurs formes pour les instructions de multiplication. La plus ancienne ressemble Ă cela :
mul sourceLa source est soit un registre soit une rĂŠfĂŠrence mĂŠmoire. Cela ne peut pas ĂŞtre une valeur immĂŠdiate. Le type exact de la multiplication dĂŠpend de la taille de l'opĂŠrande source. Si l'opĂŠrande est un octet, elle est multipliĂŠe par l'octet situĂŠ dans le registre AL et le rĂŠsultat est stockĂŠ dans les 16 bits de AX. Si la source fait 16 bits, elle est multipliĂŠe par le mot situĂŠ dans AX et le rĂŠsultat 32 bits est stockĂŠ dans DX:AX. Si la source fait 32 bits, elle est multipliĂŠe par EAX et le rĂŠsultat 64 bits est stockĂŠ dans EDX:EAX.
L'instruction IMUL a les mĂŞmes formats que MUL, mais ajoute ĂŠgalement d'autres formats d'instruction. Il y a des formats Ă deux et Ă trois opĂŠrandes :
imul dest, source1
imul dest, source1, source2Le Tableau 2.2 montre les combinaisons possibles.
Les deux opÊrateurs de division sont DIV et IDIV. Ils effectuent respectivement une division entière non signÊe et une division entière signÊe. Le format gÊnÊral est :
div sourceSi la source est sur 8 bits, alors AX est divisÊ par l'opÊrande. Le quotient est stockÊ dans AL et le reste dans AH. Si la source est sur 16 bits, alors DX:AX est divisÊ par l'opÊrande. Le quotient est stockÊ dans AX et le reste dans DX. Si la source est sur 32 bits, alors EDX:EAX est divisÊ par l'opÊrande, le quotient est stockÊ dans EAX et le reste dans EDX. L'instruction IDIV fonctionne de la même façon. Il n'y a pas d'instructions IDIV spÊciales comme pour IMUL. Si le quotient est trop grand pour tenir dans son registre ou que le diviseur vaut 0, le programme et interrompu et se termine. Une erreur courante est d'oublier d'initialiser DX ou EDX avant la division.
L'instruction NEG inverse son opĂŠrande en calculant son complĂŠment Ă 2. L'opĂŠrande peut ĂŞtre n'importe quel registre ou emplacement mĂŠmoire sur 8 bits, 16 bits, or 32 bits.
III-A-4. Programme exemple▲
1 %include "asm_io.inc"
2 segment .data ; Chaines affichees
3 prompt db "Entrez un nombre : ", 0
4 square_msg db "Le carre de l'entree vaut ", 0
5 cube_msg db "Le cube de l'entree vaut ", 0
6 cube25_msg db "Le cube de l'entree fois 25 vaut ", 0
7 quot_msg db "Le quotient de cube/100 vaut ", 0
8 rem_msg db "Le reste de cube/100 vaut ", 0
9 neg_msg db "La nĂŠgation du reste vaut ", 0
10
11 segment .bss
12 input resd 1
13
14 segment .text
15 global _asm_main
16 _asm_main :
17 enter 0,0 ; routine d'initialisation
18 pusha
19
20 mov eax, prompt
21 call print_string
22
23 call read_int
24 mov [input], eax
25
26 imul eax ; edx:eax = eax * eax
27 mov ebx, eax ; sauvegarde le rĂŠsultat dans ebx
28 mov eax, square_msg
29 call print_string
30 mov eax, ebx
31 call print_int
32 call print_nl
33
34 mov ebx, eax
35 imul ebx, [input] ; ebx *= [entree]
36 mov eax, cube_msg
37 call print_string
38 mov eax, ebx
39 call print_int
40 call print_nl
41
42 imul ecx, ebx, 25 ; ecx = ebx*25
43 mov eax, cube25_msg
44 call print_string
45 mov eax, ecx
46 call print_int
47 call print_nl
48
49 mov eax, ebx
50 cdq ; initialise edx avec extension de signe
51 mov ecx, 100 ; on ne peut pas diviser par une valeur immĂŠdiate
52 idiv ecx ; edx:eax / ecx
53 mov ecx, eax ; sauvegarde le rĂŠsultat dans ecx
54 mov eax, quot_msg
55 call print_string
56 mov eax, ecx
57 call print_int
58 call print_nl
59 mov eax, rem_msg
60 call print_string
61 mov eax, edx
62 call print_int
63 call print_nl
64
65 neg edx ; inverse le reste
66 mov eax, neg_msg
67 call print_string
68 mov eax, edx
69 call print_int
70 call print_nl
71
72 popa
73 mov eax, 0 ; retour au C
74 leave
75 retIII-A-5. ArithmĂŠtique en prĂŠcision ĂŠtendue▲
Le langage assembleur fournit ĂŠgalement des instructions qui permettent d'effectuer des additions et des soustractions sur des nombres plus grands que des doubles mots. Ces instructions utilisent le drapeau de retenue. Comme nous l'avons dit plus haut, les instructions ADD et SUB modifient le drapeau de retenue si une retenue est gĂŠnĂŠrĂŠe. Cette information stockĂŠe dans le drapeau de retenue peut ĂŞtre utilisĂŠe pour additionner ou soustraire de grands nombres en morcelant l'opĂŠration en doubles-mots (ou plus petit).
Les instructions ADC et SBB utilisent les informations donnĂŠes par le drapeau de retenue. L'instruction ADC effectue l'opĂŠration suivante :
opĂŠrande1 = opĂŠrande1 + drapeau de retenue + opĂŠrande2
L'instruction SBB effectue :
opĂŠrande1 = opĂŠrande1 - drapeau de retenue - opĂŠrande2
Comment sont-elles utilisĂŠes ? ConsidĂŠrons la somme d'entiers 64 bits dans EDX:EAX et EBX:ECX. Le code suivant stockerait la somme dans EDX:EAX :
1 add eax, ecx ; additionne les 32 bits de poids faible
2 adc edx, ebx ; additionne les 32 bits de poids fort et la retenueLa soustraction est très similaire. Le code suivant soustrait EBX:ECX de EDX:EAX :
1 sub eax, ecx ; soustrait les 32 bits de poids faible
2 sbb edx, ebx ; soustrait les 32 bits de poids fort et la retenuePour les nombres vraiment grands, une boucle peut être utilisÊe (voir Section III.B). Pour une boucle de somme, il serait pratique d'utiliser l'instruction ADC pour toutes les itÊrations (au lieu de toutes sauf la première).
Cela peut ĂŞtre fait en utilisant l'instruction CLC (CLear Carry) juste avant que la boucle ne commence pour initialiser le drapeau de retenue Ă 0. Si le drapeau de retenue vaut 0, il n'y a pas de diffĂŠrence entre les instructions ADD et ADC. La mĂŞme idĂŠe peut ĂŞtre utilisĂŠe pour la soustraction.
III-B. Structures de contrĂ´le▲
Les langages de haut niveau fournissent des structures de contrôle de haut niveau (p.e., les instructions if et while) qui contrôlent le flot d'exÊcution. Le langage assembleur ne fournit pas de structures de contrôle aussi complexes. Il utilise à la place l'infâme goto et l'utiliser de manière inappropriÊe peut conduire à du code spaghetti ! Cependant, il est possible d'Êcrire des programmes structurÊs en assembleur. La procÊdure de base est de concevoir la logique du programme en utilisant les structures de contrôle de haut niveau habituelles et de traduire cette conception en langage assembleur (comme le ferait un compilateur).
III-B-1. Comparaison▲
Les structures de contrĂ´le dĂŠcident ce qu'il faut faire en comparant des donnĂŠes. En assembleur, le rĂŠsultat d'une comparaison est stockĂŠ dans le registre FLAGS pour ĂŞtre utilisĂŠ plus tard. Le 80x86 fournit l'instruction CMP pour effectuer des comparaisons. Le registre FLAGS est positionnĂŠ selon la diffĂŠrence entre les deux opĂŠrandes de l'instruction CMP. Les opĂŠrandes sont soustraits et le registre FLAGS est positionnĂŠ selon le rĂŠsultat, mais ce rĂŠsultat n'est stockĂŠ nulle part. Si vous avez besoin du rĂŠsultat, utilisez l'instruction SUB au lieu de CMP.
Pour les entiers non signĂŠs, il y a deux drapeaux (bits dans le registre FLAGS) qui sont importants : les drapeaux zĂŠro (ZF) et retenue (CF). Le drapeau zero est allumĂŠ (1) si le rĂŠsultat de la diffĂŠrence serait 0. ConsidĂŠrons une comparaison comme :
cmp vleft, vrightLa diffĂŠrence vleft - vright est calculĂŠe et les drapeaux sont positionnĂŠs en fonction. Si la diffĂŠrence calculĂŠe par CMP vaut 0, vleft = vright, alors ZF est allumĂŠ(i.e. 1) et CF est ĂŠteint (i.e. 0). Si vleft > vright, ZF est ĂŠteint et CF ĂŠgalement. Si vleft < vright, alors ZF est ĂŠteint et CF est allumĂŠ (retenue).
Pour les entiers signĂŠs, il y a trois drapeaux importants : le drapeau zĂŠro (ZF), le drapeau d'overow (OF) et le drapeau de signe (SF). Le drapeau d'overow est allumĂŠ si le rĂŠsultat d'une opĂŠration dĂŠpasse la capacitĂŠ (de trop ou de trop peu). Le drapeau de signe est allumĂŠ si le rĂŠsultat d'une opĂŠration est nĂŠgatif. Si vleft = vright, ZF est allumĂŠ (comme pour les entiers non signĂŠs). Si vleft > vright, ZF est ĂŠteint et SF = OF. Si vleft < vright, ZF est ĂŠteint et SF 6= OF.
N'oubliez pas que d'autres instructions peuvent aussi changer le registre FLAGS, pas seulement CMP.
Pourquoi SF = OF si vleft > vright ? S'il n'y
a pas d'overow, alors la diffĂŠrence aura la valeur correcte et doit ĂŞtre positive ou nulle. Donc, SF = OF = 0. Par contre, s'il y a un overow, la diffĂŠrence n'aura pas la valeur correcte (et sera en fait nĂŠgative).
Donc, SF = OF = 1.
III-B-2. Instructions de branchement▲
Les instructions de branchement peuvent transfĂŠrer l'exĂŠcution Ă n'importe quel point du programme. En d'autres termes, elles agissent comme un goto. Il y a deux types de branchements : conditionnel et inconditionnel. Un branchement inconditionnel est exactement comme un goto, il effectue toujours le branchement. Un branchement conditionnel peut effectuer le branchement ou non selon les drapeaux du registre FLAGS. Si un branchement conditionnel n'effectue pas le branchement, le contrĂ´le passe Ă l'instruction suivante.
L'instruction JMP (abrĂŠviation de jump) effectue les branchements inconditionnels.
Son seul argument est habituellement l'Êtiquette de code de l'instruction à laquelle se brancher. L'assembleur ou l'Êditeur de liens remplacera l'Êtiquette par l'adresse correcte de l'instruction. C'est une autre des opÊrations pÊnibles que l'assembleur fait pour rendre la vie du programmeur plus simple. Il est important de rÊaliser que l'instruction immÊdiatement après l'instruction JMP ne sera jamais exÊcutÊe à moins qu'une autre instruction ne se branche dessus !
Il y a plusieurs variantes de l'instruction de saut :
SHORT ce saut est très limitÊ en portÊe. Il ne peut bouger que de plus ou moins 128 octets en mÊmoire. L'avantage de ce type de saut est qu'il utilise moins de mÊmoire que les autres. Il utilise un seul octet signÊ pour stocker le dÊplacement du saut. Le dÊplacement est le nombre d'octets à sauter vers l'avant ou vers l'arrière (le dÊplacement est ajoutÊ à EIP). Pour spÊcifier un saut court, utilisez le mot-clÊ SHORT immÊdiatement avant l'Êtiquette dans l'instruction JMP ;
NEAR ce saut est le saut par dÊfaut, que ce soit pour les branchements inconditionnels ou conditionnels, il peut être utilisÊ pour sauter vers n'importe quel emplacement dans un segment. En fait, le 80386 supporte deux types de sauts proches. L'un utilise deux octets pour le dÊplacement. Cela permet de se dÊplacer en avant ou en arrière d'environ 32 000 octets. L'autre type utilise quatre octets pour le dÊplacement, ce qui, bien sÝr, permet de se dÊplacer n'importe oÚ dans le segment.
Le type de saut à deux octets peut être spÊcifiÊ en plaçant le mot-clÊ WORD avant l'Êtiquette dans l'instruction JMP.
FAR ce saut permet de passer le contrôle à un autre segment de code. C'est une chose très rare en mode protÊgÊ 386.
Les Êtiquettes de code valides suivent les mêmes règles que les Êtiquettes de donnÊes. Les Êtiquettes de code sont dÊfinies en les plaçant dans le segment de code au dÊbut de l'instruction qu'ils Êtiquettent. Deux points sont placÊs à la fin de l'Êtiquette lors de sa dÊfinition. Ces deux points ne font pas partie du nom.
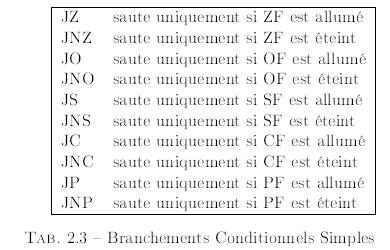
Il y a beaucoup d'instructions de branchement conditionnel diffĂŠrentes. Elles prennent toutes une ĂŠtiquette de code comme seul opĂŠrande. Les plus simples se contentent de regarder un drapeau dans le registre FLAGS pour dĂŠterminer si elles doivent sauter ou non. Voyez le Tableau 2.3 pour une liste de ces instructions (PF est le drapeau de paritĂŠ qui indique si le nombre de bits dans les 8 bits de poids faible du rĂŠsultat est pair ou impair).
Le pseudo-code suivant :
if ( EAX == 0 )
EBX = 1;
else
EBX = 2;peut être Êcrit de cette façon en assembleur :
1 cmp eax, 0 ; positionne les drapeaux (ZF allumĂŠ si eax - 0 = 0)
2 jz thenblock ; si ZF est allumĂŠ, branchement vers thenblock
3 mov ebx, 2 ; partie ELSE du IF
4 jmp next ; saute par dessus la partie THEN du IF
5 thenblock :
6 mov ebx, 1 ; partie THEN du IF
7 next :Les autres comparaisons ne sont pas si simples si l'on se contente des branchements conditionnels du Tableau 2.3. Pour illustrer, considĂŠrons le pseudo-code suivant :
if ( EAX >= 5 )
EBX = 1;
else
EBX = 2;Si EAX est plus grand ou ĂŠgal Ă 5, ZF peut ĂŞtre allumĂŠ ou non et SF sera ĂŠgal Ă OF. Voici le code assembleur qui teste ces conditions (en supposant que EAX est signĂŠ) :
1 cmp eax, 5
2 js signon ; goto signon si SF = 1
3 jo elseblock ; goto elseblock si OF = 1 et SF = 0
4 jmp thenblock ; goto thenblock si SF = 0 et OF = 0
5 signon:
6 jo thenblock ; goto thenblock si SF = 1 et OF = 1
7 elseblock :
8 mov ebx, 2
9 jmp next
10 thenblock:
11 mov ebx, 1
12 next:Le code ci-dessus est très confus. Heureusement, le 80x86 fournit des instructions de branchement additionnelles pour rendre ce type de test beaucoup plus simple. Il y a des versions signÊes et non signÊes de chacune.

Le Tableau 2.4 montre ces instructions. Les branchements ĂŠgal et non ĂŠgal (JE et JNE) sont les mĂŞmes pour les entiers signĂŠs et non signĂŠs (en fait, JE et JNE sont rĂŠellement identiques Ă JZ et JNZ, respectivement). Chacune des autres instructions de branchement a deux synonymes. Par exemple, regardez JL (jump less than, saut si infĂŠrieur Ă ) et JNGE (jump not greater than or equal to, saut si non plus grand ou ĂŠgal). Ce sont les mĂŞmes instructions, car :
x < y => not(x y)
Les branchements non signĂŠs utilisent A pour above (au-dessus) et B pour below (en dessous) Ă la place de L et G.
En utilisant ces nouvelles instructions de branchement, le pseudo-code ci-dessus peut ĂŞtre traduit en assembleur plus facilement.
1 cmp eax, 5
2 jge thenblock
3 mov ebx, 2
4 jmp next
5 thenblock:
6 mov ebx, 1
7 next:III-B-3. Les instructions de boucle▲
Le 80x86 fournit plusieurs instructions destinĂŠes Ă implĂŠmenter des boucles de style for. Chacune de ces instructions prend une ĂŠtiquette de code comme seul opĂŠrande.
LOOP dĂŠcrĂŠmente ECX, si ECX 6= 0, saute vers l'ĂŠtiquette.
LOOPE, LOOPZ dĂŠcrĂŠmente ECX (le registre FLAGS n'est pas modifiĂŠ), si ECX 6= 0 et ZF = 1, saute.
LOOPNE, LOOPNZ dĂŠcrĂŠmente ECX (FLAGS inchangĂŠ), si ECX 6= 0 et ZF = 0, saute.
Les deux dernières instructions de boucle sont utiles pour les boucles de recherche sÊquentielle. Le pseudo-code suivant :
sum = 0;
for ( i=10; i >0; i−− )
sum += i;peut être traduit en assembleur de la façon suivante ;
1 mov eax, 0 ; eax est sum
2 mov ecx, 10 ; ecx est i
3 loop_start:
4 add eax, ecx
5 loop loop_startIII-C. Traduire les structures de contrĂ´le standard▲
Cette section dĂŠcrit comment les structures de contrĂ´le standard des langages de haut niveau peuvent ĂŞtre implĂŠmentĂŠes en langage assembleur.
III-C-1. Instructions if▲
Le pseudo-code suivant :
if ( condition )
then_block;
else
else_block;peut être implÊmentÊ de cette façon :
1 ; code pour positionner FLAGS
2 jxx else_block ; choisir xx afin de sauter si la condition est fausse
3 ; code pour le bloc then
4 jmp endif
5 else_block :
6 ; code pour le bloc else
7 endif :S'il n'y a pas de else, le branchement else_block peut ĂŞtre remplacĂŠ par un branchement Ă endif.
1 ; code pour positionner FLAGS
2 jxx endif ; choisir xx afin de sauter si la condition est fausse
3 ; code pour le bloc then
4 endif :III-C-2. Boucles while▲
La boucle while est une boucle avec un test au dĂŠbut :
while( condition ) {
corps de la boucle;
}Cela peut ĂŞtre traduit en :
1 while :
2 ; code pour positionner FLAGS selon la condition
3 jxx endwhile ; choisir xx pour sauter si la condition est fausse
4 ; body of loop
5 jmp while
6 endwhile :III-C-3. Boucles do while▲
La boucle do while est une boucle avec un test Ă la fin :
do {
corps de la boucle;
} while( condition );Cela peut ĂŞtre traduit en :
1 do :
2 ; corps de la boucle
3 ; code pour positionner FLAGS selon la condition
4 jxx do ; choisir xx pour se brancher si la condition est vraieIII-D. Exemple : trouver des nombres premiers▲
Cette section dĂŠtaille un programme qui trouve des nombres premiers.
Rappelez-vous que les nombres premiers ne sont divisibles que par 1 et par eux-mĂŞmes. Il n'y a pas de formule pour les rechercher. La mĂŠthode de base qu'utilise ce programme est de rechercher les diviseurs de tous les nombres impairs(13) sous une limite donnĂŠe. Si aucun facteur ne peut ĂŞtre trouvĂŠ pour un nombre impair, il est premier. Voici l'algorithme de base ĂŠcrit en C.
1 unsigned guess; / candidat courant pour ĂŞtre premier /
2 unsigned factor ; / diviseur possible de guess /
3 unsigned limit ; / rechercher les nombres premiers jusqu'Ă cette valeur /
4
5 printf ("Rechercher les nombres premiers jusqu'a : ");
6 scanf("%u", &limit);
7 printf ("2\n"); / traite les deux premiers nombres premiers comme /
8 printf ("3\n"); / des cas spĂŠciaux /
9 guess = 5; / candidat initial /
10 while ( guess <= limit ) {
11 / recherche un diviseur du candidat /
12 factor = 3;
13 while ( factor factor < guess &&
14 guess % factor != 0 )
15 factor += 2;
16 if ( guess % factor != 0 )
17 printf ("%d\n", guess);
18 guess += 2; / ne regarder que les nombres impairs /
19 }Voici la version assembleur :
1 %include "asm_io.inc"
2 segment .data
3 Message db "Rechercher les nombres premiers jusqu'a : ", 0
4
5 segment .bss
6 Limit resd 1 ; rechercher les nombres premiers jusqu'Ă cette limite
7 Guess resd 1 ; candidat courant pour ĂŞtre premier
8
9 segment .text
10 global _asm_main
11 _asm_main :
12 enter 0,0 ; routine d'initialisation
13 pusha
14
15 mov eax, Message
16 call print_string
17 call read_int ; scanf("%u", &limit);
18 mov [Limit], eax
19
20 mov eax, 2 ; printf("2\n");
21 call print_int
22 call print_nl
23 mov eax, 3 ; printf("3\n");
24 call print_int
25 call print_nl
26
27 mov dword [Guess], 5 ; Guess = 5;
28 while_limit : ; while ( Guess <= Limit )
29 mov eax,[Guess]
30 cmp eax, [Limit]
31 jnbe end_while_limit ; on utilise jnbe, car les nombres ne sont pas signes
32
33 mov ebx, 3 ; ebx est factor = 3;
34 while_factor:
35 mov eax,ebx
36 mul eax ; edx:eax = eax*eax
37 jo end_while_factor ; si la rĂŠponse ne tient pas dans eax seul
38 cmp eax, [Guess]
39 jnb end_while_factor ; si !(factor*factor < guess)
40 mov eax,[Guess]
41 mov edx,0
42 div ebx ; edx = edx:eax % ebx
43 cmp edx, 0
44 je end_while_factor ; si !(guess % factor != 0)
45
46 add ebx,2 ; factor += 2;
47 jmp while_factor
48 end_while_factor:
49 je end_if ; si !(guess % factor != 0)
50 mov eax,[Guess] ; printf("%u\n")
51 call print_int
52 call print_nl
53 end_if :
54 add dword [Guess], 2 ; guess += 2
55 jmp while_limit
56 end_while_limit:
57
58 popa
59 mov eax, 0 ; retour au C
60 leave
61 retIV. OpĂŠrations sur les bits▲
IV-A. OpĂŠrations de dĂŠcalage▲
Le langage assembleur permet au programmeur de manipuler individuellement les bits des donnĂŠes. Une opĂŠration courante sur les bits est appelĂŠe dĂŠcalage. Une opĂŠration de dĂŠcalage dĂŠplace la position des bits d'une donnĂŠe. Les dĂŠcalages peuvent ĂŞtre soit vers la gauche (i.e. vers les bits les plus significatifs) soit vers la droite (les bits les moins significatifs).
IV-A-1. DĂŠcalages logiques▲
Le dÊcalage logique est le type le plus simple de dÊcalage. Il dÊcale d'une manière très simple. La Figure 3.1 montre l'exemple du dÊcalage d'un nombre sur un octet.
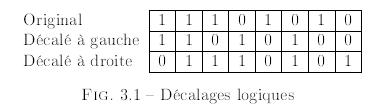
Notez que les nouveaux bits sont toujours Ă 0. Les instructions SHL et SHR sont respectivement utilisĂŠes pour dĂŠcaler Ă gauche et Ă droite. Ces instructions permettent de dĂŠcaler de n'importe quel nombre de positions.
Le nombre de positions Ă dĂŠcaler peut soit ĂŞtre une constante, soit ĂŞtre stockĂŠ dans le registre CL. Le dernier bit dĂŠcalĂŠ de la donnĂŠe est stockĂŠ dans le drapeau de retenue. Voici quelques exemples :
1 mov ax, 0C123H
2 shl ax, 1 ; dĂŠcale d'1 bit Ă gauche, ax = 8246H, CF = 1
3 shr ax, 1 ; dĂŠcale d'1 bit Ă droite, ax = 4123H, CF = 0
4 shr ax, 1 ; dĂŠcale d'1 bit Ă droite, ax = 2091H, CF = 1
5 mov ax, 0C123H
6 shl ax, 2 ; dĂŠcale de 2 bits Ă gauche, ax = 048CH, CF = 1
7 mov cl, 3
8 shr ax, cl ; dĂŠcale de 3 bits Ă droite, ax = 0091H, CF = 1IV-A-2. Utilisation des dĂŠcalages▲
La multiplication et la division rapides sont les utilisations les plus courantes des opÊrations de dÊcalage. Rappelez-vous que dans le système dÊcimal, la multiplication et la division par une puissance de dix sont simples, on dÊcale simplement les chiffres. C'est Êgalement vrai pour les puissances de deux en binaire. Par exemple, pour multiplier par deux le nombre binaire 10112 (ou 11 en dÊcimal), dÊcalez d'un cran vers la gauche pour obtenir 101102 (ou 22). Le quotient d'une division par une puissance de 2 est le rÊsultat d'un dÊcalage à droite. Pour diviser par 2, utilisez un dÊcalage d'une position à droite ; pour diviser par 4 (22), dÊcalez à droite de deux positions ; pour diviser par 8 (23), dÊcalez de 3 positions vers la droite, etc. Les instructions de dÊcalage sont très basiques et sont beaucoup plus rapides que les instructions MUL et DIV correspondantes !
En fait, les dĂŠcalages logiques peuvent ĂŞtre utilisĂŠs pour multiplier ou diviser des valeurs non signĂŠes. Ils ne fonctionnent gĂŠnĂŠralement pas pour les valeurs signĂŠes. ConsidĂŠrons la valeur sur deux octets FFFF (?1 signĂŠ). Si on lui applique un dĂŠcalage logique d'une position vers la droite, le rĂŠsultat est 7FFF ce qui fait +32 767 ! Un autre type de dĂŠcalage doit ĂŞtre utilisĂŠ pour les valeurs signĂŠes.
IV-A-3. DĂŠcalages arithmĂŠtiques▲
Ces dÊcalages sont conçus pour permettre à des nombres signÊs d'être rapidement multipliÊs et divisÊs par des puissances de 2. Ils assurent que le bit de signe est traitÊ correctement.
SAL Shift Arithmetic Left (dĂŠcalage arithmĂŠtique Ă gauche) - Cette instruction est juste un synonyme pour SHL. Elle est assemblĂŠe pour donner exactement le mĂŞme code machine que SHL. Tant que le bit de signe n'est pas changĂŠ par le dĂŠcalage, le rĂŠsultat sera correct.
SAR Shift Arithmetic Right (dĂŠcalage arithmĂŠtique Ă droite) - C'est une nouvelle instruction qui ne dĂŠcale pas le bit de signe (i.e. le msb) de son opĂŠrande. Les autres bits sont dĂŠcalĂŠs normalement sauf que les nouveaux bits qui entrent par la gauche sont des copies du bit de signe (c'est-Ă -dire que si le bit de signe est Ă 1, les nouveaux bits sont ĂŠgalement Ă 1). Donc, si un octet est dĂŠcalĂŠ avec cette instruction, seuls les 7 bits de poids faible sont dĂŠcalĂŠs. Comme pour les autres dĂŠcalages, le dernier bit sorti est stockĂŠ dans le drapeau de retenue.
1 mov ax, 0C123H
2 sal ax, 1 ; ax = 8246H, CF = 1
3 sal ax, 1 ; ax = 048CH, CF = 1
4 sar ax, 2 ; ax = 0123H, CF = 0IV-A-4. DĂŠcalages circulaires▲
Les instructions de dĂŠcalage circulaire fonctionnent comme les dĂŠcalages logiques exceptĂŠ que les bits perdus Ă un bout sont rĂŠintĂŠgrĂŠs Ă l'autre. Donc, la donnĂŠe est traitĂŠe comme s'il s'agissait d'une structure circulaire. Les deux instructions de rotation les plus simples sont ROL et ROR qui effectuent des rotations Ă gauche et Ă droite, respectivement. Comme pour les autres dĂŠcalages, ceux-ci laissent une copie du dernier bit sorti dans le drapeau de retenue.
1 mov ax, 0C123H
2 rol ax, 1 ; ax = 8247H, CF = 1
3 rol ax, 1 ; ax = 048FH, CF = 1
4 rol ax, 1 ; ax = 091EH, CF = 0
5 ror ax, 2 ; ax = 8247H, CF = 1
6 ror ax, 1 ; ax = C123H, CF = 1Il y a deux instructions de rotation supplĂŠmentaires qui dĂŠcalent les bits de la donnĂŠe et le drapeau de retenue appelĂŠs RCL et RCR. Par exemple, si on applique au registre AX une rotation avec ces instructions, elle est appliquĂŠe aux 17 bits constituĂŠs de AX et du drapeau de retenue.
1 mov ax, 0C123H
2 clc ; eteint le drapeau de retenue (CF = 0)
3 rcl ax, 1 ; ax = 8246H, CF = 1
4 rcl ax, 1 ; ax = 048DH, CF = 1
5 rcl ax, 1 ; ax = 091BH, CF = 0
6 rcr ax, 2 ; ax = 8246H, CF = 1
7 rcr ax, 1 ; ax = C123H, CF = 0IV-A-5. Application simple▲
Voici un extrait de code qui compte le nombre de bits qui sont allumĂŠs (i.e. Ă 1) dans le registre EAX.
1 mov bl, 0 ; bl contiendra le nombre de bits ALLUMES
2 mov ecx, 32 ; ecx est le compteur de boucle
3 count_loop:
4 shl eax, 1 ; decale un bit dans le drapeau de retenue
5 jnc skip_inc ; si CF == 0, goto skip_inc
6 inc bl
7 skip_inc :
8 loop count_loopLe code ci-dessus dĂŠtruit la valeur originale de EAX (EAX vaut zĂŠro Ă la fin de la boucle). Si l'on voulait conserver la valeur de EAX, la ligne 4 pourrait ĂŞtre remplacĂŠe par rol eax, 1.
IV-B. OpĂŠrations boolĂŠennes niveau bit▲
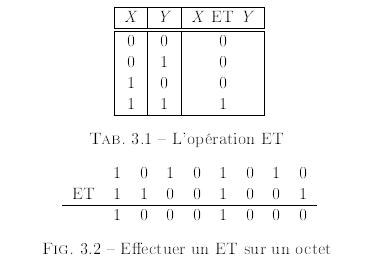
Il y a quatre opĂŠrateurs boolĂŠens courants : AND, OR, XOR et NOT. Une table de vĂŠritĂŠ montre le rĂŠsultat de chaque opĂŠration pour chaque valeur possible de ses opĂŠrandes.
IV-B-1. L'opĂŠration ET▲
Le rĂŠsultat d'un ET sur deux bits vaut 1 uniquement si les deux bits sont Ă 1, sinon, le rĂŠsultat vaut 0, comme le montre la table de vĂŠritĂŠ du Tableau 3.1.
Les processeurs supportent ces opÊrations comme des instructions agissant de façon indÊpendante sur tous les bits de la donnÊe en parallèle. Par exemple, si on applique un ET au contenu de AL et BL, l'opÊration ET de base est appliquÊe à chacune des 8 paires de bits correspondantes dans les deux registres, comme le montre la Figure 3.2. Voici un exemple de code :
1 mov ax, 0C123H
2 and ax, 82F6H ; ax = 8022HIV-B-2. L'opĂŠration OU▲
Le OU de 2 bits vaut 0 uniquement si les deux bits valent 0, sinon le rĂŠsultat vaut 1 comme le montre la table de vĂŠritĂŠ du Tableau 3.2. Voici un exemple de code :
1 mov ax, 0C123H
2 or ax, 0E831H ; ax = E933HIV-B-3. L'opĂŠration XOR▲
Le OU exclusif de deux bits vaut 0 uniquement si les deux bits sont ĂŠgaux, sinon, le rĂŠsultat vaut 1 comme le montre la table de vĂŠritĂŠ du Tableau 3.3.
Voici un exemple de code :
1 mov ax, 0C123H
2 xor ax, 0E831H ; ax = 2912HIV-B-4. L'opĂŠration NOT▲

L'opĂŠration NOT est une opĂŠration unaire (i.e. elle agit sur un seul opĂŠrande, pas deux comme les opĂŠrations binaires de type ET). Le NOT d'un bit est la valeur opposĂŠe du bit comme le montre la table de vĂŠritĂŠ du Tableau 3.4. Voici un exemple de code :
1 mov ax, 0C123H
2 not ax ; ax = 3EDCHNotez que le NOT donne le complĂŠment Ă un. Contrairement aux autres opĂŠrations niveau bit, l'instruction NOT ne change aucun des bits du registre FLAGS.
IV-B-5. L'instruction TEST▲
L'instruction TEST effectue une opÊration AND, mais ne stocke pas le rÊsultat. Elle positionne le registre FLAGS selon ce que ce dernier aurait ÊtÊ après un AND (comme l'instruction CMP qui effectue une soustraction, mais ne fait que positionner FLAGS). Par exemple, si le rÊsultat Êtait zÊro, ZF serait allumÊ.
IV-B-6. Utilisation des opĂŠrations sur les bits▲
Les opÊrations sur les bits sont très utiles pour manipuler individuellement les bits d'une donnÊe sans modifier les autres bits. Le Tableau 3.5 montre trois utilisations courantes de ces opÊrations.

Voici un exemple de code, implĂŠmentant ces idĂŠes.
1 mov ax, 0C123H
2 or ax, 8 ; allumer le bit 3, ax = C12BH
3 and ax, 0FFDFH ; ĂŠteindre le bit 5, ax = C10BH
4 xor ax, 8000H ; inverser le bit 31, ax = 410BH
5 or ax, 0F00H ; allumer un quadruplet, ax = 4F0BH
6 and ax, 0FFF0H ; ĂŠteindre un quadruplet, ax = 4F00H
7 xor ax, 0F00FH ; inverser des quadruplets, ax = BF0FH
8 xor ax, 0FFFFH ; complĂŠment Ă 1, ax = 40F0HL'opĂŠration ET peut aussi ĂŞtre utilisĂŠe pour trouver le reste d'une division par une puissance de deux. Pour trouver le reste d'une division par 2i, effectuez un ET sur le nombre avec un masque valant 2i ? 1. Ce masque contiendra des 1 du bit 0 au bit i?1. Ce sont tout simplement ces bits qui correspondent au reste. Le rĂŠsultat du ET conservera ces bits et mettra les autres Ă zĂŠro. Voici un extrait de code qui trouve le quotient et le reste de la division de 100 par 16.
1 mov eax, 100 ; 100 = 64H
2 mov ebx, 0000000FH ; masque = 16 - 1 = 15 ou F
3 and ebx, eax ; ebx = reste = 4En utilisant le registre CL il est possible de modifier n'importe quel(s) bit(s) d'une donnĂŠe. Voici un exemple qui allume un bit de EAX. Le numĂŠro du bit Ă allumer est stockĂŠ dans BH.
1 mov cl, bh ; tout d'abord, construire le nombre pour le OU
2 mov ebx, 1
3 shl ebx, cl ; dĂŠcalage Ă gauche cl fois
4 or eax, ebx ; allume le bitĂteindre un bit est un tout petit peut plus dur.
1 mov cl, bh ; tout d'abord, construire le nombre pour le ET
2 mov ebx, 1
3 shl ebx, cl ; dĂŠcalage Ă gauche cl fois
4 not ebx ; inverse les bits
5 and eax, ebx ; ĂŠteint le bitLe code pour inverser un bit est laissĂŠ en exercice au lecteur.
Il n'est pas rare de voir l'instruction dĂŠroutante suivante dans un programme 80x86 :
xor eax, eax ; eax = 0Un nombre auquel on applique un XOR avec lui-mĂŞme donne toujours zĂŠro.
Cette instruction est utilisĂŠe, car son code machine est plus petit que l'instruction MOV correspondante.
IV-C. Ăviter les branchements conditionnels▲
Les processeurs modernes utilisent des techniques très sophistiquÊes pour exÊcuter le code le plus rapidement possible. Une technique rÊpandue est appelÊe exÊcution spÊculative. Cette technique utilise les possibilitÊs de traitement en parallèle du processeur pour exÊcuter plusieurs instructions à la fois. Les branchements conditionnels posent un problème à ce type de fonctionnement.
Le processeur, en gĂŠnĂŠral, ne sait pas si le branchement sera effectuĂŠ ou pas. Selon qu'il est effectuĂŠ ou non, un ensemble d'instructions diffĂŠrent sera exĂŠcutĂŠ. Les processeurs essaient de prĂŠvoir si le branchement sera effectuĂŠ. Si la prĂŠvision est mauvaise, le processeur a perdu son temps en exĂŠcutant le mauvais code.
Une façon d'Êviter ce problème est d'Êviter d'utiliser les branchements conditionnels lorsque c'est possible. Le code d'exemple de III.A.5 fournit un exemple simple de la façon de le faire. Dans l'exemple prÊcÊdent, les bits allumÊs du registre EAX sont dÊcomptÊs. Il utilise un branchement pour Êviter l'instruction INC. La Figure 3.3 montre comment le branchement peut être retirÊ en utilisant l'instruction ADC pour ajouter directement le drapeau de retenue.

Les instructions SETxx fournissent un moyen de retirer les branchements dans certains cas. Ces instructions positionnent la valeur d'un registre ou d'un emplacement mÊmoire d'un octet à zÊro ou à un selon l'Êtat du registre FLAGS. Les caractères après SET sont les mêmes que pour les branchements conditionnels. Si la condition correspondante au SETxx est vraie, le rÊsultat stockÊ est un, s'il est faux, zÊro est stockÊ. Par exemple :
setz al ; AL = 1 si ZF est allume, sinon 0En utilisant ces instructions, il est possible de dĂŠvelopper des techniques ingĂŠnieuses qui calculent des valeurs sans branchement.
Par exemple, considÊrons le problème de la recherche de la plus grande de deux valeurs. L'approche standard pour rÊsoudre ce problème serait d'utiliser un CMP et un branchement conditionnel pour dÊterminer la valeur la plus grande. Le programme exemple ci-dessous montre comment le maximum peut être trouvÊ sans utiliser aucun branchement.
1 ; file : max.asm
2 %include "asm_io.inc"
3 segment .data
4
5 message1 db "Entrez un nombre : ",0
6 message2 db "Entrez un autre nombre : ", 0
7 message3 db "Le plus grand nombre est : ", 0
8
9 segment .bss
10
11 input1 resd 1 ; premier nombre entre
12
13 segment .text
14 global _asm_main
15 _asm_main :
16 enter 0,0 ; routine d'initialisation
17 pusha
18
19 mov eax, message1 ; affichage du premier message
20 call print_string
21 call read_int ; saisie du premier nombre
22 mov [input1], eax
23
24 mov eax, message2 ; affichage du second message
25 call print_string
26 call read_int ; saisie du second nombre (dans eax)
27
28 xor ebx, ebx ; ebx = 0
29 cmp eax, [input1] ; compare le premier et le second nombre
30 setg bl ; ebx = (input2 > input1) ? 1 : 0
31 neg ebx ; ebx = (input2 > input1) ? 0xFFFFFFFF : 0
32 mov ecx, ebx ; ecx = (input2 > input1) ? 0xFFFFFFFF : 0
33 and ecx, eax ; ecx = (input2 > input1) ? input2 : 0
34 not ebx ; ebx = (input2 > input1) ? 0 : 0xFFFFFFFF
35 and ebx, [input1] ; ebx = (input2 > input1) ? 0 : input1
36 or ecx, ebx ; ecx = (input2 > input1) ? input2 : input1
37
38 mov eax, message3 ; affichage du rĂŠsultat
39 call print_string
40 mov eax, ecx
41 call print_int
42 call print_nl
43
44 popa
45 mov eax, 0 ; retour au C
46 leave
47 retL'astuce est de crĂŠer un masque de bits qui peut ĂŞtre utilisĂŠ pour sĂŠlectionner la valeur correcte pour le maximum. L'instruction SETG Ă la ligne 30 positionne BL Ă 1 si la seconde saisie est la plus grande ou Ă 0 sinon. Ce n'est pas le masque de bits dĂŠsirĂŠ.
Pour crĂŠer le masque nĂŠcessaire, la ligne 31 utilise l'instruction NEG sur le registre EBX (notez que EBX a ĂŠtĂŠ positionnĂŠ Ă 0 prĂŠcĂŠdemment). Si EBX vaut 0, cela ne fait rien ; cependant, si EBX vaut 1, le rĂŠsultat est la reprĂŠsentation en complĂŠment Ă 2 de -1 soit 0xFFFFFFFF. C'est exactement le masque de bits dĂŠsirĂŠ.
Le code restant utilise ce masque de bits pour sĂŠlectionner la saisie correspondant au plus
grand nombre.
Une autre astuce est d'utiliser l'instruction DEC. Dans le code ci-dessus, si NEG est remplacĂŠ par DEC, le rĂŠsultat sera ĂŠgalement 0 ou 0xFFFFFFFF. Cependant, les valeurs sont inversĂŠes par rapport Ă l'utilisation de l'instruction NEG.
IV-D. Manipuler les bits en C▲
IV-D-1. Les opĂŠrateurs niveau bit du C▲
Contrairement Ă certains langages de haut niveau, le C fournit des opĂŠrateurs pour les opĂŠrations niveau bit. L'opĂŠration ET est reprĂŠsentĂŠe par l'opĂŠrateur binaire &(14). L'opĂŠration OU est reprĂŠsentĂŠe par l'opĂŠrateur binaire |. L'opĂŠration XOR est reprĂŠsentĂŠe par l'opĂŠrateur binaire ^ . Et l'opĂŠration NOT est reprĂŠsentĂŠe par l'opĂŠrateur unaire ~ .
Les opĂŠrations de dĂŠcalage sont effectuĂŠes au moyen des opĂŠrateurs binaires et du C. L'opĂŠrateur effectue les dĂŠcalages Ă gauche et l'opĂŠrateur effectue les dĂŠcalages Ă droite. Ces opĂŠrateurs prennent deux opĂŠrandes. L'opĂŠrande de gauche est la valeur Ă dĂŠcaler et l'opĂŠrande de droite est le nombre de bits Ă dĂŠcaler. Si la valeur Ă dĂŠcaler est d'un type non signĂŠ, un dĂŠcalage logique est effectuĂŠ. Si la valeur est d'un type signĂŠ (comme int), alors un dĂŠcalage arithmĂŠtique est utilisĂŠ. Voici un exemple en C utilisant ces opĂŠrateurs :
1 short int s ; / on suppose que les short int font 16 bits /
2 short unsigned u;
3 s = −1; / s = 0xFFFF (complement a 2) /
4 u = 100; / u = 0x0064 /
5 u = u | 0x0100; / u = 0x0164 /
6 s = s & 0xFFF0; / s = 0xFFF0 /
7 s = s ^ u; / s = 0xFE94 /
8 u = u << 3; / u = 0x0B20 (dĂŠcalage logique) /
9 s = s >> 2; / s = 0xFFA5 (dĂŠcalage arithmetique) /IV-D-2. Utiliser les opĂŠrateurs niveau bit en C▲
Les opĂŠrateurs niveau bit sont utilisĂŠs en C pour les mĂŞmes raisons qu'ils le sont en assembleur. Ils permettent de manipuler les bits d'une donnĂŠe individuellement et peuvent ĂŞtre utilisĂŠs pour des multiplications et des divisions rapides. En fait, un compilateur C malin utilisera automatiquement un dĂŠcalage pour une multiplication du type x *= 2.
Beaucoup d'API(15) de systèmes d'exploitation (comme POSIX(16) et Win32) contiennent des fonctions qui utilisent des opÊrandes donc les donnÊes sont codÊes sous la forme de bits. Par exemple, les systèmes POSIX conservent les permissions sur les fichiers pour trois diffÊrents types d'utilisateurs : utilisateur (un nom plus appropriÊ serait propriÊtaire), groupe et autres. Chaque type d'utilisateur peut recevoir la permission de lire, Êcrire et/ou exÊcuter un fichier. Pour changer les permissions d'un fichier, le programmeur C doit manipuler des bits individuels. POSIX dÊfinit plusieurs macros pour l'aider (voir Tableau 3.6).
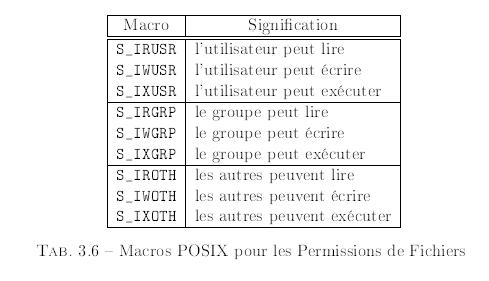
La fonction chmod peut être utilisÊe pour dÊfinir les permissions sur un fichier. Cette fonction prend deux paramètres, une chaine avec le nom du fichier à modifier et un entier(17) avec les bits appropriÊs d'allumÊs pour les permissions dÊsirÊes. Par exemple, le code ci-dessous dÊfinit les permissions pour permettre au propriÊtaire du fichier de lire et d'Êcrire dedans, au groupe de lire le fichier et d'interdire l'accès aux autres.
chmod("foo", S_IRUSR | S_IWUSR | S_IRGRP );La fonction POSIX stat peut ĂŞtre utilisĂŠe pour rĂŠcupĂŠrer les bits de permission en cours pour un fichier. En l'utilisant avec la fonction chmod,
il est possible de modifier certaines des permissions sans changer les autres.
Voici un exemple qui retire l'accès en Êcriture aux autres et ajoute les droits de lecture pour le propriÊtaire. Les autres permissions ne sont pas altÊrÊes.
1 struct stat le_stats ; / structure utilisee par stat () /
2 stat ("foo", & le_stats ); / lit les infos du fichier
3 le_stats .st_mode contient les bits de permission /
4 chmod("foo", ( le_stats .st_mode & ~S_IWOTH) | S_IRUSR);IV-E. ReprĂŠsentations big et little endian▲
Le Chapitre II a introduit les concepts de reprĂŠsentations big et little endian des donnĂŠes multioctets. Cependant, l'auteur s'est rendu compte que pour beaucoup de gens, ce sujet est confus. Cette section couvre le sujet plus en dĂŠtail.
Le lecteur se souvient sÝrement que le caractère big ou little endian fait rÊfÊrence à l'ordre dans lequel les octets (pas les bits) d'un ÊlÊment de donnÊes multioctets sont stockÊs en mÊmoire. La reprÊsentation big endian est la mÊthode la plus intuitive. Elle stocke l'octet le plus significatif en premier, puis le second octet le plus significatif, etc. En d'autres termes, les gros (big) bits sont stockÊs en premier. La mÊthode little endian stocke les octets dans l'ordre inverse (moins significatif en premier). La famille des processeurs x86 utilise la reprÊsentation little endian.
Par exemple, considĂŠrons le double mot reprĂŠsentant 1234567816. En reprĂŠsentation big endian, les octets seraient stockĂŠs 12 34 56 78. En reprĂŠsentation little endian, les octets seraient stockĂŠs 78 56 34 12.
Le lecteur est probablement en train de se demander pourquoi n'importe quel concepteur de puce sain d'esprit utiliserait la reprĂŠsentation little endian ?
Les ingĂŠnieurs de chez Intel ĂŠtaient-ils sadiques pour infliger Ă une multitude de programmeurs cette reprĂŠsentation qui prĂŞte Ă confusion ? Il peut sembler que le processeur ait Ă faire du travail supplĂŠmentaire pour stocker les octets en mĂŠmoire dans l'ordre inverse (et pour les rĂŠinverser lorsqu'il lit Ă partir de la mĂŠmoire). En fait, le processeur ne fait aucun travail supplĂŠmentaire pour lire et ĂŠcrire en mĂŠmoire en utilisant le format little endian. Il faut comprendre que le processeur est constituĂŠ de beaucoup de circuits ĂŠlectroniques qui ne travaillent que sur des valeurs de un bit. Les bits (et les octets) peuvent ĂŞtre dans n'importe quel ordre dans le processeur.
ConsidÊrons le registre de deux octets AX. Il peut être dÊcomposÊ en deux registres d'un octet : AH et AL. Il y a des circuits dans le processeur qui conservent les valeurs de AH and AL. Ces circuits n'ont pas d'ordre dans le processeur. C'est-à -dire que les circuits pour AH ne sont pas avant ou après les circuits pour AL. Une instruction MOV qui copie la valeur de AX en mÊmoire copie la valeur de AL puis de AH. Ce n'est pas plus dur pour le processeur que de stocker AH en premier.
Le même argument s'applique aux bits individuels d'un octet. Ils ne sont pas rÊellement dans un ordre dÊterminÊ dans les circuits du processeur (ou en mÊmoire en ce qui nous concerne). Cependant, comme les bits individuels ne peuvent pas être adressÊs dans le processeur ou en mÊmoire, il n'y a pas de façon de savoir (et aucune raison de s'en soucier) l'ordre dans lequel ils sont conservÊs à l'intÊrieur du processeur.
Le code C de la Figure 3.4 montre comment le caractère big ou little endian d'un processeur peut être dÊterminÊ.

Le pointeur p traite la variable word comme un tableau de caractères de deux ÊlÊments. Donc, p[0] correspond au premier octet de word en mÊmoire dont la valeur dÊpend du caractère big ou little endian du processeur.
IV-E-1. Quand se soucier du caractère big ou little endian▲
Pour la programmation courante, le caractère big ou little endian du processeur n'est pas important. Le moment le plus courant oÚ cela devient important est lorsque des donnÊes binaires sont transfÊrÊes entre diffÊrents systèmes informatiques. Cela se fait habituellement en utilisant un type quelconque de mÊdia physique (comme un disque) ou via un rÊseau. Comme les donnÊes ASCII sont sur un seul octet, le caractère big ou little endian n'est pas un problème.
Avec l'avènement des jeux de caractères multioctets comme UNICODE, le caractère big ou little endian devient important même pour les donnÊes texte. UNICODE supporte les deux types de reprÊsentation et a un mÊcanisme pour indiquer celle qui est utilisÊe pour reprÊsenter les donnÊes.
Tous les en-tĂŞtes internes de TCP/IP stockent les entiers au format big
endian (appelÊ ordre des octets rÊseau). Les bibliothèques TCP/IP offrent des fonctions C pour rÊsoudre les problèmes de reprÊsentation big ou little endian d'une façon portable. Par exemple, la fonction htonl () convertit un double-mot (ou un entier long) depuis le format hôte vers le format rÊseau.
La fonction function ntohl () effectue la transformation inverse(18). Pour un système big endian les deux fonctions retournent leur paramètre inchangÊ. Cela permet d'Êcrire des programmes rÊseau qui compileront et s'exÊcuteront correctement sur n'importe quel système sans tenir compte de la reprÊsentation utilisÊe. Pour plus d'information sur les reprÊsentations big et little endian et la programmation rÊseau, voyez l'excellent livre de W. Richard Steven : UNIX Network Programming.
La Figure 3.5 montre une fonction C qui passe d'une reprĂŠsentation Ă l'autre pour un double mot.

Le processeur 486 a introduit une nouvelle instruction machine appelĂŠe BSWAP qui inverse les octets de n'importe quel registre 32 bits. Par exemple,
bswap edx ; ĂŠchange les octets de edxL'instruction ne peut pas ĂŞtre utilisĂŠe sur des registres de 16 bits. Cependant, l'instruction XCHG peut ĂŞtre utilisĂŠe pour ĂŠchanger les octets des registres 16 bits pouvant ĂŞtre dĂŠcomposĂŠs en registres de 8 bits. Par exemple :
xchg ah,al ; ĂŠchange les octets de axIV-F. Compter les bits▲
Plus haut, nous avons donnĂŠ une technique intuitive pour compter le nombre de bits allumĂŠs dans un double-mot. Cette section dĂŠcrit d'autres mĂŠthodes moins directes de le faire pour illustrer les opĂŠrations sur les bits dont nous avons parlĂŠ dans ce chapitre.
IV-F-1. MĂŠthode une▲
La première mÊthode est très simple, mais pas Êvidente. La Figure 3.6 en montre le code.

Comment fonctionne cette mĂŠthode ? Ă chaque itĂŠration de la boucle, un bit est ĂŠteint dans data. Quand tous les bits sont ĂŠteints ((i.e. lorsque data vaut zĂŠro), la boucle s'arrĂŞte. Le nombre d'itĂŠrations requises pour mettre data Ă zĂŠro est ĂŠgal au nombre de bits dans la valeur originale de data.
La ligne 6 est l'endroit oÚ un bit de data est Êteint. Comment cela marche ? ConsidÊrons la forme gÊnÊrale de la reprÊsentation binaire de data et le 1 le plus à droite dans cette reprÊsentation. Par dÊnifition, chaque bit après ce 1 est à zÊro. Maintenant, que sera la reprÊsentation de data - 1 ? Les bits à gauche du 1 le plus à droite seront les mêmes que pour data, mais à partir du 1 le plus à droite, les bits seront les complÊments des bits originaux de data. Par exemple :
data = xxxxx10000
data - 1 = xxxxx01111
oĂš les x sont les mĂŞmes pour les deux nombres. Lorsque l'on applique un ET sur data avec data - 1, le rĂŠsultat mettra le 1 le plus Ă droite de data Ă zĂŠro et laissera les autres bits inchangĂŠs.
IV-F-2. MĂŠthode deux▲
Un tableau de recherche peut ĂŠgalement ĂŞtre utilisĂŠ pour contrer les bits de n'importe quel double-mot. L'approche intuitive serait de prĂŠcalculer le nombre de bits de chaque double-mot et de le stocker dans un tableau.
Cependant, il y a deux problèmes relatifs à cette approche. Il y a à peu près 4 milliards de valeurs de doubles-mots ! Cela signifie que le tableau serait très gros et que l'initialiser prendrait beaucoup de temps (en fait, à moins que l'on ait l'intention d'utiliser le tableau plus de 4 milliards de fois, cela prendrait plus de temps de l'initialiser que cela n'en prendrait de calculer le nombre de bits avec la mÊthode un !).
Une mĂŠthode plus rĂŠaliste calculerait le nombre de bits pour toutes les valeurs possibles d'octet et les stockerait dans un tableau. Le double-mot peut alors ĂŞtre dĂŠcomposĂŠ en quatre valeurs d'un octet. Le nombre de bits pour chacune de ces quatre valeurs d'un octet est recherchĂŠ dans le tableau et additionnĂŠ aux autres pour trouver le nombre de bits du double-mot original.
La Figure 3.7 montre le code implĂŠmentant cette approche.

La fonction initialize_count_bits doit être appelÊe avant le premier appel à la fonction count_bits. Cette fonction initialise le tableau global byte_bit_count. La fonction count_bits ne considère pas la variable data comme un double-mot, mais comme un tableau de quatre octets. Donc, dword[0] est un des octets de data (soit le moins significatif, soit le plus significatif selon que le matÊriel est little ou big endian, respectivement).
Bien sĂťr, on peut utiliser une instruction comme :
(data >> 24) & 0x000000FF
pour trouver la valeur de l'octet le plus significatif et des opĂŠrations similaires pour les autres octets, cependant, ces opĂŠrations seraient plus lentes qu'une rĂŠfĂŠrence Ă un tableau.
Un dernier point, une boucle for pourrait facilement être utilisÊe pour calculer la somme des lignes 22 et 23. Mais, cela inclurait le supplÊment de l'initialisation de l'indice, sa comparaison après chaque itÊration et son incrÊmentation. Calculer la somme comme une somme explicite de quatre valeurs est plus rapide. En fait, un compilateur intelligent convertirait la version avec une boucle for en une somme explicite. Ce procÊdÊ de rÊduire ou Êliminer les itÊrations d'une boucle est une technique d'optimisation de compilateur appelÊe loop unrolling (dÊroulage de boucle).
IV-F-3. MĂŠthode trois▲
Il y a encore une mĂŠthode intelligente de compter les bits allumĂŠs d'une donnĂŠe. Cette mĂŠthode ajoute littĂŠralement les 1 et les 0 de la donnĂŠe.
La somme est Êgale au nombre de 1 dans la donnÊe. Par exemple, considÊrons le comptage des 1 d'un octet stockÊ dans une variable nommÊe data. La première Êtape est d'effectuer l'opÊration suivante :
data = (data & 0x55) + ((data >> 1) & 0x55);Pourquoi faire cela ? La constante hexa 0x55 vaut 01010101 en binaire. Dans le premier opĂŠrande de l'addition, on effectue un ET sur data avec elle, les bits sur des positions impaires sont supprimĂŠs. Le second opĂŠrande ((data>> 1) & 0x55) commence par dĂŠplacer tous les bits Ă des positions paires vers une position impaire et utilise le mĂŞme masque pour supprimer ces bits.
Maintenant, le premier opĂŠrande contient les bits impairs et le second, les bits pairs de data. Lorsque ces deux opĂŠrandes sont additionnĂŠs, les bits pairs et les bits impairs de data sont additionnĂŠs. Par exemple, si data vaut 101100112, alors :
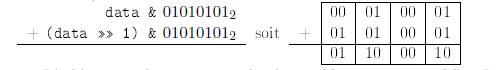
L'addition Ă droite montre les bits additionnĂŠs ensemble. Les bits de l'octet sont divisĂŠs en deux champs de 2 bits pour montrer qu'il y a en fait quatre additions indĂŠpendantes. Comme la plus grande valeur que ces sommes peuvent prendre est deux, il n'est pas possible qu'une somme dĂŠborde de son champ et corrompe l'une des autres sommes.
Bien sĂťr, le nombre total de bits n'a pas encore ĂŠtĂŠ calculĂŠ. Cependant, la mĂŞme technique que celle qui a ĂŠtĂŠ utilisĂŠe ci-dessus peut ĂŞtre utilisĂŠe pour calculer le total en une sĂŠrie d'ĂŠtapes similaires. L'ĂŠtape suivante serait :
data = (data & 0x33) + ((data >> 2) & 0x33);
En continuant l'exemple du dessus (souvenez-vous que data vaut maintenant 011000102).
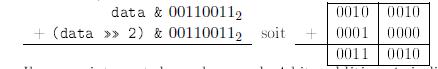
Il y a maintenant deux champs de 4 bits additionnĂŠs individuellement. La prochaine ĂŠtape est d'additionner ces deux sommes de bits ensemble pour former le rĂŠsultat final :
data = (data & 0x0F) + ((data >> 4) & 0x0F);
En utilisant l'exemple ci-dessus (avec data ĂŠgale Ă 001100102) :
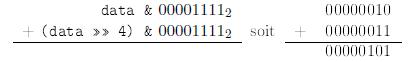
Maintenant, data vaut 5 ce qui est le rĂŠsultat correct. La Figure 3.8 montre une implĂŠmentation de cette mĂŠthode qui compte les bits dans un double-mot.

Elle utilise une boucle for pour calculer la somme. Il serait plus rapide de dÊrouler la boucle, cependant, la boucle rend plus claire la façon dont la mÊthode se gÊnÊralise à diffÊrentes tailles de donnÊes.
V. Sous-programmes▲
Ce chapitre explique comment utiliser des sous-programmes pour crĂŠer des programmes modulaires et s'interfacer avec des langages de haut niveau (comme le C). Les fonctions et les procĂŠdures sont des exemples de sous-programmes dans les langages de haut niveau.
Le code qui appelle le sous-programme et le sous-programme lui-même doivent se mettre d'accord sur la façon de se passer les donnÊes. Ces règles sur la façon de passer les donnÊes sont appelÊes conventions d'appel. Une grande partie de ce chapitre traitera des conventions d'appel standard du C qui peuvent être utilisÊes pour interfacer des sous-programmes assembleur avec des programmes C. Celles-ci (et d'autres conventions) passent souvent les adresses des donnÊes (i.e. des pointeurs) pour permettre au sous-programme d'accÊder aux donnÊes en mÊmoire.
V-A. Adressage indirect▲
L'adressage indirect permet aux registres de se comporter comme des pointeurs. Pour indiquer qu'un registre est utilisĂŠ indirectement comme un pointeur, il est entourĂŠ par des crochets ([ ]). Par exemple :
1 mov ax, [Data] ; adressage mĂŠmoire direct normal d'un mot
2 mov ebx, Data ; ebx = & Data
3 mov ax, [ebx] ; ax = *ebxComme AX contient un mot, la ligne 3 lit un mot commençant à l'adresse stockÊe dans EBX. Si AX Êtait remplacÊ par AL, un seul octet serait lu.
Il est important de rÊaliser que les registres n'ont pas de types comme les variables en C. Ce sur quoi EBX est censÊ pointer est totalement dÊterminÊ par les instructions utilisÊes. Si EBX est utilisÊ de manière incorrecte, il n'y aura souvent pas d'erreur signalÊe de la part de l'assembleur, cependant, le programme ne fonctionnera pas correctement. C'est une des nombreuses raisons pour lesquelles la programmation assembleur est plus sujette à erreur que la programmation de haut niveau.
Tous les registres 32 bits gĂŠnĂŠraux (EAX, EBX, ECX, EDX) et d'index (ESI, EDI) peuvent ĂŞtre utilisĂŠs pour l'adressage indirect. En gĂŠnĂŠral, les registres 16 et 8 bits ne le peuvent pas.
V-B. Exemple de sous-programme simple▲
Un sous-programme est une unitÊ de code indÊpendante qui peut être utilisÊe depuis diffÊrentes parties du programme. En d'autres termes, un sous-programme est comme une fonction en C. Un saut peut être utilisÊ pour appeler le sous-programme, mais le retour prÊsente un problème. Si le sous-programme est destinÊ à être utilisÊ par diffÊrentes parties du programme, il doit revenir à la section de code qui l'a appelÊ. Donc, le retour du sous-programme ne peut pas être codÊ en dur par un saut vers une Êtiquette. Le code ci-dessous montre comment cela peut être rÊalisÊ en utilisant une forme indirecte de l'instruction JMP. Cette forme de l'instruction utilise la valeur d'un registre pour dÊterminer oÚ sauter (donc, le registre agit plus comme un pointeur de fonction du C). Voici le premier programme du Chapitre II rÊÊcrit pour utiliser un sous-programme.
1 ; fichier : sub1.asm
2 ; Programme d'exemple de sous-programme
3 %include "asm_io.inc"
4
5 segment .data
6 prompt1 db "Entrez un nombre : ", 0 ; ne pas oublier le zĂŠro terminal
7 prompt2 db "Entrez un autre nombre : ", 0
8 outmsg1 db "Vous avez entrĂŠ ", 0
9 outmsg2 db " et ", 0
10 outmsg3 db ", la somme des deux vaut ", 0
11
12 segment .bss
13 input1 resd 1
14 input2 resd 1
15
16 segment .text
17 global _asm_main
18 _asm_main :
19 enter 0,0 ; routine d'initialisation
20 pusha
21
22 mov eax, prompt1 ; affiche l'invite
23 call print_string
24
25 mov ebx, input1 ; stocke l'adresse de input1 dans ebx
26 mov ecx, ret1 ; stocke l'adresse de retour dans ecx
27 jmp short get_int ; lit un entier
28 ret1:
29 mov eax, prompt2 ; affiche l'invite
30 call print_string
31
32 mov ebx, input2
33 mov ecx, $ + 7 ; ecx = cette addresse + 7
34 jmp short get_int
35
36 mov eax, [input1] ; eax = dword dans input1
37 add eax, [input2] ; eax += dword dans input2
38 mov ebx, eax ; ebx = eax
39
40 mov eax, outmsg1
41 call print_string ; affiche le premier message
42 mov eax, [input1]
43 call print_int ; affiche input1
44 mov eax, outmsg2
45 call print_string ; affiche le second message
46 mov eax, [input2]
47 call print_int ; affiche input2
48 mov eax, outmsg3
49 call print_string ; affiche le troisième message
50 mov eax, ebx
51 call print_int ; affiche la somme (ebx)
52 call print_nl ; retour Ă la ligne
53
54 popa
55 mov eax, 0 ; retour au C
56 leave
57 ret
58 ; subprogram get_int
59 ; Paramètres :
60 ; ebx - addresse du dword dans lequel stocker l'entier
61 ; ecx - addresse de l'instruction vers laquelle retourner
62 ; Notes :
63 ; la valeur de eax est perdue
64 get_int:
65 call read_int
66 mov [ebx], eax ; stocke la saisie en mĂŠmoire
67 jmp ecx sub1.;asrmetour Ă l'appelantLe sous-programme get_int utilise une convention d'appel simple, basĂŠe sur les registres. Il s'attend Ă ce que le registre EBX contienne l'adresse du DWORD dans lequel stocker le nombre saisi et Ă ce que le registre ECX contiennent l'adresse de l'instruction vers laquelle retourner.
Dans les lignes 25 Ă 28, l'ĂŠtiquette ret1 est utilisĂŠe pour calculer cette adresse de retour.
Dans les lignes 32 Ă 34, l'opĂŠrateur $ est utilisĂŠ pour calculer l'adresse de retour. L'opĂŠrateur $ retourne l'adresse de la ligne sur laquelle il apparaĂŽt. L'expression $ + 7 calcule l'adresse de l'instruction MOV de la ligne 36.
Ces deux calculs d'adresses de code de retour sont compliquÊs. La première mÊthode requiert la dÊfinition d'une Êtiquette pour tout appel de sous-programme.
La seconde mĂŠthode ne requiert pas d'ĂŠtiquette, mais nĂŠcessite de rĂŠflĂŠchir attentivement. Si un saut proche avait ĂŠtĂŠ utilisĂŠ Ă la place d'un saut court, le nombre Ă ajouter Ă $ n'aurait pas ĂŠtĂŠ 7 !
Heureusement, il y a une façon plus simple d'appeler des sous-programmes. Cette mÊthode utilise la pile.
V-C. La pile▲
Beaucoup de processeurs ont un support intÊgrÊ pour une pile. Une pile est une liste Last-In First-Out (LIFO, dernier entrÊ, premier sorti). La pile est une zone de la mÊmoire qui est organisÊe de cette façon. L'instruction PUSH ajoute des donnÊes à la pile et l'instruction POP retire une donnÊe. La donnÊe retirÊe est toujours la dernière donnÊe ajoutÊe (c'est pourquoi on appelle ce genre de liste dernier entrÊ, premier sorti).
Le registre de segment SS spĂŠcifie le segment qui contient la pile (habituellement c'est le mĂŞme que celui qui contient les donnĂŠes). Le registre ESP contient l'adresse de la donnĂŠe qui sera retirĂŠe de la pile. On dit que cette donnĂŠe est au sommet de la pile. Les donnĂŠes ne peuvent ĂŞtre ajoutĂŠes que par unitĂŠs de doubles-mots. C'est-Ă -dire qu'il est impossible de placer un octet seul sur la pile.
L'instruction PUSH insère un double-mot(19) sur la pile en ôtant 4 de ESP puis en stockant le double-mot en [ESP]. L'instruction POP lit le double-mot en [ESP] puis ajoute 4 à ESP. Le code ci-dessous montre comment fonctionnent ces instructions en supposant que ESP vaut initialement 1000H.
1 push dword 1 ; 1 est stockĂŠ en 0FFCh, ESP = 0FFCh
2 push dword 2 ; 2 est stockĂŠ en 0FF8h, ESP = 0FF8h
3 push dword 3 ; 3 est stockĂŠ en 0FF4h, ESP = 0FF4h
4 pop eax ; EAX = 3, ESP = 0FF8h
5 pop ebx ; EBX = 2, ESP = 0FFCh
6 pop ecx ; ECX = 1, ESP = 1000hLa pile peut être utilisÊe comme un endroit appropriÊ pour stocker des donnÊes temporairement. Elle est Êgalement utilisÊe pour effectuer des appels de sous-programmes, passer des paramètres et des variables locales.
Le 80x86 fournit ĂŠgalement une instruction, PUSHA, qui empile les valeurs des registres EAX, EBX, ECX, EDX, ESI, EDI et EBP (pas dans cet ordre).
L'instruction POPA peut ĂŞtre utilisĂŠe pour les dĂŠpiler tous.
V-D. Les Instructions CALL et RET▲
Le 80x86 fournit deux instructions qui utilisent la pile pour effectuer des appels de sous-programmes rapidement et facilement. L'instruction CALL effectue un saut inconditionnel vers un sous-programme et empile l'adresse de l'instruction suivante. L'instruction RET dÊpile une adresse et saute à cette adresse. Lors de l'utilisation de ces instructions, il est très important de gÊrer la pile correctement afin que le chiffre correct soit dÊpilÊ par l'instruction RET !
Le programme prĂŠcĂŠdent peut ĂŞtre rĂŠĂŠcrit pour utiliser ces nouvelles instructions en changeant les lignes 25 Ă 34 en ce qui suit :
mov ebx, input1
call get_int
mov ebx, input2
call get_intet en changeant le sous-programme get_int en :
get_int :
call read_int
mov [ebx], eax
retIl y a plusieurs avantages Ă utiliser CALL et RET :
- c'est plus simple ! ;
- cela permet d'imbriquer des appels de sous-programmes facilement.
Notez que get_int appelle read_int. Cet appel empile une autre adresse Ă la fin du code de read_int se trouve un RET qui dĂŠpile l'adresse de retour et saute vers le code de get_int. Puis, lorsque le RET de get_int est exĂŠcutĂŠ, il dĂŠpile l'adresse de retour qui revient vers asm_main. Cela fonctionne correctement, car il s'agit d'une pile LIFO.
Souvenez-vous, il est très important de dÊpiler toute donnÊe qui est empilÊe. Par exemple, considÊrons le code suivant :
1 get_int :
2 call read_int
3 mov [ebx], eax
4 push eax
5 ret ; dĂŠpile la valeur de EAX, pas l'adresse de retour !!Ce code ne reviendra pas correctement !
V-E. Conventions d'appel▲
Lorsqu'un sous-programme est appelÊ, le code appelant et le sous-programme (l'appelÊ) doivent s'accorder sur la façon de se passer les donnÊes. Les langages de haut niveau ont des manières standard de passer les donnÊes appelÊes  conventions d'appel . Pour interfacer du code de haut niveau avec le langage assembleur, le code assembleur doit utiliser les mêmes conventions que le langage de haut niveau. Les conventions d'appel peuvent diffÊrer d'un compilateur à l'autre ou peuvent varier selon la façon dont le code est compilÊ (p.e. selon que les optimisations sont activÊes ou pas). Une convention universelle est que le code est appelÊ par une instruction CALL et revient par un RET.
Tous les compilateurs C PC supportent une convention d'appel qui sera dĂŠcrite dans le reste de ce chapitre par ĂŠtape. Ces conventions permettent de crĂŠer des sous-programmes rĂŠentrants. Un sous-programme rĂŠentrant peut ĂŞtre appelĂŠ depuis n'importe quel endroit du programme en toute sĂŠcuritĂŠ (mĂŞme depuis le sous-programme lui-mĂŞme).
V-E-1. Passer les paramètres via la pile▲
Les paramètres d'un sous-programme peuvent être passÊs par la pile. Ils sont empilÊs avant l'instruction CALL. Comme en C, si le paramètre doit être modifiÊ par le sous-programme, l'adresse de la donnÊe doit être passÊe, pas sa valeur. Si la taille du paramètre est infÊrieure à un double-mot, il doit être converti en un double-mot avant d'être empilÊ.
Les paramètres sur la pile ne sont pas dÊpilÊs par le sous-programme, à place, ils sont accÊdÊs depuis la pile elle-même. Pourquoi ? Comme ils doivent être empilÊs avant l'instruction CALL, l'adresse de retour devrait être dÊpilÊe avant tout (puis rÊempilÊe).
Souvent, les paramètres sont utilisÊs à plusieurs endroits dans le sous-programme. Habituellement, ils ne peuvent pas être conservÊs dans un registre durant toute la durÊe du sous-programme et devront être stockÊs en mÊmoire. Les laisser sur la pile conserve une copie de la donnÊe en mÊmoire qui peut être accÊdÊe depuis n'importe quel endroit du sous-programme.
ConsidÊrons un sous-programme auquel on passe un paramètre unique via la pile. Lorsque le sous-programme est appelÊ, la pile ressemble à la Figure 4.1. On peut accÊder au paramètre en utilisant l'adressage indirect ([ESP+4](20)).

Lors de l'utilisation de l'adressage indirect, le processeur 80x86 accède à diffÊrents segments selon les registres utilisÊs dans l'expression d'adressage indirect. ESP (et EBP) utilisent le segment de pile alors que EAX, EBX, ECX et EDX utilisent le segment de donnÊes.
Cependant, ce n'est habituellement pas important pour la plupart des programmes en mode protĂŠgĂŠ, car pour eux, les segments de pile et de donnĂŠes sont les mĂŞmes.
Si la pile est ĂŠgalement utilisĂŠe dans le sous-programme pour stocker des donnĂŠes, le nombre Ă ajouter Ă ESP changera. Par exemple, la Figure 4.2 montre Ă quoi ressemble la pile si un DWORD est empilĂŠ.

Maintenant, le paramètre se trouve en ESP + 8, plus en ESP + 4. Donc, utiliser ESP lorsque l'on fait rÊfÊrence à des paramètres peut être une source d'erreurs. Pour rÊsoudre ce problème, le 80386 fournit un autre registre à utiliser : EBP. La seule utilitÊ de ce registre est de faire rÊfÊrence à des donnÊes sur la pile. La convention d'appel C stipule qu'un sous-programme doit d'abord empiler la valeur de EBP puis dÊfinir EBP pour qu'il soit Êgal à ESP. Cela permet à ESP de changer au fur et à mesure que des donnÊes sont empilÊes ou dÊpilÊes sans modifier EBP. à la fin du programme, la valeur originale de EBP doit être restaurÊe (c'est pourquoi elle est sauvegardÊe au dÊbut du sous-programme).
La Figure 4.3 montre la forme gĂŠnĂŠrale d'un sous-programme qui suit ces conventions.

Les lignes 2 et 3 de la Figure 4.3 constituent le prologue gÊnÊrique d'un sous-programme. Les lignes 5 et 6 constituent l'Êpilogue. La Figure 4.4 montre à quoi ressemble la pile immÊdiatement après le prologue.

Maintenant, le paramètre peut être accÊdÊ avec [EBP + 8] depuis n'importe quel endroit du programme sans se soucier de ce qui a ÊtÊ empilÊ entretemps par le sous-programme.
Une fois le sous-programme terminÊ, les paramètres qui ont ÊtÊ empilÊs doivent être retirÊs. La convention d'appel C spÊcifie que c'est au code appelant de le faire. D'autres conventions sont diffÊrentes. Par exemple, la convention d'appel Pascal spÊcifie que c'est au sous-programme de retirer les paramètres (Il y a une autre forme de l'instruction RET qui permet de le faire facilement). Quelques compilateurs C supportent cette convention Êgalement.
Le mot-clÊ pascal est utilisÊ dans le prototype et la dÊfinition de la fonction pour indiquer au compilateur d'utiliser cette convention. En fait, la convention stdcall, que les fonctions de l'API C MS Windows utilisent, fonctionne Êgalement de cette façon. Quel est son avantage ? Elle est un petit peu plus efficace que la convention C. Pourquoi toutes les fonctions C n'utilisent-elles pas cette convention alors ? En gÊnÊral, le C autorise une fonction à avoir un nombre variable d'arguments (p.e., les fonctions printf et scanf).
Pour ce type de fonction, l'opÊration consistant à retirer les paramètres de la pile varie d'un appel à l'autre. La convention C permet aux instructions nÊcessaires à la rÊalisation de cette opÊration de varier facilement d'un appel à l'autre. Les conventions Pascal et stdcall rendent cette opÊration très compliquÊe. Donc, la convention Pascal (comme le langage Pascal) n'autorise pas ce type de fonction. MS Windows peut utiliser cette convention puisqu'aucune de ses fonctions d'API ne prend un nombre variable d'arguments.
La Figure 4.5 montre comment un sous-programme utilisant la convention d'appel C serait appelĂŠ.

La ligne 3 retire le paramètre de la pile en manipulant directement le pointeur de pile. Une instruction POP pourrait Êgalement être utilisÊe, mais cela nÊcessiterait le stockage d'un paramètre inutile dans un registre. En fait, dans ce cas particulier, beaucoup de compilateurs utilisent une instruction POP ECX pour retirer le paramètre. Le compilateur utilise un POP plutôt qu'un ADD, car le ADD nÊcessite plus d'octets pour stocker l'instruction. Cependant, le POP change Êgalement la valeur de ECX ! Voici un autre programme exemple avec deux sous-programmes qui utilisent les conventions d'appel C dont nous venons de parler. La ligne 54 (et les autres) montre que plusieurs segments de donnÊes et de texte peuvent être dÊclarÊs dans un même fichier source. Ils seront combinÊs en des segments de donnÊes et de texte uniques lors de l'Êdition de liens. Diviser les donnÊes et le code en segments sÊparÊs permet d'avoir les donnÊes d'un sous-programme dÊfinies à proximitÊ de celui-ci.
1 %include "asm_io.inc"
2
3 segment .data
4 sum dd 0
5
6 segment .bss
7 input resd 1
8
9 ;
10 ; algorithme en pseudo-code
11 ; i = 1;
12 ; sum = 0;
13 ; while( get_int(i, &input), input != 0 ) {
14 ; sum += input;
15 ; i++;
16 ; }
17 ; print_sum(num);
18 segment .text
19 global _asm_main
20 _asm_main :
21 enter 0,0 ; routine d'initialisation
22 pusha
23
24 mov edx, 1 ; edx est le 'i' du pseudo-code
25 while_loop :
26 push edx ; empile i
27 push dword input ; empile l'adresse de input
28 call get_int
29 add esp, 8 ; dĂŠpile i et &input
30
31 mov eax, [input]
32 cmp eax, 0
33 je end_while
34
35 add [sum], eax ; sum += input
36
37 inc edx
38 jmp short while_loop
39
40 end_while:
41 push dword [sum] ; empile la valeur de sum
42 call print_sum
43 pop ecx ; dĂŠpile [sum]
44
45 popa
46 leave
47 ret
48
49 ; sous-programme get_int
50 ; Paramètres (dans l'ordre de l'empilement)
51 ; nombre de saisies (en [ebp + 12])
52 ; adresse du mot oĂš stocker la saisie (en [ebp + 8])
53 ; Notes :
54 ; les valeurs de eax et ebx sont dĂŠtruites
55 segment .data
56 prompt db ") Entrez un nombre entier (0 pour quitter): ", 0
57
58 segment .text
59 get_int:
60 push ebp
61 mov ebp, esp
62
63 mov eax, [ebp + 12]
64 call print_int
65
66 mov eax, prompt
67 call print_string
68
69 call read_int
70 mov ebx, [ebp + 8]
71 mov [ebx], eax ; stocke la saisie en mĂŠmoire
72
73 pop ebp
74 ret ; retour Ă l'appelant
75
76 ; sous-programme print_sum
77 ; affiche la somme
78 ; Paramètre :
79 ; somme Ă afficher (en [ebp+8])
80 ; Note : dĂŠtruit la valeur de eax
81 ;
82 segment .data
83 result db "La somme vaut ", 0
84
85 segment .text
86 print_sum:
87 push ebp
88 mov ebp, esp
89
90 mov eax, result
91 call print_string
92
93 mov eax, [ebp+8]
94 call print_int
95 call print_nl
96
97 pop ebp
98 retV-E-2. Variables locales sur la pile▲
La pile peut ĂŞtre utilisĂŠe comme un endroit pratique pour stocker des variables locales. C'est exactement ce que fait le C pour les variables normales (ou automatiques en C lingo). Utiliser la pile pour les variables est important si l'on veut que les sous-programmes soient rĂŠentrants. Un programme rĂŠentrant fonctionnera qu'il soit appelĂŠ de n'importe quel endroit, mĂŞme Ă partir du sous-programme lui-mĂŞme. En d'autres termes, les sous-programmes rĂŠentrants peuvent ĂŞtre appelĂŠs rĂŠcursivement.
Utiliser la pile pour les variables ĂŠconomise ĂŠgalement de la mĂŠmoire. Les donnĂŠes qui ne sont pas stockĂŠes sur la pile utilisent de la mĂŠmoire du dĂŠbut Ă la fin du programme (le C appelle ce type de variables global ou static). Les donnĂŠes stockĂŠes sur la pile n'utilisent de la mĂŠmoire que lorsque le sous-programme dans lequel elles sont dĂŠfinies est actif.
Les variables locales sont stockÊes immÊdiatement après la valeur de EBP sauvegardÊe dans la pile. Elles sont allouÊes en soustrayant le nombre d'octets requis de ESP dans le prologue du sous-programme. La Figure 4.6 montre le nouveau squelette du sous-programme.

Le registre EBP est utilisĂŠ pour accĂŠder Ă des variables locales. ConsidĂŠrons la fonction C de la Figure 4.7.

La Figure 4.8 montre comment le sous-programme ĂŠquivalent pourrait ĂŞtre ĂŠcrit en assembleur.

La Figure 4.9 montre à quoi ressemble la pile après le prologue du programme de la Figure 4.8.

Cette section de la pile qui contient les paramètres, les informations de retour et les variables locales est appelÊe cadre de pile (stack frame). Chaque appel de fonction C crÊe un nouveau cadre de pile sur la pile.
Le prologue et l'Êpilogue d'un sous-programme peuvent être simplifiÊs en utilisant deux instructions spÊciales qui sont conçues spÊcialement dans ce but. L'instruction ENTER effectue le prologue et l'instruction LEAVE l'Êpilogue.
L'instruction ENTER prend deux opÊrandes immÊdiats. Dans la convention d'appel C, le deuxième opÊrande est toujours 0. Le premier opÊrande est le nombre d'octets nÊcessaires pour les variables locales. L'instruction LEAVE n'a pas d'opÊrande. La Figure 4.10 montre comment ces instructions sont utilisÊes. Notez que le squelette de programme (Figure 1.7) utilise Êgalement ENTER et LEAVE.

En dÊpit du fait que ENTER et LEAVE simplifient le prologue et l'Êpilogue, ils ne sont pas utilisÊs très souvent. Pourquoi ? Parce qu'ils sont plus lents que les instructions plus simples Êquivalentes ! C'est un des exemples oÚ il ne faut pas supposer qu'une instruction est plus rapide qu'une sÊquence de plusieurs instructions.
V-F. Programme multimodule▲
Un programme multimodule est un programme composÊ de plus d'un fichier objet. Tous les programmes prÊsentÊs jusqu'ici sont des programmes multimodules. Ils consistent en un fichier objet C pilote et le fichier objet assembleur (plus les fichiers objet de la bibliothèque C). Souvenez-vous que l'Êditeur de liens combine les fichiers objet en un programme exÊcutable unique. L'Êditeur de liens doit rapprocher toutes les rÊfÊrences faites à chaque Êtiquette d'un module (i.e. un fichier objet) de sa dÊfinition dans un autre module. Afin que le module A puisse utiliser une Êtiquette dÊfinie dans le module B, la directive extern doit être utilisÊe. Après la directive extern vient une liste d'Êtiquettes dÊlimitÊes par des virgules. La directive indique à l'assembleur de traiter ces Êtiquettes comme externes au module. C'est-à -dire qu'il s'agit d'Êtiquettes qui peuvent être utilisÊes dans ce module, mais sont dÊfinies dans un autre. Le fichier asm_io.inc dÊfinit les routines read_int, etc. comme externes.
En assembleur, les ĂŠtiquettes ne peuvent pas ĂŞtre accĂŠdĂŠes de l'extĂŠrieur par dĂŠfaut. Si une ĂŠtiquette doit pouvoir ĂŞtre accĂŠdĂŠe depuis d'autres modules que celui dans lequel elle est dĂŠnie, elle doit ĂŞtre dĂŠclarĂŠe comme globale dans son module, par le biais de la directive global. La ligne 13 du listing du programme squelette de la Figure 1.7 montre que l'ĂŠtiquette _asm_main est dĂŠfinie comme globale. Sans cette dĂŠclaration, l'ĂŠditeur de liens indiquerait une erreur. Pourquoi ? Parce que le code C ne pourrait pas faire rĂŠfĂŠrence Ă l'ĂŠtiquette interne _asm_main.
Voici le code de l'exemple prĂŠcĂŠdent rĂŠĂŠcrit afin d'utiliser deux modules. Les deux sous-programmes (get_int et print_sum) sont dans des fichiers source distincts de celui de la routine _asm_main.
1 %include "asm_io.inc"
2
3 segment .data
4 sum dd 0
5
6 segment .bss
7 input resd 1
8
9 segment .text
10 global _asm_main
11 extern get_int, print_sum
12 _asm_main :
13 enter 0,0 ; routine d'initialisation
14 pusha
15
16 mov edx, 1 ; edx est le 'i' du pseudo-code
17 while_loop :
18 push edx ; empile i
19 push dword input ; empile l'adresse de input
20 call get_int
21 add esp, 8 ; dĂŠpile i et &input
22
23 mov eax, [input]
24 cmp eax, 0
25 je end_while
26
27 add [sum], eax ; sum += input
28
29 inc edx
30 jmp short while_loop
31
32 end_while:
33 push dword [sum] ; empile la valeur de sum
34 call print_sum
35 pop ecx ; dĂŠpile [sum]
36
37 popa
38 leave
39 ret1 %include "asm_io.inc"
2
3 segment .data
4 prompt db ") Entrez un nombre entier (0 pour quitter): ", 0
5
6 segment .text
7 global get_int, print_sum
8 get_int :
9 enter 0,0
10
11 mov eax, [ebp + 12]
12 call print_int
13
14 mov eax, prompt
15 call print_string
16
17 call read_int
18 mov ebx, [ebp + 8]
19 mov [ebx], eax ; stocke la saisie en mĂŠmoire
20
21 leave
22 ret ; retour Ă l'appelant
23
24 segment .data
25 result db "La somme vaut ", 0
26
27 segment .text
28 print_sum :
29 enter 0,0
30
31 mov eax, result
32 call print_string
33
34 mov eax, [ebp+8]
35 call print_int
36 call print_nl
37
38 leave
39 retL'exemple ci-dessus n'a que des Êtiquettes de code globales ; cependant, les Êtiquettes de donnÊe globales fonctionnent exactement de la même façon.
V-G. Interfacer de l'assembleur avec du C▲
Aujourd'hui, très peu de programmes sont Êcrits complètement en assembleur.
Les compilateurs sont très performants dans la conversion de code de haut niveau en code machine efficace. Comme il est plus facile d'Êcrire du code dans un langage de haut niveau, ils sont plus populaires. De plus, le code de haut niveau est beaucoup plus portable que l'assembleur !
Lorsque de l'assembleur est utilisÊ, c'est souvent pour de petites parties du code. Cela peut être fait de deux façons : en appelant des sous-routines assembleur depuis le C ou en incluant de l'assembleur. Inclure de l'assembleur permet au programmeur de placer des instructions assembleur directement dans le code C. Cela peut être très pratique ; cependant, il y a des inconvÊnients à inclure l'assembleur. Le code assembleur doit être Êcrit dans le format que le compilateur utilise. Aucun compilateur pour le moment ne supporte le format NASM. Des compilateurs diffÊrents demandent des formats diffÊrents. Borland et Microsoft demandent le format MASM. DJGPP et gcc sous Linux demandent le format GAS(21). La technique d'appel d'une sous-routine assembleur est beaucoup plus standardisÊe sur les PC.
Les routines assembleur sont habituellement utilisĂŠes avec le C pour les raisons suivantes :
- un accès direct aux fonctionnalitÊs matÊrielles de l'ordinateur est nÊcessaire, car il est difficile ou impossible d'y accÊder en C ;
- la routine doit ĂŞtre la plus rapide possible et le programmeur peut optimiser le code Ă la main mieux que le compilateur.
La dernière raison n'est plus aussi valide qu'elle l'Êtait. La technologie des compilateurs a ÊtÊ amÊliorÊe au fil des ans et les compilateurs gÊnèrent souvent un code très performant (en particulier si les optimisations sont activÊes).
Les inconvĂŠnients des routines assembleur sont une portabilitĂŠ et une lisibilitĂŠ rĂŠduites.
La plus grande partie des conventions d'appel C a dĂŠjĂ ĂŠtĂŠ prĂŠsentĂŠe.
Cependant, il y a quelques fonctionnalitĂŠs supplĂŠmentaires qui doivent ĂŞtre dĂŠcrites.
V-G-1. Sauvegarder les registres▲
Tout d'abord, Le C suppose qu'une sous-routine maintient les valeurs des registres suivants : EBX, ESI, EDI, EBP, CS, DS, SS, ES. Cela ne signifie pas que la sous-routine ne les change pas en interne. Cela signifie que si elle change leurs valeurs, elle doit les restaurer avant de revenir. Les valeurs de EBX, ESI et EDI doivent ĂŞtre inchangĂŠes, car le C utilise ces registres pour les variables de registre. Habituellement, la pile est utilisĂŠe pour sauvegarder les valeurs originales de ces registres.
Le mot-clĂŠ register peut ĂŞtre utilisĂŠ dans une dĂŠclaration de variable C pour suggĂŠrer au compilateur d'utiliser un registre pour cette variable plutĂ´t qu'un emplacement mĂŠmoire. On appelle ces variables, variables de registre. Les compilateurs modernes le font automatiquement sans qu'il y ait besoin d'une suggestion.
V-G-2. Ătiquettes de fonctions▲
La plupart des compilateurs C ajoutent un caractère underscore(_) au dÊbut des noms des fonctions et des variables global/static. Par exemple, à une fonction appelÊe f sera assignÊe l'Êtiquette _f. Donc, s'il s'agit d'une routine assembleur, elle doit être ÊtiquetÊe _f, pas f. Le compilateur Linux gcc, n'ajoute aucun caractère. Dans un exÊcutable Linux ELF, on utiliserait simplement l'Êtiquette f pour la fonction f. Cependant, le gcc de DJGPP ajoute un underscore. Notez que dans le squelette de programme assembleur (Figure 1.7), l'Êtiquette de la routine principale est _asm_main.
V-G-3. Passer des paramètres▲
Dans les conventions d'appel C, les arguments d'une fonction sont empilĂŠs sur la pile dans l'ordre inverse de celui dans lequel ils apparaissent dans l'appel de la fonction.
ConsidĂŠrons l'expression C suivante : printf("x = %d\n",x); la Figure 4.11 montre comment elle serait compilĂŠe (dans le format NASM ĂŠquivalent).

La Figure 4.12 montre à quoi ressemble la pile après le prologue de la fonction printf.

La fonction printf est une des fonctions de la bibliothèque C qui peut prendre n'importe quel nombre d'arguments. Les règles des conventions d'appel C ont ÊtÊ spÊcialement Êcrites pour autoriser ce type de fonctions. Comme l'adresse de la chaÎne format est empilÊe en dernier, son emplacement sur la pile sera toujours EBP + 8 quel que soit le nombre de paramètres passÊs à la fonction. Le code de printf peut alors analyser la chaÎne format pour dÊterminer combien de paramètres ont dÝ être passÊs et les rÊcupÊrer sur la pile.
Bien sĂťr, s'il y a une erreur, printf("x = %d\n"), le code de printf affichera quand mĂŞme la valeur double-mot en [EBP + 12]. Cependant, ce ne sera pas la valeur de x !
Il n'est pas nÊcessaire d'utiliser l'assembleur pour gÊrer un nombre alÊatoire d'arguments en C. L'en-tête stdarg.h dÊfinit des macros qui peuvent être utilisÊes pour l'effectuer de façon portable. Voyez n'importe quel bon livre sur le C pour plus de dÊtails.
V-G-4. Calculer les adresses des variables locales▲
Trouver l'adresse d'une Êtiquette dÊfinie dans les segments data ou bss est simple. Basiquement, l'Êditeur de liens le fait. Cependant, calculer l'adresse d'une variable locale (ou d'un paramètre) sur la pile n'est pas aussi intuitif.
NÊanmoins, c'est un besoin très courant lors de l'appel de sous-routines.
ConsidĂŠrons le cas du passage de l'adresse d'une variable (appelons-la x) Ă une fonction (appelons-la foo). Si x est situĂŠ en EBP ? 8 sur la pile, on ne peut pas utiliser simplement :
mov eax, ebp - 8Pourquoi ? La valeur que MOV stocke dans EAX doit ĂŞtre calculĂŠe par l'assembleur (c'est-Ă -dire qu'elle doit donner une constante). Cependant, il y a une instruction qui effectue le calcul dĂŠsirĂŠ. Elle est appelĂŠe LEA (pour Load Eective Address, Charger l'Adresse Effective). L'extrait suivant calculerait l'adresse de x et la stockerait dans EAX :
lea eax, [ebp - 8]Maintenant, EAX contient l'adresse de x et peut ĂŞtre placĂŠ sur la pile lors de l'appel de la fonction foo. Ne vous mĂŠprenez pas, au niveau de la syntaxe, c'est comme si cette instruction lisait la donnĂŠe en [EBP?8]; cependant, ce n'est pas vrai. L'instruction LEA ne lit jamais la mĂŠmoire ! Elle calcule simplement l'adresse qui sera lue par une autre instruction et stocke cette adresse dans son premier opĂŠrande registre. Comme elle ne lit pas la mĂŠmoire, aucune taille mĂŠmoire (p.e. dword) n'est nĂŠcessaire ni autorisĂŠe.
V-G-5. Retourner des valeurs▲
Les fonctions C non void retournent une valeur. Les conventions d'appel C spÊcifient comment cela doit être fait. Les valeurs de retour sont passÊes via les registres. Tous les types entiers (char, int, enum, etc.) sont retournÊs dans le registre EAX. S'ils sont plus petits que 32 bits, ils sont Êtendus à 32 bits lors du stockage dans EAX (la façon dont ils sont Êtendus dÊpend du fait qu'ils sont signÊs ou non). Les valeurs 64 bits sont retournÊes dans la paire de registres EDX:EAX. Les valeurs de pointeurs sont Êgalement stockÊes dans EAX. Les valeurs en virgule flottante sont stockÊes dans le registre STP du coprocesseur arithmÊtique (ce registre est dÊcrit dans le
chapitre sur les nombres en virgule flottante).
V-G-6. Autres conventions d'appel▲
Les règles ci-dessus dÊcrivent les conventions d'appel C supportÊes par tous les compilateurs C 80x86. Souvent, les compilateurs supportent Êgalement d'autres conventions d'appel. Lorsqu'il y a une interface avec le langage assembleur, il est très important de connaÎtre les conventions utilisÊes par le compilateur lorsqu'il appelle votre fonction. Habituellement, par dÊfaut, ce sont les conventions d'appel standard qui sont utilisÊes, cependant, ce n'est pas toujours le cas(22). Les compilateurs qui utilisent plusieurs conventions ont souvent des options de ligne de commande qui peuvent être utilisÊes pour changer la convention par dÊfaut. Ils fournissent Êgalement des extensions à la syntaxe C pour assigner explicitement des conventions d'appel à des fonctions de manière individuelle. Cependant, ces extensions ne sont pas standardisÊes et peuvent varier d'un compilateur à l'autre.
Le compilateur GCC autorise diffÊrentes conventions d'appel. La convention utilisÊe par une fonction peut être dÊclarÊe explicitement en utilisant l'extension __attribute__ . Par exemple, pour dÊclarer une fonction void qui utilise la convention d'appel standard appelÊe f qui ne prend qu'un paramètre int, utilisez la syntaxe suivante pour son prototype :
void f ( int ) __attribute__((cdecl));GCC supporte Êgalement la convention d'appel standard call . La fonction ci-dessus pourrait être dÊclarÊe afin d'utiliser cette convention en remplaçant le cdecl par stdcall. La diffÊrence entre stdcall et cdecl est que stdcall impose à la sous-routine de retirer les paramètres de la pile (comme le fait la convention d'appel Pascal). Donc, la convention stdcall ne peut être utilisÊe que par des fonctions qui prennent un nombre fixe d'arguments (i.e. celles qui ne sont pas comme printf et scanf).
GCC supporte ĂŠgalement un attribut supplĂŠmentaire appelĂŠ regparm qui indique au compilateur d'utiliser les registres pour passer jusqu'Ă trois arguments entiers Ă une fonction au lieu d'utiliser la pile. C'est un type d'optimisation courant que beaucoup de compilateurs supportent.
Borland et Microsoft utilisent une syntaxe commune pour dĂŠclarer les conventions d'appel. Ils ajoutent les mots-clĂŠs __cdecl et __stdcall au C. Ces mots-clĂŠs se comportent comme des modicateurs de fonction et apparaissent immĂŠdiatement avant le nom de la fonction dans un prototype.
Par exemple, la fonction f ci-dessus serait dĂŠfinie comme suit par Borland et Microsoft :
void __cdecl f( int );Il y a des avantages et des inconvĂŠnients Ă chacune des conventions d'appel.
Le principal avantage de cdecl est qu'elle est simple et très flexible.
Elle peut être utilisÊe pour n'importe quel type de fonction C et sur n'importe quel compilateur C. Utiliser d'autres conventions peut limiter la portabilitÊ de la sous-routine. Son principal inconvÊnient est qu'elle peut être plus lente que certaines autres et utilise plus de mÊmoire (puisque chaque appel de fonction nÊcessite du code pour retirer les paramètres de la pile).
L'avantage de la convention stdcall est qu'elle utilise moins de mÊmoire que cdecl. Aucun nettoyage de pile n'est requis après l'instruction CALL. Son principal inconvÊnient est qu'elle ne peut pas être utilisÊe avec des fonctions qui ont un nombre variable d'arguments.
L'avantage d'utiliser une convention qui se sert des registres pour passer des paramètres entiers est la rapiditÊ. Le principal inconvÊnient est que la convention est plus complexe. Certains paramètres peuvent se trouver dans des registres et d'autres sur la pile.
V-G-7. Exemples▲
Voici un exemple qui montre comment une routine assembleur peut ĂŞtre interfacĂŠe avec un programme C (notez que ce programme n'utilise pas le programme assembleur squelette (Figure 1.7) ni le module driver.c).
1 #include <stdio.h>
2 / prototype de la routine assembleur /
3 void calc_sum( int, int ) __attribute__((cdecl));
4
5 int main( void )
6 {
7 int n, sum;
8
9 printf ("Somme des entiers jusquĂ ' : ");
10 scanf("%d", &n);
11 calc_sum(n, &sum);
12 printf ("La somme vaut %d\n", sum);
13 return 0;
14 }1 ; sous-routine _calc_sum
2 ; trouve la somme des entiers de 1 Ă n
3 ; Paramètres :
4 ; n - jusqu'oĂš faire la somme (en [ebp + 8])
5 ; sump - pointeur vers un entier dans lequel stocker la somme (en [ebp + 12])
6 ; pseudo-code C :
7 ; void calc_sum( int n, int * sump )
8 ; {
9 ; int i, sum = 0;
10 ; for( i=1; i <= n; i++ )
11 ; sum += i;
12 ; *sump = sum;
13 ; }
14
15 segment .text
16 global _calc_sum
17 ;
18 ; variable locale :
19 ; sum en [ebp-4]
20 _calc_sum :
21 enter 4,0 ; Fait de la place pour sum sur la pile
22 push ebx ; IMPORTANT !
23
24 mov dword [ebp-4],0 ; sum = 0
25 dump_stack 1, 2, 4 ; affiche la pile de ebp-8 Ă ebp+16
26 mov ecx, 1 ; ecx est le i du pseudocode
27 for_loop:
28 cmp ecx, [ebp+8] ; cmp i et n
29 jnle end_for ; si non i <= n, quitter
30
31 add [ebp-4], ecx ; sum += i
32 inc ecx
33 jmp short for_loop
34
35 end_for:
36 mov ebx, [ebp+12] ; ebx = sump
37 mov eax, [ebp-4] ; eax = sum
38 mov [ebx], eax
39
40 pop ebx ; restaure ebx
41 leave
42 retPourquoi la ligne 22 de sub5.asm est si importante ? Parce que les conventions d'appel C imposent que la valeur de EBX ne soit pas modifiÊe par l'appel de fonction. Si ce n'est pas respectÊ, il est très probable que le programme ne fonctionne pas correctement.
La ligne 25 montre la façon dont fonctionne la macro dump_stack. Souvenez-vous que le premier paramètre est juste une Êtiquette numÊrique et les deuxième et troisième paramètres dÊterminent respectivement combien de doubles-mots elle doit afficher en dessous et au-dessus de EBP. La Figure 4.13 montre une exÊcution possible du programme.

Pour cette capture, on peut voir que l'adresse du dword oĂš stocker la somme est BFFFFB80 (en EBP + 12); le nombre jusqu'auquel additionner est 0000000A (en EBP + 8), l'adresse de retour pour la routine est 08048501 (en EBP + 4), la valeur sauvegardĂŠe de EBP est BFFFFB88 (en EBP), la valeur de la variable locale est 0 en (EBP - 4) et pour finir, la valeur sauvegardĂŠe de EBX est 4010648C (en EBP - 8).
La fonction calc_sum pourrait être rÊÊcrite pour retourner la somme plutôt que d'utiliser un pointeur. Comme la somme est une valeur entière, elle doit être placÊe dans le registre EAX. La ligne 11 du fichier main5.c deviendrait :
sum = calc_sum(n);De plus, le prototype de calc_sum devrait ĂŞtre altĂŠrĂŠ. Voici le code assembleur modifiĂŠ :
1 ; sous-routine _calc_sum
2 ; trouve la somme des entiers de 1 Ă n
3 ; Paramètres :
4 ; n - jusqu'oĂš faire la somme (en [ebp + 8])
5 ; Valeur de retour :
6 ; valeur de la somme
7 ; pseudo-code C :
8 ; int calc_sum( int n )
9 ; {
10 ; int i, sum = 0;
11 ; for( i=1; i <= n; i++ )
12 ; sum += i;
13 ; return sum;
14 ; }
15 segment .text
16 global _calc_sum
17 ;
18 ; variable locale :
19 ; sum en [ebp-4]
20 _calc_sum :
21 enter 4,0 ; fait de la place pour la somme sur la pile
22
23 mov dword [ebp-4],0 ; sum = 0
24 mov ecx, 1 ; ecx est le i du pseudocode
25 for_loop:
26 cmp ecx, [ebp+8] ; cmp i et n
27 jnle end_for ; si non i <= n, quitter
28
29 add [ebp-4], ecx ; sum += i
30 inc ecx
31 jmp short for_loop
32
33 end_for:
34 mov eax, [ebp-4] ; eax = sum
35
36 leave
37 retV-G-8. Appeler des fonctions C depuis l'assembleur▲
Un des avantages majeurs d'interfacer le C et l'assembleur est que cela permet au code assembleur d'accÊder à la grande bibliothèque C et aux fonctions utilisateur. Par exemple, si l'on veut appeler la fonction scanf pour lire un entier depuis le clavier. La Figure 4.14 montre comment le faire.

Une chose très importante à se rappeler est que scanf suit les conventions d'appel C standard à la lettre. Cela signifie qu'elle prÊserve les valeurs des registres EBX, ESI et EDI, cependant, les registres EAX, ECX et EDX peuvent être modifiÊs ! En fait, EAX sera modifiÊ, car il contiendra la valeur de retour de l'appel à scanf. Pour d'autres exemples d'interface entre l'assembleur et le C, observez le code dans asm_io.asm qui a ÊtÊ utilisÊ pour crÊer asm_io.obj.
V-H. Sous-programmes rĂŠentrants et rĂŠcursifs▲
Un sous-programme rÊentrant remplit les critères suivants :
- il ne doit pas modifier son code. Dans un langage de haut niveau, cela serait difficile, mais en assembleur, il n'est pas si dur que cela pour un programme de modifier son propre code. Par exemple :
mov word [cs :$+7], 5 ; copie 5 dans le mot 7 octets plus loin
add ax, 2 ; l'expression prĂŠcĂŠdente change 2 en 5 !- Il ne doit pas modifier de donnĂŠes globales (comme celles qui se trouvent dans les segments data et bss). Toutes les variables sont stockĂŠes sur la pile.
Il y a plusieurs avantages Ă ĂŠcrire du code rĂŠentrant :
- un sous-programme rĂŠentrant peut ĂŞtre appelĂŠ rĂŠcursivement ;
- un programme rĂŠentrant peut ĂŞtre partagĂŠ par plusieurs processus ;
- sur beaucoup de systèmes d'exploitation multitâches, s'il y a plusieurs instances d'un programme en cours, seule une copie du code se trouve en mÊmoire. Les bibliothèques partagÊes et les DLL (Dynamic Link Libraries, Bibliothèques de Lien Dynamique) utilisent le même principe ;
- les sous-programmes rÊentrants fonctionnent beaucoup mieux dans les programmes multithreadÊs(23). Windows 9x/NT et la plupart des systèmes d'exploitation de style Unix (Solaris, Linux, etc.) supportent les programmes multithreadÊs.
V-H-1. Sous-programmes rĂŠcursifs▲
Ce type de sous-programmes s'appellent eux-mĂŞmes. La rĂŠcursivitĂŠ peut ĂŞtre soit directe soit indirecte. La rĂŠcursivitĂŠ directe survient lorsqu'un sous-programme, disons foo, s'appelle lui-mĂŞme dans le corps de foo. La rĂŠcursivitĂŠ indirecte survient lorsqu'un sous-programme ne s'appelle pas directement lui-mĂŞme, mais via un autre sous-programme qu'il appelle. Par exemple, le sous-programme foo pourrait appeler bar et bar pourrait appeler foo.
Les sous-programmes rĂŠcursifs doivent avoir une condition de terminaison.
Lorsque cette condition est vraie, il n'y a plus d'appel rĂŠcursif. Si une routine rĂŠcursive n'a pas de condition de terminaison ou que la condition n'est jamais remplie, la rĂŠcursivitĂŠ ne s'arrĂŞtera jamais (exactement comme une boucle infinie).
La Figure 4.15 montre une fonction qui calcule une factorielle rĂŠcursivement.
Elle peut ĂŞtre appelĂŠe depuis le C avec :
x = fact (3); / trouve 3! /
La Figure 4.16 montre Ă quoi ressemble la pile au point le plus profond pour l'appel de fonction ci-dessus.
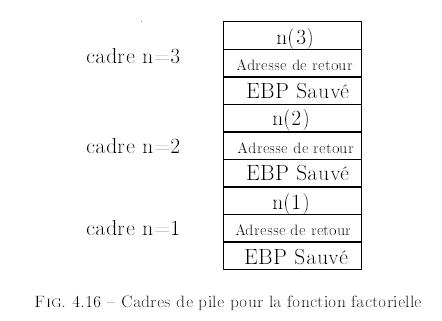
Les Figures 4.17 et 4.18 montrent un exemple rĂŠcursif plus compliquĂŠ en C et en assembleur, respectivement.


Quelle est la sortie pour f(3) ? Notez que l'instruction ENTER crĂŠe un nouveau i sur la pile pour chaque appel rĂŠcursif.
Donc, chaque instance rĂŠcursive de f a sa propre variable i indĂŠpendante.
DĂŠfinir i comme un double-mot dans le segment data ne fonctionnerait pas pareil.
V-H-2. RĂŠvision des types de stockage des variables en C▲
Le C fournit plusieurs types de stockage des variables :
global : ces variables sont dĂŠclarĂŠes en dehors de toute fonction et sont stockĂŠes Ă des emplacements mĂŠmoire fixes (dans les segments data ou bss) et existent depuis le dĂŠbut du programme jusqu'Ă la fin. Par dĂŠfaut, on peut y accĂŠder de n'importe quelle fonction dans le programme, cependant, si elles sont dĂŠclarĂŠes comme static, seules les fonctions dans le mĂŞme module peuvent y accĂŠder (i.e. en termes assembleur, l'ĂŠtiquette est interne, pas externe) ;
static : il s'agit des variables locales d'une fonction qui sont dĂŠclarĂŠes static (malheureusement, le C utilise le mot-clĂŠ static avec deux sens diffĂŠrents !). Ces variables sont ĂŠgalement stockĂŠes dans des emplacements mĂŠmoire fixes (dans data ou bss), mais ne peuvent ĂŞtre accĂŠdĂŠes directement que dans la fonction oĂš elles sont dĂŠfinies ;
automatic : c'est le type par dĂŠfaut d'une variable C dĂŠnie dans une fonction. Ces variables sont allouĂŠes sur la pile lorsque la fonction dans laquelle elles sont dĂŠfinies est appelĂŠe et sont dĂŠsallouĂŠes lorsque la fonction revient. Donc, elles n'ont pas d'emplacement mĂŠmoire fixe.
register ; ce mot-clĂŠ demande au compilateur d'utiliser un registre pour la donnĂŠe dans cette variable. Il ne s'agit que d'une requĂŞte. Le compilateur n'a pas Ă l'honorer. Si l'adresse de la variable est utilisĂŠe Ă un endroit quelconque du programme, elle ne sera pas respectĂŠe (puisque les registres n'ont pas d'adresse). De plus, seuls les types entiers simples peuvent ĂŞtre des valeurs registres. Les types structures ne peuvent pas l'ĂŞtre : ils ne tiendraient pas dans un registre ! Les compilateurs C placent souvent les variables automatiques normales dans des registres sans aide du programmeur.
volatile : ce mot-clĂŠ indique au compilateur que la valeur de la variable peut changer Ă tout moment. Cela signifie que le compilateur ne peut faire aucune supposition sur le moment oĂš la variable est modifiĂŠe. Souvent, un compilateur stocke la valeur d'une variable dans un registre temporairement et utilise le registre Ă la place de la variable dans une section de code. Il ne peut pas faire ce type d'optimisations avec les variables volatiles. Un exemple courant de variable volatile serait une variable qui peut ĂŞtre modifiĂŠe par deux threads d'un programme multithreadĂŠ. ConsidĂŠrons le code suivant :
1 x = 10;
2 y = 20;
3 z = x;Si x pouvait ĂŞtre altĂŠrĂŠ par un autre thread, il est possible que l'autre thread change x entre les lignes 1 et 3, alors z ne vaudrait pas 10.
Cependant, si x n'a pas ĂŠtĂŠ dĂŠclarĂŠ comme volatile, le compilateur peut supposer que x est inchangĂŠ et positionner z Ă 10.
Une autre utilisation de volatile est d'empĂŞcher le compilateur d'utiliser un registre pour une variable.
VI. Tableaux▲
VI-A. Introduction▲
Un tableau est un bloc contigu de donnÊes en mÊmoire. Tous les ÊlÊments de la liste doivent être du même type et occuper exactement le même nombre d'octets en mÊmoire. En raison de ces propriÊtÊs, les tableaux permettent un accès efficace à une donnÊe par sa position (ou indice) dans le tableau.
L'adresse de n'importe quel ĂŠlĂŠment peut ĂŞtre calculĂŠe en connaissant les trois choses suivantes :
- l'adresse du premier ĂŠlĂŠment du tableau ;
- le nombre d'octets de chaque ĂŠlĂŠment ;
- l'indice de l'ĂŠlĂŠment.
Il est pratique de considĂŠrer l'indice du premier ĂŠlĂŠment du tableau comme ĂŠtant 0 (comme en C). Il est possible d'utiliser d'autres valeurs pour le premier indice, mais cela complique les calculs.
VI-A-1. DĂŠfinir des tableaux▲
VI-A-1-a. DĂŠfinir des tableaux dans les segments data et bss▲
Pour dĂŠfinir un tableau initialisĂŠ dans le segment data, utilisez les directives db, dw, etc. normales. directives. NASM fournit ĂŠgalement une directive utile appelĂŠe TIMES qui peut ĂŞtre utilisĂŠe pour rĂŠpĂŠter une expression de nombreuses fois sans avoir Ă la dupliquer Ă la main. La Figure 5.1 montre plusieurs exemples.

Pour dĂŠfinir un tableau non initialisĂŠ dans le segment bss, utilisez les directives resb, resw, etc. Souvenez-vous que ces directives ont un opĂŠrande qui spĂŠcifie le nombre d'unitĂŠs mĂŠmoire Ă rĂŠserver. La Figure 5.1 montre ĂŠgalement des exemples de ces types de dĂŠfinitions.
VI-A-1-b. DĂŠfinir des tableaux comme variables locales▲
Il n'y a pas de manière directe de dĂŠfinir un tableau comme variable locale sur la pile. Comme prĂŠcĂŠdemment, on calcule le nombre total d'octets requis pour toutes les variables locales, y compris les tableaux, et on l'Ă´te de ESP (soit directement, soit en utilisant l'instruction ENTER). Par exemple, si une fonction a besoin d'une variable caractère, deux entiers double-mot et un tableau de 50 ĂŠlĂŠments d'un mot, il faudrait 1+2Ă4+50Ă2 = 109 octets.
Cependant, le nombre ôtÊ de ESP doit être un multiple de quatre (112 dans ce cas) pour maintenir ESP sur un multiple de double-mot. On peut organiser les variables dans ces 109 octets de plusieurs façons. La Figure 5.2 montre deux manières possibles.
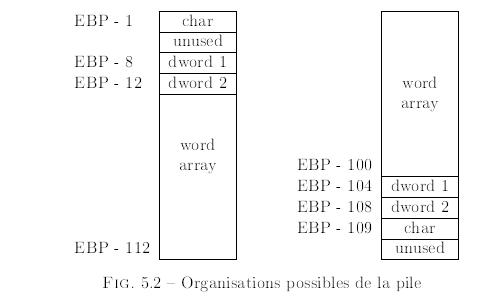
La partie inutilisÊe sert à maintenir les doubles-mots sur des adresses multiples de doubles-mots afin d'accÊlÊrer les accès mÊmoire.
VI-A-2. AccĂŠder aux ĂŠlĂŠments de tableaux▲
Il n'y a pas d'opĂŠrateur [ ] en langage assembleur comme en C. Pour accĂŠder Ă un ĂŠlĂŠment d'un tableau, son adresse doit ĂŞtre calculĂŠe. ConsidĂŠrons les deux dĂŠfinitions de tableau suivantes :
array1 db 5, 4, 3, 2, 1 ; tableau d'octets
array2 dw 5, 4, 3, 2, 1 ; tableau de motsVoici quelques exemples utilisant ces tableaux :
1 mov al, [array1] ; al = array1[0]
2 mov al, [array1 + 1] ; al = array1[1]
3 mov [array1 + 3], al ; array1[3] = al
4 mov ax, [array2] ; ax = array2[0]
5 mov ax, [array2 + 2] ; ax = array2[1] (PAS array2[2]!)
6 mov [array2 + 6], ax ; array2[3] = ax
7 mov ax, [array2 + 1] ; ax = ??Ă la ligne 5, l'ĂŠlĂŠment 1 du tableau de mots est rĂŠfĂŠrencĂŠ, pas l'ĂŠlĂŠment 2.
Pourquoi ? Les mots sont des unitĂŠs de deux octets, donc pour se dĂŠplacer Ă l'ĂŠlĂŠment suivant d'un tableau de mots, on doit se dĂŠplacer de deux octets, pas d'un seul.
La ligne 7 lit un octet du premier ĂŠlĂŠment et un octet du suivant. En C, le compilateur regarde le type de pointeur pour dĂŠterminer de combien d'octets il doit se dĂŠplacer dans une expression utilisant l'arithmĂŠtique des pointeurs, afin que le programmeur n'ait pas Ă le faire.
Cependant, en assembleur, c'est au programmeur de prendre en compte la taille des ĂŠlĂŠments du tableau lorsqu'il se dĂŠplace parmi les ĂŠlĂŠments.
La Figure 5.3 montre un extrait de code qui additionne tous les ĂŠlĂŠments de array1 de l'exemple de code prĂŠcĂŠdent.

à la ligne 7, AX est ajoutÊ à DX. Pourquoi pas AL ? Premièrement, les deux opÊrandes de l'instruction ADD doivent avoir la même taille. Deuxièmement, il serait facile d'ajouter des octets et d'obtenir une somme qui serait trop grande pour tenir sur un octet. En utilisant DX, la somme peut atteindre 65 535. Cependant, il est important de rÊaliser que AH est Êgalement additionnÊ. C'est pourquoi, AH est positionnÊ à zÊro(24) à la ligne 3.
Les Figures 5.4 et 5.5 montrent deux manières alternatives de calculer la somme. Les lignes en italiques remplacent les lignes 6 et 7 de la Figure 5.3.


VI-A-3. Adressage indirect plus avancĂŠ▲
Ce n'est pas ĂŠtonnant, l'adressage indirect est souvent utilisĂŠ avec les tableaux. La forme la plus gĂŠnĂŠrale d'une rĂŠfĂŠrence mĂŠmoire indirecte est :
[ reg de base + facteur *reg d'index + constante ]oĂš :
reg de base est un des registres EAX, EBX, ECX, EDX, EBP, ESP, ESI ou EDI ;
facteur est 1, 2, 4 ou 8 (s'il vaut 1, le facteur est omis) ;
reg d'index est un des registres EAX, EBX, ECX, EDX, EBP, ESI, EDI (notez que ESP n'est pas dans la liste) ;
constante est une constante 32 bits. Cela peut ĂŞtre une ĂŠtiquette (ou une expression d'ĂŠtiquette).
VI-A-4. Exemple▲
Voici un exemple qui utilise un tableau et le passe Ă une fonction. Il utilise le programme array1c.c (dont le listing suit) comme pilote, pas le programme driver.c.
1 ?fine ARRAY_SIZE 100
2 ?fine NEW_LINE 10
3
4 segment .data
5 FirstMsg db "10 premiers ĂŠlĂŠments du tableau", 0
6 Prompt db "Entrez l'indice de l'ĂŠlĂŠment Ă afficher : ", 0
7 SecondMsg db "L'ĂŠlĂŠment %d vaut %d", NEW_LINE, 0
8 ThirdMsg db "ĂlĂŠments 20 Ă 29 du tableau", 0
9 InputFormat db "%d", 0
10
11 segment .bss
12 array resd ARRAY_SIZE
13
14 segment .text
15 extern _puts, _printf, _scanf, _dump_line
16 global _asm_main
17 _asm_main :
18 enter 4,0 ; variable locale dword en EBP - 4
19 push ebx
20 push esi
21
22 ; initialise le tableau Ă 100, 99, 98, 97...
23
24 mov ecx, ARRAY_SIZE
25 mov ebx, array
26 init_loop:
27 mov [ebx], ecx
28 add ebx, 4
29 loop init_loop
30
31 push dword FirstMsg ; affiche FirstMsg
32 call _puts
33 pop ecx
34
35 push dword 10
36 push dword array
37 call _print_array ; affiche les 10 premiers ĂŠlĂŠments du tableau
38 add esp, 8
39
40 ; demande Ă l'utilisateur l'indice de l'ĂŠlĂŠment
41 Prompt_loop:
42 push dword Prompt
43 call _printf
44 pop ecx
45
46 lea eax, [ebp-4] ; eax = adresse du dword local
47 push eax
48 push dword InputFormat
49 call _scanf
50 add esp, 8
51 cmp eax, 1 ; eax = valeur de retour de scanf
52 je InputOK
53
54 call _dump_line ; ignore le reste de la ligne et recommence
55 jmp Prompt_loop ; si la saisie est invalide
56
57 InputOK:
58 mov esi, [ebp-4]
59 push dword [array + 4*esi]
60 push esi
61 push dword SecondMsg ; affiche la valeur de l'ĂŠlĂŠment
62 call _printf
63 add esp, 12
64
65 push dword ThirdMsg ; affiche les ĂŠlĂŠments 20 Ă 29
66 call _puts
67 pop ecx
68
69 push dword 10
70 push dword array + 20*4 ; adresse de array[20]
71 call _print_array
72 add esp, 8
73
74 pop esi
75 pop ebx
76 mov eax, 0 ; retour au C
77 leave
78 ret
79
80 ;
81 ; routine _print_array
82 ; Routine appelable depuis le C qui affiche les ĂŠlĂŠments d'un tableau de doubles mots
83 ; comme des entiers signĂŠs.
84 ; Prototype C :
85 ; void print_array( const int * a, int n);
86 ; Paramètres :
87 ; a - pointeur vers le tableau Ă afficher (en ebp+8 sur la pile)
88 ; n - nombre d'entiers Ă afficher (en ebp+12 sur la pile)
89
90 segment .data
91 OutputFormat db "%-5d ]", NEW_LINE, 0
92
93 segment .text
94 global _print_array
95 _print_array :
96 enter 0,0
97 push esi
98 push ebx
99
100 xor esi, esi ; esi = 0
101 mov ecx, [ebp+12] ; ecx = n
102 mov ebx, [ebp+8] ; ebx = adresse du tableau
103 print_loop :
104 push ecx ; printf change ecx !
105
106 push dword [ebx + 4*esi] ; empile tableau[esi]
107 push esi
108 push dword OutputFormat
109 call _printf
110 add esp, 12 ; retire les paramètres (laisse ecx !)
111
112 inc esi
113 pop ecx
114 loop print_loop
115
116 pop ebx
117 pop esi
118 leave
119 ret1 #include <stdio.h>
2
3 int asm_main( void );
4 void dump_line( void );
5
6 int main()
7 {
8 int ret_status ;
9 ret_status = asm_main();
10 return ret_status ;
11 }
12
13 /
14 fonction dump_line
15 retire tous les caractères restant sur la ligne courante dans le buffer d'entreÊ
16 /
17 void dump_line()
18 {
19 int ch;
20
21 while( (ch = getchar()) != EOF && ch != '\n')
22 / null body/ ;
23 }VI-A-4-a. L'instruction LEA revisitĂŠe▲
L'instruction LEA peut ĂŞtre utilisĂŠe dans d'autres cas que le calcul d'adresse.
Elle est assez couramment utilisĂŠe pour les calculs rapides. ConsidĂŠrons le code suivant :
lea ebx, [4*eax + eax]Il stocke la valeur de 5ĂEAX dans EBX. Utiliser LEA dans ce cas est Ă la fois plus simple et plus rapide que d'utiliser MUL. Cependant, il faut ĂŞtre conscient du fait que l'expression entre crochets doit ĂŞtre une adresse indirecte lĂŠgale.
Donc, par exemple, cette instruction ne peut pas ĂŞtre utilisĂŠe pour multiplier par 6 rapidement.
VI-A-5. Tableaux Multidimensionnels▲
Les tableaux multidimensionnels ne sont pas vraiment diffĂŠrents de ceux Ă une dimension dont nous avons dĂŠjĂ parlĂŠ. En fait, ils sont reprĂŠsentĂŠs en mĂŠmoire exactement comme cela, un tableau Ă une dimension.
VI-A-5-a. Tableaux Ă Deux Dimensions▲
Ce n'est pas ĂŠtonnant, le tableau multidimensionnel le plus simple est celui Ă deux dimensions. Un tableau Ă deux dimensions est souvent reprĂŠsentĂŠ comme une grille d'ĂŠlĂŠments. Chaque ĂŠlĂŠment est identifiĂŠ par une paire d'indices. Par convention, le premier indice est associĂŠ Ă la ligne et le second Ă la colonne.
ConsidÊrons un tableau avec trois lignes et deux colonnes dÊfini de la manière suivante :
int a [3][2];Le compilateur C rĂŠserverait de la place pour un tableau d'entiers de 6 (= 2 Ă 3) et placerait les ĂŠlĂŠments comme suit :

Ce que ce tableau tente de montrer et que l'ÊlÊment rÊfÊrencÊ comme a[0][0] est stockÊ au dÊbut du tableau de 6 ÊlÊments à une dimension. L'ÊlÊment a[0][1] est stockÊ à la position suivante (indice 1), etc. Chaque ligne du tableau à deux dimensions est stockÊe en mÊmoire de façon contigße. Le dernier ÊlÊment d'une ligne est suivi par le premier ÊlÊment de la suivante. On appelle cela la reprÊsentation au niveau ligne (rowwise) du tableau et c'est comme cela qu'un compilateur C/C++ reprÊsenterait le tableau.
Comment le compilateur dĂŠtermine oĂš a[i][j] se trouve dans la reprĂŠsentation au niveau ligne ? Une formule simple calcule l'indice Ă partir de i et j. La formule dans ce cas est 2i + j. Il n'est pas compliquĂŠ de voir comment on obtient cette formule. Chaque ligne fait deux ĂŠlĂŠments de long, donc le premier ĂŠlĂŠment de la ligne i est Ă l'emplacement 2i. Puis on obtient l'emplacement de la colonne j en ajoutant j Ă 2i. Cette analyse montre ĂŠgalement comment la formule est gĂŠnĂŠralisĂŠe Ă un tableau de N colonnes : N Ă i + j.
Notez que la formule ne dĂŠpend pas du nombre de lignes.
Pour illustrer, voyons comment gcc compile le code suivant (utilisant le tableau a dĂŠfini plus haut) :
x = a[ i ][ j ];La Figure 5.6 montre le code assembleur correspondant.

Donc, le compilateur convertit grossièrement le code en :
x = (&a[0][0] + 2i + j );et en fait, le programmeur pourrait l'Êcrire de cette manière et obtenir le même rÊsultat.
Il n'y a rien de magique Ă propos du choix de la reprĂŠsentation niveau ligne du tableau. Une reprĂŠsentation niveau colonne fonctionnerait ĂŠgalement :

Dans la reprÊsentation niveau colonne, chaque colonne est stockÊe de manière contigße. L'ÊlÊment [i][j] est stockÊ à l'emplacement i+3j. D'autres langages (FORTRAN, par exemple) utilisent la reprÊsentation niveau colonne.
C'est important lorsque l'on interface du code provenant de multiples langages.
VI-A-5-b. Dimensions supĂŠrieures Ă deux▲
Pour les dimensions supĂŠrieures Ă deux, la mĂŞme idĂŠe de base est appliquĂŠe. ConsidĂŠrons un tableau Ă trois dimensions :
int b [4][3][2];Ce tableau serait stockĂŠ comme s'il ĂŠtait composĂŠ de trois tableaux Ă deux dimensions, chacun de taille [3][2] stockĂŠs consĂŠcutivement en mĂŠmoire. Le tableau ci-dessous montre comment il commence :

La formule pour calculer la position de b[i][j][k] est 6i + 2j + k. Le 6 est dĂŠterminĂŠ par la taille des tableaux [3][2]. En gĂŠnĂŠral, pour un tableau de dimension a[L][M][N] l'emplacement de l'ĂŠlĂŠment a[i][j][k] sera M ĂN Ăi+N Ăj +k. Notez, lĂ encore, que la dimension L n'apparaĂŽt pas dans la formule.
Pour les dimensions plus grandes, le mĂŞme procĂŠdĂŠ est gĂŠnĂŠralisĂŠ. Pour un tableau Ă n dimensions de dimension D1 Ă Dn, l'emplacement d'un ĂŠlĂŠment repĂŠrĂŠ par les indices i1 Ă in est donnĂŠ par la formule :
D2 à D3 ¡ ¡ ¡ à Dn à i1 + D3 à D4 ¡ ¡ ¡ à Dn à i2 + ¡ ¡ ¡ + Dn à in?1 + in
ou pour les fanas de maths, on peut l'Êcrire de façon plus concise :
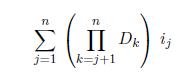
La première dimension, D1, n'apparaÎt pas dans la formule.
Pour la reprĂŠsentation au niveau colonne, la formule gĂŠnĂŠrale serait :
i1 +D1 Ăi2 +¡ ¡ ¡+D1 ĂD2 Ă¡ ¡ ¡ĂDn?2 Ăin?1 +D1 ĂD2 Ă¡ ¡ ¡ĂDn?1 Ăin
ou dans la notation des fanas de maths :
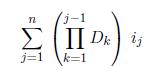
Dans ce cas, c'est la dernière dimension, Dn, qui n'apparaÎt pas dans la formule.
C'est lĂ que vous comprenez que l'auteur est un major de physique (ou la rĂŠfĂŠrence Ă FORTRAN vous avait dĂŠjĂ mis sur la voie ?)
VI-A-5-c. Passer des tableaux multidimensionnels comme paramètres en C▲
La reprĂŠsentation au niveau ligne des tableaux multidimensionnels a un effet direct sur la programmation C. Pour les tableaux Ă une dimension, la taille du tableau n'est pas nĂŠcessaire pour calculer l'emplacement en mĂŠmoire de n'importe quel ĂŠlĂŠment. Ce n'est pas vrai pour les tableaux multidimensionnels.
Pour accÊder aux ÊlÊments de ces tableaux, le compilateur doit connaÎtre toutes les dimensions sauf la première. Cela saute aux yeux lorsque l'on observe le prototype d'une fonction qui prend un tableau multidimensionnel comme paramètre. Ce qui suit ne compilera pas :
void f ( int a [ ][ ] ); / pas d' information sur la dimension /Cependant, ce qui suit compile :
void f ( int a [ ][2] );Tout tableau à deux dimensions à deux colonnes peut être passÊ à cette fonction. La première dimension n'est pas nÊcessaire(25).
Ne confondez pas avec une fonction ayant ce prototype :
void f ( int a [ ] );Cela dĂŠfinit un tableau Ă une dimension de pointeurs sur des entiers (qui peut Ă son tour ĂŞtre utilisĂŠ pour crĂŠer un tableau de tableaux qui se comportent plus comme un tableau Ă deux dimensions).
Pour les tableaux de dimensions supÊrieures, toutes les dimensions sauf la première doivent être donnÊes pour les paramètres. Par exemple, un paramètre tableau à quatre dimensions peut être passÊ de la façon suivante :
void f ( int a [ ][4][3][2] );VI-B. Instructions de tableaux/chaĂŽnes▲
La famille des processeurs 80x86 fournit plusieurs instructions conçues pour travailler avec les tableaux. Ces instructions sont appelÊes instructions de chaÎnes. Elles utilisent les registres d'index (ESI et EDI) pour effectuer une opÊration puis incrÊmentent ou dÊcrÊmentent automatiquement l'un des registres d'index ou les deux. Le drapeau de direction (DF) dans le registre FLAGS dÊtermine si les registres d'index sont incrÊmentÊs ou dÊcrÊmentÊs.
Il y a deux instructions qui modifient le drapeau de direction :
CLD ĂŠteint le drapeau de direction. Les registres d'index sont alors incrĂŠmentĂŠs ;
STD allume le drapeau de direction. Les registres d'index sont alors dĂŠcrĂŠmentĂŠs.
Une erreur très courante dans la programmation 80x86 est d'oublier de positionner le drapeau de direction. Cela conduit souvent à un code qui fonctionne la plupart du temps (lorsque le drapeau de direction est dans la position dÊsirÊe), mais ne fonctionne pas tout le temps.
VI-B-1. Lire et ĂŠcrire en mĂŠmoire▲
Les instructions de chaÎnes les plus simples lisent ou Êcrivent en mÊmoire, ou les deux. Elles peuvent lire ou Êcrire un octet, un mot ou un double-mot à la fois. La Figure 5.7 montre ces instructions avec une brève description de ce qu'elles font en pseudo-code.
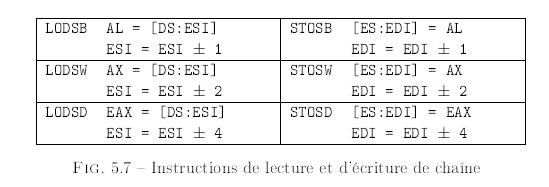
Il y a plusieurs choses à noter ici. Tout d'abord, ESI est utilisÊ pour lire et EDI pour Êcrire. C'est facile à retenir si l'on se souvient que SI signifie Source Index (Indice Source) et DI Destination Index (Indice de Destination). Ensuite, notez que le registre qui contient la donnÊe est fixe (AL, AX ou EAX). Enfin, notez que les instructions de stockage utilisent ES pour dÊterminer le segment dans lequel Êcrire, pas DS. En programmation en mode protÊgÊ, ce n'est habituellement pas un problème, puisqu'il n'y a qu'un segment de donnÊes et ES est automatiquement initialisÊ pour y faire rÊfÊrence (tout comme DS). Cependant, en programmation en mode rÊel, il est très important pour le programmeur d'initialiser ES avec la valeur de sÊlecteur de segment correcte(26). La Figure 5.8 montre un exemple de l'utilisation de ces instructions qui copie un tableau dans un autre.

La combinaison des instructions LODSx et STOSx (comme aux lignes 13 et 14 de la Figure 5.8) est très courante. En fait, cette combinaison peut être effectuÊe par une seule instruction de chaÎnes MOVSx. La Figure 5.9 dÊcrit les opÊrations effectuÊes par cette instruction.

Les lignes 13 et 14 de la Figure 5.8 pourraient ĂŞtre remplacĂŠes par une seule instruction MOVSD avec le mĂŞme rĂŠsultat. La seule diffĂŠrence serait que le registre EAX ne serait pas utilisĂŠ du tout dans la boucle.
VI-B-2. Le prĂŠfixe d'instruction REP▲
La famille 80x86 fournit un prĂŠfixe d'instruction spĂŠcial(27) appelĂŠ REP qui peut ĂŞtre utilisĂŠ avec les instructions de chaĂŽnes prĂŠsentĂŠes ci-dessus. Ce prĂŠfixe indique au processeur de rĂŠpĂŠter l'instruction de chaĂŽnes qui suit un nombre prĂŠcis de fois. Le registre ECX est utilisĂŠ pour compter les itĂŠrations (exactement comme pour l'instruction LOOP). En utilisant le prĂŠfixe REP, la boucle de la Figure 5.8 (lignes 12 Ă 15) pourrait ĂŞtre remplacĂŠe par une seule ligne :
rep movsdLa Figure 5.10 montre un autre exemple qui met Ă zĂŠro le contenu d'un tableau.

VI-B-3. Instructions de comparaison de chaĂŽnes▲
La Figure 5.11 montre plusieurs nouvelles instructions de chaÎnes qui peuvent être utilisÊes pour comparer des donnÊes en mÊmoire entre elles ou avec des registres. Elles sont utiles pour comparer des tableaux ou effectuer des recherches. Elles positionnent le registre FLAGS exactement comme l'instruction CMP. Les instructions CMPSx comparent les emplacements mÊmoire correspondants et les instructions SCASx scannent des emplacements mÊmoire pour une valeur particulière.
La Figure 5.12 montre un court extrait de code qui recherche le nombre 12 dans un tableau de doubles-mots.

L'instruction SCASD Ă la ligne 10 ajoute toujours 4 Ă EDI, mĂŞme si la valeur recherchĂŠe est trouvĂŠe. Donc, si l'on veut trouver l'adresse du 12 dans le tableau, il est nĂŠcessaire de soustraire 4 de EDI (comme le fait la ligne 16).
VI-B-4. Les prĂŠfixes d'instruction REPx▲
Il y a plusieurs autres prĂŠfixes d'instruction du mĂŞme genre que REP qui peuvent ĂŞtre utilisĂŠs avec les instructions de comparaison de chaĂŽnes.
La Figure 5.13 montre les deux nouveaux prĂŠfixes et dĂŠcrit ce qu'ils font.

REPE et REPZ sont simplement des synonymes pour le mĂŞme prĂŠfixe (comme le sont REPNE et REPNZ). Si l'instruction de comparaison de chaĂŽnes rĂŠpĂŠtĂŠe stoppe Ă cause du rĂŠsultat de la comparaison, le ou les registres d'index sont quand mĂŞme incrĂŠmentĂŠs et ECX dĂŠcrĂŠmentĂŠ, cependant, le registre FLAGS contient toujours l'ĂŠtat qu'il avait Ă la fin de la rĂŠpĂŠtition. Donc, il est possible d'utiliser le drapeau Z pour dĂŠterminer si la comparaison s'est arrĂŞtĂŠe Ă cause de son rĂŠsultat ou si c'est parce que ECX a atteint zĂŠro.
Pourquoi ne peut-on pas simplement regarder si ECX est à zÊro après la comparaison rÊpÊtÊe ?
La Figure 5.14 montre un extrait de code qui dĂŠtermine si deux blocs de mĂŠmoire sont ĂŠgaux.

Le JE de la ligne 7 de l'exemple vĂŠrifie le rĂŠsultat de l'instruction prĂŠcĂŠdente. Si la comparaison s'est arrĂŞtĂŠe parce qu'elle a trouvĂŠ deux octets diffĂŠrents, le drapeau Z sera toujours ĂŠteint et aucun branchement n'est effectuĂŠ, cependant, si la comparaison s'est arrĂŞtĂŠe parce que ECX a atteint zĂŠro, le drapeau Z sera toujours allumĂŠ et le code se branche Ă l'ĂŠtiquette equal.
VI-B-5. Exemple▲
Cette section contient un fichier source assembleur avec plusieurs fonctions qui implÊmentent des opÊrations sur les tableaux en utilisant des instructions de chaÎnes. Beaucoup de ces fonctions font doublons avec des fonctions familières de la bibliothèque C.
1 global _asm_copy, _asm_find, _asm_strlen, _asm_strcpy
2
3 segment .text
4 ; fonction _asm_copy
5 ; copie deux blocs de mĂŠmoire
6 ; prototype C
7 ; void asm_copy( void * dest, const void * src, unsigned sz);
8 ; paramètres :
9 ; dest - pointeur sur le tampon vers lequel copier
10 ; src - pointeur sur le tampon depuis lequel copier
11 ; sz - nombre d'octets Ă copier
12
13 ; ci-dessous, quelques symboles utiles sont dĂŠfinis
14
15 ?fine dest [ebp+8]
16 ?fine src [ebp+12]
17 ?fine sz [ebp+16]
18 _asm_copy :
19 enter 0, 0
20 push esi
21 push edi
22
23 mov esi, src ; esi = adresse du tampon depuis lequel copier
24 mov edi, dest ; edi = adresse du tampon vers lequel copier
25 mov ecx, sz ; ecx = nombre d'octets Ă copier
26
27 cld ; ĂŠteint le drapeau de direction
28 rep movsb ; exĂŠcute movsb ECX fois
29
30 pop edi
31 pop esi
32 leave
33 ret
34
35
36 ; fonction _asm_find
37 ; recherche un octet donnĂŠ en mĂŠmoire
38 ; void * asm_find( const void * src, char target, unsigned sz);
39 ; paramètres :
40 ; src - pointeur sur le tampon dans lequel chercher
41 ; target - octet Ă rechercher
42 ; sz - nombre d'octets dans le tampon
43 ; valeur de retour :
44 ; si l'ÊlÊment recherchÊ est trouvÊ, un pointeur vers sa première occurrence dans le tampon
45 ; est retournĂŠ
46 ; sinon, NULL est retournĂŠ
47 ; NOTE : l'ĂŠlĂŠment Ă rechercher est un octet, mais il est empilĂŠ comme une valeur dword.
48 ; La valeur de l'octet est stockĂŠe dans les 8 bits de poids faible.
49 ;
50 ?fine src [ebp+8]
51 ?fine target [ebp+12]
52 ?fine sz [ebp+16]
53
54 _asm_find :
55 enter 0,0
56 push edi
57
58 mov eax, target ; al a la valeur recherchĂŠe
59 mov edi, src
60 mov ecx, sz
61 cld
62
63 repne scasb ; scanne jusqu'Ă ce que ECX == 0 ou [ES:EDI] == AL
64
65 je found_it ; si le drapeau zĂŠro est allumĂŠ, on a trouvĂŠ
66 mov eax, 0 ; si pas trouvĂŠ, retourner un pointeur NULL
67 jmp short quit
68 found_it :
69 mov eax, edi
70 dec eax ; si trouvĂŠ retourner (DI - 1)
71 quit :
72 pop edi
73 leave
74 ret
75
76
77 ; fonction _asm_strlen
78 ; retourne la taille d'une chaĂŽne
79 ; unsigned asm_strlen( const char * );
80 ; paramètre :
81 ; src - pointeur sur la chaĂŽne
82 ; valeur de retour :
83 ; nombre de caractères dans la chaÎne (sans compter le 0 terminal) (dans EAX)
84
85 ?fine src [ebp + 8]
86 _asm_strlen :
87 enter 0,0
88 push edi
89
90 mov edi, src ; edi = pointeur sur la chaĂŽne
91 mov ecx, 0FFFFFFFFh ; utilise la plus grande valeur possible de ECX
92 xor al,al ; al = 0
93 cld
94
95 repnz scasb ; recherche le 0 terminal
96
97 ;
98 ; repnz ira un cran trop loin, donc la longueur vaut FFFFFFFE - ECX,
99 ; pas FFFFFFFF - ECX
100 ;
101 mov eax,0FFFFFFFEh
102 sub eax, ecx ; longueur = 0FFFFFFFEh - ecx
103
104 pop edi
105 leave
106 ret
107
108 ; fonction _asm_strcpy
109 ; copie une chaĂŽne
110 ; void asm_strcpy( char * dest, const char * src);
111 ; paramètres :
112 ; dest - pointeur sur la chaine vers laquelle copier
113 ; src - pointeur sur la chaĂŽne depuis laquelle copier
114 ;
115 ?fine dest [ebp + 8]
116 ?fine src [ebp + 12]
117 _asm_strcpy :
118 enter 0,0
119 push esi
120 push edi
121
122 mov edi, dest
123 mov esi, src
124 cld
125 cpy_loop:
126 lodsb ; charge AL & incrĂŠmente SI
127 stosb ; stocke AL & incrĂŠmente DI
128 or al, al ; positionne les drapeaux de condition
129 jnz cpy_loop ; si l'on n'est pas après le 0 terminal, on continue
130
131 pop edi
132 pop esi
133 leave
134 ret1 #include <stdio.h>
2
3 #dene STR_SIZE 30
4 / prototypes /
5
6 void asm_copy( void , const void , unsigned ) __attribute__((cdecl));
7 void asm_nd( const void ,
8 char target , unsigned ) __attribute__((cdecl));
9 unsigned asm_strlen( const char ) __attribute__((cdecl));
10 void asm_strcpy( char , const char ) __attribute__((cdecl));
11
12 int main()
13 {
14 char st1 [STR_SIZE] = "chaine test";
15 char st2 [STR_SIZE];
16 char st ;
17 char ch;
18
19 asm_copy(st2, st1, STR_SIZE); / copie les 30 caractères de la chaine /
20 printf ("%s\n", st2);
21
22 printf ("Entrez un è caractre : " ); / recherche un octet dans la Îchane /
23 scanf("%c%[^\n]", &ch);
24 st = asm_nd(st2, ch, STR_SIZE);
25 if ( st )
26 printf ("ĂŠTrouv : %s\n", st );
27 else
28 printf ("Pas ĂŠtrouv\n");
29
30 st1 [0] = 0;
31 printf ("Entrez une ĂŽchane :");
32 scanf("%s", st1);
33 printf ("longueur = %u\n", asm_strlen(st1));
34
35 asm_strcpy( st2, st1 ); / copie des ĂŠdonnes dans la ĂŽchane /
36 printf ("%s\n", st2 );
37
38 return 0;
39 }VII. Virgule flottante▲
VII-A. ReprĂŠsentation en virgule flottante▲
VII-A-1. Nombres binaires non entiers▲
Lorsque nous avons parlĂŠ des systèmes numĂŠriques dans le premier chapitre, nous n'avons abordĂŠ que les nombres entiers. Ăvidemment, il est possible de reprĂŠsenter des nombres non entiers dans des bases autres que le dĂŠcimal.
En dĂŠcimal, les chiffres Ă droite du symbole dĂŠcimal sont associĂŠs Ă des puissances
nĂŠgatives de 10 :
0, 123 = 1 Ă 10-1 + 2 Ă 10-2 + 3 Ă 10-3
Ce n'est pas Êtonnant, les nombres binaires fonctionnent de la même façon :
0, 1012 = 1 Ă 2-1 + 0 Ă 2-2 + 1 Ă 2-3 = 0, 625
Cette idĂŠe peut ĂŞtre associĂŠe avec les mĂŠthodes appliquĂŠes aux entiers dans le Chapitre II pour convertir un nombre quelconque :
110, 0112 = 4 + 2 + 0, 25 + 0, 125 = 6, 375
Convertir du binaire vers le dÊcimal n'est pas très difficile non plus. Divisez le nombre en deux parties : entière et dÊcimale. Convertissez la partie entière en binaire en utilisant les mÊthodes du Chapitre II, la partie dÊcimale est convertie en utilisant la mÊthode dÊcrite ci-dessous.
ConsidÊrons une partie dÊcimale binaire dont les bits sont notÊs a, b, c⌠Le nombre en binaire ressemble alors à :
0, abcdefâŚ
Multipliez le nombre par deux. La reprĂŠsentation du nouveau nombre sera :
a, bcdefâŚ
Notez que le premier bit est maintenant en tĂŞte. Remplacez le a par 0 pour obtenir :
0, bcdefâŚ
et multipliez Ă nouveau par deux, vous obtenez :
b, cdefâŚ
Maintenant le deuxième bit (b) est à la première place. Cette procÊdure peut être rÊpÊtÊe jusqu'à ce qu'autant de bits que nÊcessaire soient trouvÊs.
La Figure 6.1 montre un exemple rĂŠel qui converti 0,5625 en binaire.
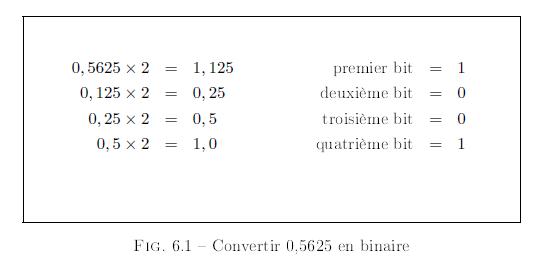
La mĂŠthode s'arrĂŞte lorsque la partie dĂŠcimale arrive Ă zĂŠro.
Prenons un autre exemple, considÊrons la conversion de 23,85 en binaire, il est facile de convertir la partie entière (23 = 101112), mais qu'en est-il de la partie dÊcimale (0, 85) ?
La Figure 6.2 montre le dĂŠbut de ce calcul.

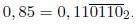
Une consĂŠquence importante du calcul ci-dessus est que 23,85 ne peut pas ĂŞtre reprĂŠsentĂŠ exactement en binaire en utilisant un nombre fini de bits (tout comme 1/3 ne peut pas ĂŞtre reprĂŠsentĂŠ en dĂŠcimal avec un nombre fini de chiffres). Comme le montre ce chapitre, les variables float et double en C sont stockĂŠes en binaire. Donc, les valeurs comme 23,85 ne peuvent pas ĂŞtre stockĂŠes exactement dans ce genre de variables. Seule une approximation de 23,85 peut ĂŞtre stockĂŠe.
Pour simplifier le matĂŠriel, les nombres en virgule flottante sont stockĂŠs dans un format standard. Ce format utilise la notation scientifique (mais en binaire, en utilisant des puissances de 2, pas de 10). Par exemple, 23,85 ou 10111, 11011001100110âŚ2 serait stockĂŠ sous la forme :
1, 011111011001100110⌠à 2100
(oĂš l'exposant (100) est en binaire). Un nombre en virgule flottante normalisĂŠ a la forme :
1, ssssssssssssssss Ă 2eeeeeee
oĂš 1, sssssssssssss est la mantisse et eeeeeeee est l'exposant.
VII-A-2. ReprĂŠsentation en virgule flottante IEEE▲
L'IEEE (Institute of Electrical and Electronic Engineers) est une organisation internationale qui a conçu des formats binaires spÊcifiques pour stocker les nombres en virgule flottante. Ce format est utilisÊ sur la plupart des ordinateurs (mais pas tous !) fabriquÊs de nos jours. Souvent, il est supportÊ par le matÊriel de l'ordinateur lui-même. Par exemple, les coprocesseurs numÊriques (ou arithmÊtiques) d'Intel (qui sont intÊgrÊs à tous leurs processeurs depuis le Pentium) l'utilisent. L'IEEE dÊfinit deux formats diffÊrents avec des prÊcisions diffÊrentes : simple et double prÊcision. La simple prÊcision est utilisÊe pour les variables float en C et la double prÊcision pour les variables double.
Le coprocesseur arithmÊtique d'Intel utilise Êgalement une troisième prÊcision plus ÊlevÊe appelÊe prÊcision Êtendue. En fait toutes les donnÊes dans le coprocesseur sont dans ce format. Lorsqu'elles sont stockÊes en mÊmoire depuis le coprocesseur, elles sont converties soit en simple, soit en double prÊcision automatiquement(28). La prÊcision Êtendue utilise un format gÊnÊral lÊgèrement diffÊrent des formats float et double de l'IEEE, nous n'en parlerons donc pas ici.
VII-A-2-a. Simple prĂŠcision IEEE▲
La virgule flottante simple prĂŠcision utilise 32 bits pour encoder le nombre.
Elle est gĂŠnĂŠralement prĂŠcise jusqu'Ă 7 chiffres significatifs. Les nombres en virgule flottante sont gĂŠnĂŠralement stockĂŠs dans un format beaucoup plus compliquĂŠ que celui des entiers.
La Figure 6.3 montre le format de base d'un nombre en simple prĂŠcision IEEE.

Ce format a plusieurs inconvĂŠnients. Les nombres en virgule flottante n'utilisent pas la reprĂŠsentation en complĂŠment Ă 2 pour les nombres nĂŠgatifs. Ils utilisent une reprĂŠsentation en grandeur signĂŠe. Le bit 31 dĂŠtermine le signe du nombre.
L'exposant binaire n'est pas stockĂŠ directement. Ă la place, la somme de l'exposant et de 7F est stockĂŠe dans les bits 23 Ă 30, cet exposant dĂŠcalĂŠ est toujours positif ou nul.
La partie dĂŠcimale suppose une mantisse normalisĂŠe (de la forme 1, sssssssss).
Comme le premier bit est toujours un 1, le 1 de gauche n'est pas stockÊ ! Cela permet le stockage d'un bit additionnel à la fin et augmente donc lÊgèrement la prÊcision. Cette idÊe est appelÊe reprÊsentation en 1 masquÊ.
Il faut toujours garder à l'esprit que les octets 41 BE CC CD peuvent être interprÊtÊs de façons diffÊrentes selon ce qu'en fait le programme ! Vus comme un nombre en virgule flottante en simple prÊcision, ils reprÊsentent 23,850000381, mais vus comme un entier double-mot, ils reprÊsentent 1,103,023,309 ! Le processeur ne sait pas quelle est la bonne interprÊtation !
Comment serait stockĂŠ 23,85 ? Tout d'abord, il est positif, donc le bit de signe est Ă 0. Ensuite, l'exposant rĂŠel est 4, donc l'exposant dĂŠcalĂŠ est
7F + 4 = 8316.
Enfin, la fraction vaut 01111101100110011001100 (souvenez-vous que le 1 de tĂŞte est masquĂŠ). En les mettant bout Ă bout (pour clarifier les diffĂŠrentes sections du format en virgule flottante, le bit de signe et la fraction ont ĂŠtĂŠ soulignĂŠs et les bits ont ĂŠtĂŠ regroupĂŠs en groupes de 4 bits) :
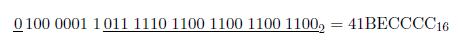
Cela ne fait pas exactement 23,85 (puisqu'il s'agit d'un binaire rÊpÊtitif). Si l'on convertit le chiffre ci-dessus en dÊcimal, on constate qu'il vaut approximativement 23,849998474, ce nombre est très proche de 23,85, mais n'est pas exactement le même. En rÊalitÊ, en C, 23,85 ne serait pas reprÊsentÊ exactement comme ci-dessus. Comme le bit le plus à gauche qui a ÊtÊ supprimÊ de la reprÊsentation exacte valait 1, le dernier bit est arrondi à 1, donc 23,85 serait reprÊsentÊ par 41 BE CC CD en hexa en utilisant la simple prÊcision. En dÊcimal, ce chiffre vaut 23,850000381 ce qui est une meilleure approximation de 23,85.
Comment serait reprĂŠsentĂŠ -23,85 ? Il suffit de changer le bit de signe :
C1 BE CC CD. Ne prenez pas le complĂŠment Ă 2 !
Certaines combinaisons de e et f ont une signification spĂŠciale pour les flottants IEEE. Le Tableau 6.1 dĂŠcrit ces valeurs.

Un infini est produit par un dĂŠpassement de capacitĂŠ ou une division par zĂŠro. Un rĂŠsultat indĂŠfini
est produit par une opĂŠration invalide comme rechercher la racine carrĂŠe d'un nombre nĂŠgatif, additionner deux infinis, etc.
Les nombres en simple prĂŠcision normalisĂŠs peuvent prendre des valeurs de
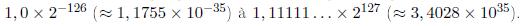
VII-A-2-b. Nombres dĂŠnormalisĂŠs▲
Les nombres dĂŠnormalisĂŠs peuvent ĂŞtre utilisĂŠs pour reprĂŠsenter des nombres avec des grandeurs trop petites Ă normaliser (i.e. infĂŠrieures Ă 1, 0 Ă 2-126).
Par exemple, considĂŠrons le nombre ![]()
Dans la forme normalisÊe, l'exposant est trop petit. Par contre, il peut être reprÊsentÊ sous une forme non normalisÊe : 0, 010012 à 2-127. Pour stocker ce nombre, l'exposant dÊcalÊ est positionnÊ à 0 (voir Tableau 6.1) et la partie dÊcimale est la mantisse complète du nombre Êcrite comme un produit avec 2-127 (i.e. tous les bits sont stockÊs, y compris le 1 à gauche du point dÊcimal). La reprÊsentation de 1, 001 à 2-129 est donc :
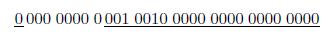
VII-A-2-c. Double prĂŠcision IEEE▲
La double prÊcision IEEE utilise 64 bits pour reprÊsenter les nombres et est prÊcise jusqu'à environ 15 chiffres significatifs. Comme le montre la Figure 6.4, le format de base est très similaire à celui de la simple prÊcision.

Plus de bits sont utilisĂŠs pour l'exposant dĂŠcalĂŠ (11) et la partie dĂŠcimale (52).
La plage de valeurs plus grande pour l'exposant dÊcalÊ a deux consÊquences. La première est qu'il est calculÊ en faisant la somme de l'exposant rÊel et de 3FF (1023) (pas 7F comme pour la simple prÊcision). Deuxièmement, une grande plage d'exposants rÊels (et donc une plus grande plage de grandeurs) est disponible. Les grandeurs en double-prÊcision peuvent prendre des valeurs entre environ 13-308 et 10308 .
C'est la plus grande taille du champ rĂŠservĂŠ Ă la partie dĂŠcimale qui est reponsable de l'augmentation du nombre de chiffres significatifs pour les valeurs doubles.
Pour illustrer cela, reprenons 23,85. L'exposant dĂŠcalĂŠ sera 4+3FF = 403 en hexa. Donc, la reprĂŠsentation double sera :
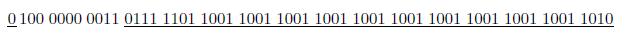
ou 40 37 D9 99 99 99 99 9A en hexa. Si l'on reconvertit ce nombre en dĂŠcimal, on trouve 23,8500000000000014 (il y a 12 zĂŠros !) ce qui est une approximation de 23,85 nettement meilleure.
La double prĂŠcision a les mĂŞmes valeurs spĂŠciales que la simple prĂŠcision(29).
Les nombres dÊnormalisÊs sont Êgalement très similaires. La seule diffÊrence principale est que les nombres doubles dÊnormalisÊs utilisent 2-1023 au lieu de 2-127.
VII-B. ArithmĂŠtique en virgule flottante▲
L'arithmĂŠtique en virgule flottante sur un ordinateur est diffĂŠrente de celle des mathĂŠmatiques. En mathĂŠmatiques, tous les nombres peuvent ĂŞtre considĂŠrĂŠs comme exacts. Comme nous l'avons montrĂŠ dans la section prĂŠcĂŠdente, sur un ordinateur beaucoup de nombres ne peuvent pas ĂŞtre reprĂŠsentĂŠs exactement avec un nombre fini de bits. Tous les calculs sont effectuĂŠs avec une prĂŠcision limitĂŠe. Dans les exemples de cette section, des nombres avec une mantisse de 8 bits seront utilisĂŠs pour plus de simplicitĂŠ.
VII-B-1. Addition▲
Pour additionner deux nombres en virgule flottante, les exposants doivent ĂŞtre ĂŠgaux. S'ils ne le sont pas dĂŠjĂ , alors, il faut les rendre ĂŠgaux en dĂŠcalant la mantisse du nombre ayant le plus petit exposant. Par exemple, considĂŠrons
10, 375 + 6, 34375 = 16, 71875 ou en binaire :

Ces deux nombres n'ont pas le mĂŞme exposant, donc on dĂŠcale la mantisse pour rendre les exposants ĂŠgaux, puis on effectue l'addition :

Notez que le dĂŠcalage de 1, 1001011 Ă 22 supprime le 1 de tĂŞte et arrondi plus tard le rĂŠsultat en 0, 1100110 Ă 23. Le rĂŠsultat de l'addition, 10, 0001100 Ă 23 ou 1, 00001100 Ă 24), est ĂŠgal Ă
10000,1102 ou 16,75, ce n'est pas ĂŠgal Ă la rĂŠponse exacte (16,71875) ! Il ne s'agit que d'une approximation due aux erreurs d'arrondi du processus d'addition.
Il est important de rĂŠaliser que l'arithmĂŠtique en virgule flottante sur un ordinateur (ou une calculatrice) est toujours une approximation. Les lois des mathĂŠmatiques ne fonctionnent pas toujours avec les nombres en virgule flottante sur un ordinateur. Les mathĂŠmatiques supposent une prĂŠcision infinie qu'aucun ordinateur ne peut atteindre. Par exemple, les mathĂŠmatiques nous apprennent que (a + b) ? b = a, cependant, ce n'est pas forcĂŠment exactement vrai sur un ordinateur !
VII-B-2. Soustraction▲
La soustraction fonctionne d'une façon similaire à l'addition et souffre des mêmes problèmes. Par exemple, considÊrons 16, 75 ? 15, 9375 = 0, 8125 :
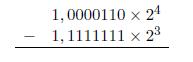
DĂŠcaler 1, 1111111 Ă 23 donne (en arrondissant) 1, 0000000 Ă 24

VII-B-3. Multiplication et division▲
Pour la multiplication, les mantisses sont multiplĂŠes et les exposants sont additionnĂŠs. ConsidĂŠrons 10, 375 Ă 2, 5 = 25, 9375 :

Bien sĂťr, le rĂŠsultat rĂŠel serait arrondi Ă 8 bits pour donner :
1, 1010000 Ă 24 = 11010, 0002 = 26
La division est plus compliquÊe, mais souffre des mêmes problèmes avec des erreurs d'arrondi.
VII-B-4. ConsĂŠquences sur la programmation▲
Le point essentiel de cette section est que les calculs en virgule flottante ne sont pas exacts. Le programmeur doit en ĂŞtre conscient. Une erreur courante que les programmeurs font avec les nombres en virgule flottante est de les comparer en supposant qu'un calcul est exact. Par exemple, considĂŠrons une fonction appelĂŠe f(x) qui effectue un calcul complexe et un programme qui essaie de trouver la racine de la fonction(30). On peut ĂŞtre tentĂŠ d'utiliser l'expression suivante pour vĂŠrifier si x est une racine :
if ( f(x) == 0.0 )Mais, que se passe-t-il si f(x) retourne 1Ă10-30 ? Cela signifie très probablement que x est une très bonne approximation d'une racine rĂŠelle, cependant, l'ĂŠgalitĂŠ ne sera pas vĂŠrifiĂŠe. Il n'y a peut-ĂŞtre aucune valeur en virgule flottante IEEE de x qui renvoie exactement zĂŠro, en raison des erreurs d'arrondi dans f(x).
Une meilleure mĂŠthode serait d'utiliser :
if ( fabs(f(x)) < EPS )oÚ EPS est une macro dÊfinissant une très petite valeur positive (du genre 1 x 10-10). Cette expression est vraie dès que f(x) est très proche de zÊro.
En gĂŠnĂŠral, pour comparer une valeur en virgule flottante (disons x) Ă une autre (y), on utilise :
if ( fabs(x − y)/fabs(y) < EPS )VII-C. Le coprocesseur arithmĂŠtique▲
VII-C-1. MatĂŠriel▲
Les premiers processeurs Intel n'avaient pas de support matÊriel pour les opÊrations en virgule flottante. Cela ne signifie pas qu'ils ne pouvaient pas effectuer de telles opÊrations. Cela signifie seulement qu'elles devaient être rÊalisÊes par des procÊdures composÊes de beaucoup d'instructions qui n'Êtaient pas en virgule flottante. Pour ces systèmes, Intel fournissait une puce appelÊe coprocesseur mathÊmatique. Un coprocesseur mathÊmatique a des instructions machine qui effectuent beaucoup d'opÊrations en virgule flottante beaucoup plus rapidement qu'en utilisant une procÊdure logicielle (sur les premiers processeurs, au moins 10 fois plus vite !). Le coprocesseur pour le 8086/8088 s'appelait le 8087, pour le 80286, il y avait un 80287 et pour le 80386, un 80387, le processeur 80486DX intÊgrait le coprocesseur mathÊmatique dans le 80486 lui-même(31). Depuis le Pentium, toutes les gÊnÊrations de processeurs 80x86 ont un coprocesseur mathÊmatique intÊgrÊ. Cependant, on le programme toujours comme s'il s'agissait d'une unitÊ sÊparÊe. Même les systèmes plus anciens sans coprocesseur peuvent installer un logiciel qui Êmule un coprocesseur mathÊmatique. Cet Êmulateur est automatiquement activÊ lorsqu'un programme exÊcute une instruction du coprocesseur et lance la procÊdure logicielle qui produit le même rÊsultat que celui qu'aurait donnÊ le coprocesseur (bien que cela soit plus lent, bien sÝr).
Le coprocesseur arithmÊtique a huit registres de virgule flottante. Chaque registre contient 80 bits de donnÊes. Les nombres en virgule flottante sont toujours stockÊs sous la forme de nombres 80 bits en prÊcision Êtendue dans ces registres. Les registres sont appelÊs ST0, ST1, ST2⌠ST7. Les registres en virgule flottante sont utilisÊs diffÊremment des registres entiers du processeur principal. Ils sont organisÊs comme une pile. Souvenez-vous qu'une pile est une liste Last-In First-Out (LIFO, dernier entrÊ, premier sorti). ST0 fait toujours rÊfÊrence à la valeur au sommet de la pile. Tous les nouveaux nombres sont ajoutÊs au sommet de la pile. Les nombres existants sont dÊcalÊs vers le bas pour faire de la place au nouveau.
Il y a ĂŠgalement un registre de statut dans le coprocesseur arithmĂŠtique.
Il a plusieurs drapeaux. Seuls les 4 drapeaux utilisĂŠs pour les comparaisons seront traitĂŠs : C0, C1, C2 et C3. Leur utilisation est traitĂŠe plus tard.
VII-C-2. Instructions▲
Pour faciliter la distinction entre les instructions du processeur normal et celles du coprocesseur, tous les mnĂŠmoniques du coprocesseur commencent par un F.
VII-C-2-a. Chargement et stockage▲
Il y a plusieurs instructions qui chargent des donnĂŠes au sommet de la pile du coprocesseur :
FLD source charge un nombre en virgule flottante depuis la mĂŠmoire vers
le sommet de la pile. La source peut ĂŞtre un nombre en simple,
double ou prĂŠcision ĂŠtendue ou un registre du coprocesseur.
FILD source lit un entier depuis la mĂŠmoire, le convertit en flottant et stocke le rĂŠsultat au sommet de la pile. La source peut ĂŞtre un mot, un double-mot ou un quadruple-mot.
FLD1 Stocke un 1 au sommet de la pile.
FLDZ Stocke un zĂŠro au sommet de la pile.
Il y a ĂŠgalement plusieurs instructions qui dĂŠplacent les donnĂŠes depuis la pile vers la mĂŠmoire. Certaines de ces instructions retirent le nombre de la pile en mĂŞme temps qu'elles le dĂŠplacent.
FST dest stocke le sommet de la pile (ST0) en mĂŠmoire. La destination peut ĂŞtre un nombre en simple ou double prĂŠcision ou un registre du coprocesseur.
FSTP dest stocke le sommet de la pile en mĂŠmoire, exactement comme FST ; cependant, une fois le nombre stockĂŠ, sa valeur est retirĂŠe de la pile. La destination peut ĂŞtre un nombre en simple, double ou prĂŠcision ĂŠtendue ou un registre du coprocesseur.
FIST dest stocke la valeur au sommet de la pile convertie en entier en mÊmoire. La destination peut être un mot ou un double-mot. La pile en elle-même reste inchangÊe. La façon dont est converti le nombre en entier dÊpend de certains bits dans le mot de contrôle du coprocesseur. Il s'agit d'un registre d'un mot spÊcial (pas en virgule flottante) qui contrôle le fonctionnement du coprocesseur. Par dÊfaut, le mot de contrôle est initialisÊ afin qu'il arrondisse à l'entier le plus proche lorsqu'il convertit vers un entier. Cependant, les instructions FSTCW (Store Control Word, stocker le mot de contrôle) et FLDCW (Load Control Word, charger le mot de contrôle) peuvent être utilisÊes pour changer ce comportement.
FISTP dest identique Ă FIST sauf en deux points. Le sommet de la pile est supprimĂŠ et la destination peut ĂŠgalement ĂŞtre un quadruple-mot.
Il y a deux autres instructions qui peuvent placer ou retirer des donnĂŠes de la pile.
FXCH STn ĂŠchange les valeurs de ST0 et STn sur la pile (oĂš n est un numĂŠro de registre entre 1 et 7).
FFREE STn libère un registre sur la pile en le marquant comme inutilisÊ ou vide.
VII-C-2-b. Addition et soustraction▲
Chacune des instructions d'addition calcule la somme de ST0 et d'un autre opĂŠrande. Le rĂŠsultat est toujours stockĂŠ dans un registre du coprocesseur.
FADD source ST0 += source . La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FADD dest, ST0 dest += ST0. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FADDP dest ou FADDP dest, STO dest += ST0 puis ST0 est retirĂŠ de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FIADD source ST0 += (float) source . Ajoute un entier Ă ST0. La source doit ĂŞtre un mot ou un double-mot en mĂŠmoire.
Il y a deux fois plus d'instructions pour la soustraction que pour l'addition, car l'ordre des opĂŠrandes est important pour la soustraction (i.e. a+b = b+a, mais a?b ? b?a !). Pour chaque instruction, il y a un miroir qui effectue la soustraction dans l'ordre inverse. Ces instructions inverses se finissent toutes soit par R soit par RP. La Figure 6.5 montre un court extrait de code qui ajoute les ĂŠlĂŠments d'un tableau de doubles.

Au niveau des lignes 10 et 13, il faut spĂŠcifier la taille de l'opĂŠrande mĂŠmoire. Sinon l'assembleur ne saurait pas si l'opĂŠrande mĂŠmoire est un float (dword) ou un double (qword).
FSUB source ST0 -= source. La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FSUBR source ST0 = source - ST0. La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FSUB dest, ST0 dest -= ST0. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FSUBR dest, ST0 dest = ST0 - dest . La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FSUBP dest ou FSUBP dest, STO dest -= ST0 puis retire ST0 de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FSUBRP dest ou FSUBRP dest, ST0 dest = ST0 - dest puis retire ST0 de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FISUB source ST0 -= (float) source . Soustrait un entier de ST0. La source doit ĂŞtre un mot ou un double mot en mĂŠmoire.
FISUBR source ST0 = (float) source - ST0. Soustrait ST0 d'un entier. La source doit ĂŞtre un mot ou un double-mot en mĂŠmoire.
VII-C-2-c. Multiplication et division▲
Les instructions de multiplication sont totalement analogues Ă celles d'addition.
FMUL source ST0 *= source . La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FMUL dest, ST0 dest *= ST0. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FMULP dest ou FMULP dest, ST0 dest *= ST0 puis retire ST0 de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FIMUL source ST0 *= (float) source. Multiplie un entier avec ST0. La source peut ĂŞtre un mot ou un double-mot en mĂŠmoire.
Ce n'est pas ĂŠtonnant, les instructions de division sont analogues Ă celles de soustraction. La division par zĂŠro donne l'infini.
FDIV source ST0 /= source . La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FDIVR source ST0 = source / ST0. La source peut ĂŞtre n'importe quel registre du coprocesseur ou un nombre en simple ou double prĂŠcision en mĂŠmoire.
FDIV dest, ST0 dest /= ST0. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FDIVR dest, ST0 dest = ST0 / dest . La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FDIVP dest ou FDIVP dest, ST0 dest /= ST0 puis retire ST0 de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FDIVRP dest ou FDIVRP dest, ST0 dest = ST0 / dest puis retire ST0 de la pile. La destination peut ĂŞtre n'importe quel registre du coprocesseur.
FIDIV source ST0 /= (float) source. Divise ST0 par un entier. La src doit ĂŞtre un mot ou un double-mot en mĂŠmoire.
FIDIVR source ST0 = (float) source / ST0. Divise un entier par ST0. La source doit ĂŞtre un mot ou un double-mot en mĂŠmoire.
VII-C-2-d. Comparaisons▲
Le coprocesseur effectue Êgalement des comparaisons de nombres en virgule flottante. La famille d'instructions FCOM est faite pour ça.
FCOM source compare ST0 et source. La source peut ĂŞtre un registre du coprocesseur ou un float ou un double en mĂŠmoire.
FCOMP source compare ST0 et source, puis retire ST0 de la pile. La source peut ĂŞtre un registre du coprocesseur ou un float ou un double en mĂŠmoire.
FCOMPP compare ST0 et ST1, puis retire ST0 et ST1 de la pile.
FICOM source compare ST0 et (float) source. La source peut ĂŞtre un entier sur un mot ou un double-mot en mĂŠmoire.
FICOMP source compare ST0 et (float)source, puis retire ST0 de la pile. La source peut ĂŞtre un entier sur un mot ou un double-mot en mĂŠmoire.
FTST compare ST0 et 0,
Ces instructions changent les bits C0, C1, C2 et C3 du registre de statut du coprocesseur. Malheureusement, il n'est pas possible pour le processeur d'accĂŠder Ă ces bits directement. Les instructions de branchement conditionnel utilisent le registre FLAGS, pas le registre de statut du coprocesseur.
Cependant, il est relativement simple de transfĂŠrer les bits du mot de statut dans les bits correspondants du registre FLAGS en utilisant quelques instructions nouvelles :
FSTSW destination stocke le mot de statut du coprocesseur soit dans un mot en mĂŠmoire soit dans le registre AX.
SAHF stocke le registre AH dans le registre FLAGS.
LAHF charge le registre AH avec les bits du registre FLAGS.
La Figure 6.6 montre un court extrait de code en exemple.

Les lignes 5 et 6 transfèrent les bits C0, C1, C2 et C3 du mot de statut du coprocesseur dans le registre FLAGS. Les bits sont transfÊrÊs de façon à être identiques au rÊsultat d'une comparaison de deux entiers non signÊs. C'est pourquoi la ligne 7 utilise une instruction JNA.
Les Pentium Pro (et les processeurs plus rĂŠcents (Pentium II and III)) supportent deux nouveaux opĂŠrateurs de comparaison qui modifient directement le registre FLAGS du processeur.
FCOMI source compare ST0 et source. La source doit ĂŞtre un registre du coprocesseur.
FCOMIP source compare ST0 et source, puis retire ST0 de la pile. La source doit ĂŞtre un registre du coprocesseur.
La Figure 6.7 montre une sous-routine qui trouve le plus grand de deux double en utilisant l'instruction FCOMIP. Ne confondez pas ces instructions avec les fonctions de comparaisons avec un entier (FICOM et FICOMP).

VII-C-2-e. Instructions diverses▲
Cette section traite de diverses autres instructions fournies par le coprocesseur.
FCHS ST0 = - ST0 change le signe de ST0.
FABS ST0 = |ST0| extrait la valeur absolue de ST0.
FSQRT extrait la racine carrĂŠe de ST0.
FSCALE ST0 = ST0 Ă 2[ST1] multiplie ST0 par une puissance de 2 rapidement. ST1 n'est pas retirĂŠ de la pile du coprocesseur.
La Figure 6.8 montre un exemple d'utilisation de cette instruction.

VII-C-3. Exemple : formule quadratique▲
Le premier exemple montre comment la formule quadratique peut ĂŞtre codĂŠe en assembleur. Souvenez-vous, la formule quadratique calcule les solutions de l'ĂŠquation :
ax2 + bx + c = 0
La formule donne deux solutions pour x : x1 et x2.
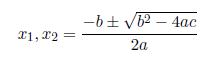
L'expression sous la racine carrĂŠe (b2 ? 4ac) est appelĂŠe le dĂŠterminant. Sa valeur est utile pour dĂŠterminer laquelle des trois possibilitĂŠs suivantes est vĂŠrifiĂŠe pour les solutions :
1. Il n'y a qu'une seule solution double. b2 ? 4ac = 0 ;
2. Il y a deux solutions rĂŠelles. b2 ? 4ac > 0 ;
3. Il y a deux solutions complexes. b2 ? 4ac < 0.
Voici un court programme C qui utilise la sous-routine assembleur :
2
3 int quadratic ( double, double, double, double , double );
4
5 int main()
6 {
7 double a,b,c , root1 , root2;
8
9 printf ("Entrez a , b, c : ");
10 scanf("%lf %lf %lf", &a, &b, &c);
11 if ( quadratic ( a , b, c, &root1, &root2 ) )
12 printf (" racines : %.10g %.10g\n", root1, root2 );
13 else
14 printf ("pas de racine rĂŠelle \n");
15 return 0;
16 }Voici la routine assembleur :
1 ; fonction quadratic
2 ; trouve les solutions Ă l'ĂŠquation quadratique :
3 ; a*x**2 + b*x + c = 0
4 ; prototype C :
5 ; int quadratic( double a, double b, double c,
6 ; double * root1, double *root2 )
7 ; Paramètres :
8 ; a, b, c - coefficients des puissances de l'ĂŠquation quadratique (voir ci-dessus)
9 ; root1 - pointeur vers un double oÚ stocker la première racine
10 ; root2 - pointeur vers un double oÚ stocker la deuxième racine
11 ; Valeur de retour :
12 ; retourne 1 si des racines rĂŠelles sont trouvĂŠes, sinon 0
13
14 ?fine a qword [ebp+8]
15 ?fine b qword [ebp+16]
16 ?fine c qword [ebp+24]
17 ?fine root1 dword [ebp+32]
18 ?fine root2 dword [ebp+36]
19 ?fine disc qword [ebp-8]
20 ?fine one_over_2a qword [ebp-16]
21
22 segment .data
23 MinusFour dw -4
24
25 segment .text
26 global _quadratic
27 _quadratic:
28 push ebp
29 mov ebp, esp
30 sub esp, 16 ; alloue 2 doubles (disc & one_over_2a)
31 push ebx ; on doit sauvegarder l'ebx original
32
33 fild word [MinusFour]; pile : -4
34 fld a ; pile : a, -4
35 fld c ; pile : c, a, -4
36 fmulp st1 ; pile : a*c, -4
37 fmulp st1 ; pile : -4*a*c
38 fld b
39 fld b ; pile : b, b, -4*a*c
40 fmulp st1 ; pile : b*b, -4*a*c
41 faddp st1 ; pile : b*b - 4*a*c
42 ftst ; compare avec 0
43 fstsw ax
44 sahf
45 jb no_real_solutions ; si < 0, pas de solution rĂŠelle
46 fsqrt ; pile : sqrt(b*b - 4*a*c)
47 fstp disc ; stocke et dĂŠcale la pile
48 fld1 ; pile : 1,0
49 fld a ; pile : a, 1,0
50 fscale ; pile : a * 2(1,0) = 2*a, 1
51 fdivp st1 ; pile : 1/(2*a)
52 fst one_over_2a ; pile : 1/(2*a)
53 fld b ; pile : b, 1/(2*a)
54 fld disc ; pile : disc, b, 1/(2*a)
55 fsubrp st1 ; pile : disc - b, 1/(2*a)
56 fmulp st1 ; pile : (-b + disc)/(2*a)
57 mov ebx, root1
58 fstp qword [ebx] ; stocke dans *root1
59 fld b ; pile : b
60 fld disc ; pile : disc, b
61 fchs ; pile : -disc, b
62 fsubrp st1 ; pile : -disc - b
63 fmul one_over_2a ; pile : (-b - disc)/(2*a)
64 mov ebx, root2
65 fstp qword [ebx] ; stocke dans *root2
66 mov eax, 1 ; la valeur de retour est 1
67 jmp short quit
68
69 no_real_solutions :
70 mov eax, 0 ; la valeur de retour est 0
71
72 quit :
73 pop ebx
74 mov esp, ebp
75 pop ebp
76 retVII-C-4. Exemple : lire un tableau depuis un fichier▲
Dans cet exemple, une routine assembleur lit des doubles depuis un fichier. Voici un court programme de test en C :
1 /
2 Ce programme teste la procĂŠdure assembleur 32 bits read_doubles().
3 Il lit des doubles depuis stdin (utilisez une redirection pour lire depuis un fichier).
4 /
5 #include <stdio.h>
6 extern int read_doubles( FILE , double , int );
7 #dene MAX 100
8
9 int main()
10 {
11 int i ,n;
12 double a[MAX];
13
14 n = read_doubles(stdin, a , MAX);
15
16 for ( i=0; i < n; i++ )
17 printf ("= %g\n", i, a[i ]);
18 return 0;
19 }Voici la routine assembleur :
1 segment .data
2 format db "%lf", 0 ; format pour fscanf()
3,
4 segment .text
5 global _read_doubles
6 extern _fscanf
7
8 ?fine SIZEOF_DOUBLE 8
9 ?fine FP dword [ebp + 8]
10 ?fine ARRAYP dword [ebp + 12]
11 ?fine ARRAY_SIZE dword [ebp + 16]
12 ?fine TEMP_DOUBLE [ebp - 8]
13
14 ;
15 ; fonction _read_doubles
16 ; prototype C :
17 ; int read_doubles( FILE * fp, double * arrayp, int array_size );
18 ; Cette fonction lit des doubles depuis un fichier texte dans un tableau, jusqu'Ă
19 ; EOF ou que le tableau soit plein.
20 ; Paramètres :
21 ; fp - FILE pointeur Ă partir duquel lire (doit ĂŞtre ouvert en lecture)
22 ; arrayp - pointeur vers le tableau de double vers lequel lire
23 ; array_size - nombre d'ĂŠlĂŠments du tableau
24 ; Valeur de retour :
25 ; nombre de doubles stockĂŠs dans le tableau (dans EAX)
26
27 _read_doubles:
28 push ebp
29 mov ebp,esp
30 sub esp, SIZEOF_DOUBLE ; dĂŠfinit un double sur la pile
31
32 push esi ; sauve esi
33 mov esi, ARRAYP ; esi = ARRAYP
34 xor edx, edx ; edx = indice du tableau (initialement 0)
35
36 while_loop:
37 cmp edx, ARRAY_SIZE ; edx < ARRAY_SIZE ?
38 jnl short quit ; si non, quitte la boucle
39 ;
40 ; appelle fscanf() pour lire un double dans TEMP_DOUBLE
41 ; fscanf() peut changer edx, donc on le sauvegarde
42 ;
43 push edx ; sauve edx
44 lea eax, TEMP_DOUBLE
45 push eax ; empile &TEMP_DOUBLE
46 push dword format ; emplie &format
47 push FP ; emplie file pointer
48 call _fscanf
49 add esp, 12
50 pop edx ; restaure edx
51 cmp eax, 1 ; fscanf a retournĂŠ 1 ?
52 jne short quit ; si non, on quitte la boucle
53
54 ;
55 ; copie TEMP_DOUBLE dans ARRAYP[edx]
56 ; (Les 8 octets du double sont copiĂŠs en deux fois 4 octets)
57 ;
58 mov eax, [ebp - 8]
59 mov [esi + 8*edx], eax ; copie des 4 octets de poids faible
60 mov eax, [ebp - 4]
61 mov [esi + 8*edx + 4], eax ; copie des 4 octets de poids fort
62
63 inc edx
64 jmp while_loop
65
66 quit :
67 pop esi ; restaure esi
68
69 mov eax, edx ; stocke la valeur de retour dans eax
70
71 mov esp, ebp
72 pop ebp
73 retVII-C-5. Exemple : rechercher les nombres premiers▲
Ce dernier exemple recherche les nombres premiers, une fois de plus.
Cette implĂŠmentation est plus efficace que la prĂŠcĂŠdente. Elle stocke les nombres premiers dĂŠjĂ trouvĂŠs dans un tableau et ne divise que par ceux-ci au lieu de diviser par tous les nombres impairs pour trouver de nouveaux premiers.
Une autre diffÊrence est qu'il calcule la racine carrÊe du candidat pour le prochain premier afin de dÊterminer le moment oÚ il peut s'arrêter de rechercher des facteurs. Il altère le fonctionnement du coprocesseur afin que lorsqu'il stocke la racine sous forme d'entier, il la tronque au lieu de l'arrondir.
Ce sont les bits 10 et 11 du mot de contrĂ´le qui permettent de paramĂŠtrer cela. Ces bits sont appelĂŠs les bits RC (Rounding Control, contrĂ´le d'arrondi).
S'ils sont tous les deux Ă 0 (par dĂŠfaut), le coprocesseur arrondit lorsqu'il convertit vers un entier. S'ils sont tous les deux Ă 1, le copresseur tronque les conversions en entiers. Notez que la routine fait attention Ă sauvegarder le mot de contrĂ´le original et Ă le restaurer avant de quitter.
Voici le programme C pilote :
1 #include <stdio.h>
2 #include <stdlib.h>
3 /
4 fonction nd_primes
5 recherche le nombre indiquĂŠ de nombres premiers
6 èParamtres :
7 a − tableau pour contenir les nombres premiers
8 n − nombre de nombres premiers Ă trouver
9 /
10 extern void nd_primes( int a , unsigned n );
11
12 int main()
13 {
14 int statut ;
15 unsigned i;
16 unsigned max;
17 int a;
18
19 printf ("Combien de nombres premiers voulez-vous trouver ? ");
20 scanf("%u", &max);
21
22 a = calloc ( sizeof(int ), max);
23
24 if ( a ) {
25
26 nd_primes(a,max);
27
28 / affiche les 20 derniers nombres premiers trouvĂŠs /
29 for( i= ( max > 20 ) ? max − 20 : 0; i < max; i++ )
30 printf ("= %d\n", i+1, a[i]);
31
32 free (a);
33 statut = 0;
34 }
35 else {
36 fprintf ( stderr , "Impossible de crĂŠer un tableau de %u entiers\n", max);
37 statut = 1;
38 }
39
40 return statut ;
41 }Voici la routine assembleur :
1 segment .text
2 global _find_primes
3 ;
4 ; fonction find_primes
5 ; trouve le nombre indiquĂŠ de nombres premiers
6 ; Paramètres :
7 ; array - tableau pour contenir les nombres premiers
8 ; n_find - nombre de nombres premiers Ă trouver
9 ; Prototype C :
10 ;extern void find_primes( int * array, unsigned n_find )
11 ;
12 ?fine array ebp + 8
13 ?fine n_find ebp + 12
14 ?fine n ebp - 4 ; Nombre de nombres premiers trouvĂŠs
15 ?fine isqrt ebp - 8 ; racine du candidat
16 ?fine orig_cntl_wd ebp - 10 ; mot de contrĂ´le original
17 ?fine new_cntl_wd ebp - 12 ; nouveau mot de contrĂ´le
18
19 _find_primes :
20 enter 12,0 ; fait de la place pour les variables locales
21
22 push ebx ; sauvegarde les variables registre ĂŠventuelles
23 push esi
24
25 fstcw word [orig_cntl_wd] ; rÊcupère le mot de contrôle courant
26 mov ax, [orig_cntl_wd]
27 or ax, 0C00h ; positionne les bits d'arrondi Ă 11 (tronquer)
28 mov [new_cntl_wd], ax
29 fldcw word [new_cntl_wd]
30
31 mov esi, [array] ; esi pointe sur array
32 mov dword [esi], 2 ; array[0] = 2
33 mov dword [esi + 4], 3 ; array[1] = 3
34 mov ebx, 5 ; ebx = guess = 5
35 mov dword [n], 2 ; n = 2
36 ;
37 ; Cette boucle externe trouve un nouveau nombre premier Ă chaque itĂŠration qu'il
38 ; ajoute Ă la fin du tableau. Contrairement au programme de recherche de nombres
39 ; premier prĂŠcĂŠdent, cette fonction ne dĂŠtermine pas la primautĂŠ du nombre en
40 ; divisant par tous les nombres impairs. Elle ne divise que par les nombres
41 ; premiers qu'elle a dĂŠjĂ trouvĂŠ (c'est pourquoi ils sont stockĂŠs dans un tableau).
42 ;
43 while_limit:
44 mov eax, [n]
45 cmp eax, [n_find] ; while ( n < n_find )
46 jnb short quit_limit
47
48 mov ecx, 1 ; ecx est utilisĂŠ comme indice
49 push ebx ; stocke le candidat sur la pile
50 fild dword [esp] ; le charge sur la pile du coprocesseur
51 pop ebx ; retire le candidat de la pile
52 fsqrt ; calcule sqrt(guess)
53 fistp dword [isqrt] ; isqrt = floor(sqrt(quess))
54 ;
55 ; Cette boucle interne divise le candidat (ebx) par les nombres premiers
56 ; calculĂŠs prĂŠcĂŠdemment jusqu'Ă ce qu'il trouve un de ses facteurs premiers
57 ; (ce qui signifie que le candidat n'est pas premier) ou jusqu'Ă ce que le
58 ; nombre premier par lequel diviser soit plus grand que floor(sqrt(guess))
59 ;
60 while_factor:
61 mov eax, dword [esi + 4*ecx] ; eax = array[ecx]
62 cmp eax, [isqrt] ; while ( isqrt < array[ecx]
63 jnbe short quit_factor_prime
64 mov eax, ebx
65 xor edx, edx
66 div dword [esi + 4*ecx]
67 or edx, edx ; && guess % array[ecx] != 0 )
68 jz short quit_factor_not_prime
69 inc ecx ; essaie le nombre premier suivant
70 jmp short while_factor
71
72 ;
73 ; found a new prime !
74 ;
75 quit_factor_prime :
76 mov eax, [n]
77 mov dword [esi + 4*eax], ebx ; ajoute le candidat au tableau
78 inc eax
79 mov [n], eax ; incrĂŠmente n
80
81 quit_factor_not_prime :
82 add ebx, 2 ; essaie le nombre impair suivant
83 jmp short while_limit
84
85 quit_limit:
86
87 fldcw word [orig_cntl_wd] ; restaure le mot de contrĂ´le
88 pop esi ; restaure les variables registre
89 pop ebx
90
91 leave
92 retVIII. Structures et C++▲
VIII-A. Structures▲
VIII-A-1. Introduction▲
Les structures sont utilisĂŠes en C pour regrouper des donnĂŠes ayant un rapport entre elles dans une variable composite. Cette technique a plusieurs avantages :
1. Cela clarifie le code en montrant que les donnĂŠes dĂŠfinies dans la structure sont intimement liĂŠes ;
2. Cela simplifie le passage des donnĂŠes aux fonctions. Au lieu de passer plusieurs variables sĂŠparĂŠment, elles peuvent ĂŞtre passĂŠes en une seule entitĂŠ ;
3. Cela augmente la localitĂŠ(32) du code.
Du point de vue de l'assembleur, une structure peut ĂŞtre considĂŠrĂŠe comme un tableau avec des ĂŠlĂŠments de tailles variables. Les ĂŠlĂŠments des vrais tableaux sont toujours de la mĂŞme taille et du mĂŞme type. C'est cette propriĂŠtĂŠ qui permet de calculer l'adresse de n'importe quel ĂŠlĂŠment en connaissant l'adresse de dĂŠbut du tableau, la taille des ĂŠlĂŠments et l'indice de l'ĂŠlĂŠment voulu.
Les ĂŠlĂŠments d'une structure ne sont pas nĂŠcessairement de la mĂŞme taille (et habituellement, ils ne le sont pas). Ă cause de cela, chaque ĂŠlĂŠment d'une structure doit ĂŞtre explicitement spĂŠcifiĂŠ et doit recevoir un tag (ou nom) au lieu d'un indice numĂŠrique.
En assembleur, on accède à un ÊlÊment d'une structure d'une façon similaire à l'accès à un ÊlÊment de tableau. Pour accÊder à un ÊlÊment, il faut connaÎtre l'adresse de dÊpart de la structure et le dÊplacement relatif de cet un tableau oÚ ce dÊplacement peut être calculÊ grâce à l'indice de l'ÊlÊment, c'est le compilateur qui affecte un dÊplacement aux ÊlÊments d'une structure.
Par exemple, considĂŠrons la structure suivante :
struct S {
short int x ; / entier sur 2 octets /
int y ; / entier sur 4 octets /
double z ; / ottant sur 8 octets /
};La Figure 7.1 montre Ă quoi pourrait ressembler une variable de type S en mĂŠmoire.
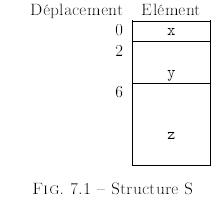
Le standard ANSI C indique que les ÊlÊments d'une structure sont organisÊs en mÊmoire dans le même ordre que celui de leur dÊfinition dans le struct. Il indique Êgalement que le premier ÊlÊment est au tout dÊbut de la structure (i.e. au dÊplacement zÊro). Il dÊfinit Êgalement une macro utile dans le fichier d'en-tête stddef.h appelÊe offsetof(). Cette macro calcule et renvoie le dÊplacement de n'importe quel ÊlÊment d'une structure. La macro prend deux paramètres, le premier est le nom du type de la structure, le second est le nom de l'ÊlÊment dont on veut le dÊplacement. Donc le rÊsultat de offsetof(S, y) serait 2 d'après la Figure 7.1.
VIII-A-2. Alignement en mĂŠmoire▲
Si l'on utilise la macro offsetof pour trouver le dÊplacement de y en utilisant le compilateur gcc, on s'aperçoit qu'elle renvoie 4, pas 2 ! Pourquoi ?
Parce que gcc (et beaucoup d'autres compilateurs) aligne les variables sur des multiples de double-mot par dĂŠfaut.
Souvenez-vous qu'une adresse est sur un multiple de double-mot si elle est divisible par 4.
En mode protĂŠgĂŠ 32 bits, le processeur lit la mĂŠmoire plus vite si la donnĂŠe commence sur un multiple de double-mot. La Figure 7.2 montre Ă quoi ressemble la structure S en utilisant gcc.
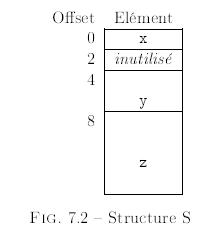
Le compilateur insère deux octets inutilisÊs dans la structure pour aligner y (et z) sur un multiple de double-mot. Cela montre pourquoi c'est une bonne idÊe d'utiliser offsetof pour calculer les dÊplacements, au lieu de les calculer soi-même lorsqu'on utilise des structures en C.
Bien sÝr, si la structure est utilisÊe uniquement en assembleur, le programmeur peut dÊterminer les dÊplacements lui-même. Cependant, si l'on interface du C et de l'assembleur, il est très important que l'assembleur et le C s'accordent sur les dÊplacements des ÊlÊments de la structure ! Une des complications est que des compilateurs C diffÊrents peuvent donner des dÊplacements diffÊrents aux ÊlÊments. Par exemple, comme nous l'avons vu, le compilateur gcc crÊe une structure S qui ressemble à la Figure 7.2, cependant, le compilateur de Borland crÊerait une structure qui ressemble à la Figure 7.1. Les compilateurs C fournissent le moyen de spÊcifier l'alignement utilisÊ pour les donnÊes. Cependant, le standard ANSI C ne spÊcifie pas comment cela doit être fait et donc, des compilateurs diffÊrents procèdent diffÊremment.
Le compilateur gcc a une mĂŠthode flexible et compliquĂŠe de spĂŠcifier l'alignement. Le compilateur permet de spĂŠcifier l'alignement de n'importe quel type en utilisant une syntaxe spĂŠciale. Par exemple, la ligne suivante :
typedef short int unaligned_int __attribute__((aligned(1)));dÊfinit un nouveau type appelÊ unaligned_int qui est alignÊ sur des multiples d'octet (oui, toutes les parenthèses suivant __attribute__ sont nÊcessaires !) Le paramètre 1 de aligned peut être remplacÊ par d'autres puissances de 2 pour spÊcifier d'autres alignements (2 pour s'aligner sur les mots, 4 sur les doubles-mots, etc.). Si l'ÊlÊment y de la structure Êtait changÊ en un type unaligned_int, gcc placerait y au dÊplacement 2. Cependant, z serait toujours au dÊplacement 8 puisque les doubles sont Êgalement alignÊs sur des doubles-mots par dÊfaut. La dÊfinition du type de z devrait aussi être changÊe pour le placer au dÊplacement 6.
Le compilateur gcc permet ĂŠgalement de comprimer (pack) une structure.
Cela indique au compilateur d'utiliser le minimum d'espace possible pour la structure. La Figure 7.3 montre comment S pourrait être rÊÊcrite de cette façon. Cette forme de S utiliserait le moins d'octets possible, soit 14 octets.

Les compilateurs de Microsoft et Borland supportent tous les deux la mĂŞme mĂŠthode pour indiquer l'alignement par le biais d'une directive #pragma.
#pragma pack(1)La directive ci-dessus indique au compilateur d'aligner les ÊlÊments des structures sur des multiples d'un octet (i.e., sans dÊcalage superflu). Le 1 peut être remplacÊ par 2, 4, 8 ou 16 pour spÊcifier un alignement sur des multiples de mots, doubles-mots, quadruples-mots ou de paragraphe, respectivement. La directive reste active jusqu'à ce qu'elle soit ÊcrasÊe par une autre. Cela peut poser des problèmes puisque ces directives sont souvent utilisÊes dans des fichiers d'en-tête. Si le fichier d'en-tête est inclus avant d'autres fichiers d'en-tête dÊfinissant des structures, ces structures peuvent être organisÊes diffÊremment de ce qu'elles auraient ÊtÊ par dÊfaut. Cela peut conduire à des erreurs très difficiles à localiser. Les diffÊrents modules d'un programme devraient organiser les ÊlÊments des structures à diffÊrents endroits !
Il y a une façon d'Êviter ce problème. Microsoft et Borland permettent la sauvegarde de l'Êtat de l'alignement courant et sa restauration. La Figure 7.4 montre comment on l'utilise.

VIII-A-3. Champs de bits▲
Les champs de bits permettent de dĂŠclarer des membres d'une structure qui n'utilisent qu'un nombre de bits donnĂŠ. La taille en bits n'a pas besoin d'ĂŞtre un multiple de 8. Un membre champ de bit est dĂŠfini comme un unsigned int ou un int suivi de deux-points et de sa taille en bits. La Figure 7.5 en montre un exemple.

Elle dĂŠfinit une variable 32 bits dĂŠcomposĂŠe comme suit :

Le premier champ de bits est assignĂŠ aux bits les moins significatifs du double-mot(33).
NĂŠanmoins, le format n'est pas si simple si l'on observe comment les bits sont stockĂŠs en mĂŠmoire. La difficultĂŠ apparaĂŽt lorsque les champs de bits sont Ă cheval sur des multiples d'octets. Car les octets, sur un processeur little endian seront inversĂŠs en mĂŠmoire. Par exemple, les champs de bits de la structure S ressembleront Ă cela en mĂŠmoire :

L'ĂŠtiquette f2l fait rĂŠfĂŠrence aux cinq derniers bits (i.e., les cinq bits les moins significatifs) du champ de bits f2. L'ĂŠtiquette f2m fait rĂŠfĂŠrence aux cinq bits les plus significatifs de f2. Les lignes verticales doubles montrent les limites d'octets. Si l'on inverse tous les octets, les morceaux des champs f2 et f3 seront rĂŠunis correctement.
L'organisation de la mĂŠmoire physique n'est habituellement pas importante Ă moins que des donnĂŠes soient transfĂŠrĂŠes depuis ou vers le programme (ce qui est en fait assez courant avec les champs de bits). Il est courant que les interfaces de pĂŠriphĂŠriques matĂŠriels utilisent des nombres impairs de bits dont les champs de bits facilitent la reprĂŠsentation.
Un bon exemple est SCSI(34). Une commande de lecture directe pour un pĂŠriphĂŠrique SCSI est spĂŠcifiĂŠe en envoyant un message de six octets au pĂŠriphĂŠrique selon le format indiquĂŠ dans la Figure 7.6.

La difficultÊ de reprÊsentation en utilisant les champs de bits est l'adresse de bloc logique qui est à cheval sur trois octets diffÊrents de la commande. D'après la Figure 7.6, on constate que les donnÊes sont stockÊes au format big endian. La Figure 7.7 montre une dÊfinition qui essaie de fonctionner avec tous les compilateurs.

Les deux premières lignes dÊfinissent une macro qui est vraie si le code est compilÊ avec un compilateur Borland ou Microsoft. La partie qui peut porter à confusion va des lignes 11 à 14. Tout d'abord, on peut se demander pourquoi les champs lba_mid et lba_lsb sont dÊfinis sÊparÊment et non pas comme un champ unique de 16 bits. C'est parce que les donnÊes sont stockÊes au format big endian. Un champ de 16 bits serait stockÊ au format little endian par le compilateur. Ensuite, les champs lba_msb et logical_unit semblent être inversÊs, cependant, ce n'est pas le cas. Ils doivent être placÊs dans cet ordre. La Figure 7.8 montre comment les champs sont organisÊs sous la forme d'une entitÊ de 48 bits (les limites d'octets sont là encore reprÊsentÊes par des
lignes doubles).

Lorsqu'elle est stockĂŠe en mĂŠmoire au format little endian, les bits sont rĂŠarrangĂŠs au format voulu (Figure 7.6).
Pour compliquer encore plus le problème, la dÊfinition de SCSI_read_cmd ne fonctionne pas correctement avec le C Microsoft. Si l'expression sizeof(SCSI_read_cmd) est ÊvaluÊe, le C Microsoft renvoie 8 et non pas 6 ! C'est parce que le compilateur Microsoft utilise le type du champ de bits pour dÊterminer comment organiser les bits. Comme tous les bits sont dÊclarÊs comme unsigned, le compilateur ajoute deux octets à la fin de la structure pour qu'elle comporte un nombre entier de doubles-mots. Il est possible d'y remÊdier en dÊclarant tous les champs unsigned short. Maintenant, le compilateur Microsoft n'a plus besoin d'ajouter d'octets d'alignement puisque six octets forment un nombre entier de mots de deux octets(35). Les autres compilateurs fonctionnent Êgalement correctement avec ce changement. La Figure 7.9 montre une autre dÊfinition qui fonctionne sur les trois compilateurs.

Elle ne dĂŠclare plus que deux champs de bits en utilisant le type unsigned char.
Le lecteur ne doit pas se dĂŠcourager s'il trouve la discussion ci-dessus confuse. C'est confus ! L'auteur trouve souvent moins confus d'ĂŠviter d'utiliser des champs de bits en utilisant des opĂŠrations niveau bit pour examiner et modifier les bits manuellement.
VIII-A-4. Utiliser des structures en assembleur▲
Comme nous l'avons dit plus haut, accĂŠder Ă une structure en assembleur ressemble beaucoup Ă accĂŠder Ă un tableau. Prenons un exemple simple, regardons comment l'on pourrait ĂŠcrire une routine assembleur qui mettrait Ă zĂŠro l'ĂŠlĂŠment y d'une structure S. Supposons que le prototype de la routine soit :
void zero_y( S s_p );La routine assembleur serait :
1 ?fine y_offset 4
2 _zero_y :
3 enter 0,0
4 mov eax, [ebp + 8] ; rÊcupère s_p depuis la pile
5 mov dword [eax + y_offset], 0
6 leave
7 retLe C permet de passer une structure par valeur Ă une fonction. Cependant, c'est une mauvaise idĂŠe la plupart du temps. Toutes les donnĂŠes de la structure doivent ĂŞtre copiĂŠes sur la pile puis rĂŠcupĂŠrĂŠes par la routine. Il est beaucoup plus efficace de passer un pointeur vers la structure Ă la place.
Le C permet aussi qu'une fonction renvoie une structure. Ăvidemment, une structure ne peut pas ĂŞtre retournĂŠe dans le registre EAX. Des compilateurs diffĂŠrents gèrent cette situation de façon diffĂŠrente. Une situation courante que les compilateurs utilisent est de rĂŠĂŠcrire la fonction en interne de façon Ă ce qu'elle prenne un pointeur sur la structure en paramètre. Le pointeur est utilisĂŠ pour placer la valeur de retour dans une structure dĂŠfinie en dehors de la routine appelĂŠe.
La plupart des assembleurs (y compris NASM) ont un support intĂŠgrĂŠ pour dĂŠfinir des structures dans votre code assembleur. Reportez-vous Ă votre documentation pour plus de dĂŠtails.
VIII-B. Assembleur et C++▲
Le langage de programmation C++ est une extension du langage C. Beaucoup des règles valables pour interfacer le C et l'assembleur s'appliquent Êgalement au C++. Cependant, certaines règles doivent être modifiÊes. De plus, certaines extensions du C++ sont plus faciles à comprendre en connaissant le langage assembleur. Cette section suppose une connaissance basique du C++.
VIII-B-1. Surcharge et dĂŠcoration de noms▲
Le C++ permet de dĂŠfinir des fonctions (et des fonctions membres) diffĂŠrentes avec le mĂŞme nom. Lorsque plus d'une fonction partage le mĂŞme nom, les fonctions sont dites surchargĂŠes. Si deux fonctions sont dĂŠfinies avec le mĂŞme nom en C, l'ĂŠditeur de liens produira une erreur, car il trouvera deux dĂŠfinitions pour le mĂŞme symbole dans les fichiers objet qu'il est en train de lier. Par exemple, prenons le code de la Figure 7.10.

Le code assembleur ĂŠquivalent dĂŠfinirait deux ĂŠtiquettes appelĂŠes _f ce qui serait bien sĂťr une
erreur. Le C++ utilise le même procÊdÊ d'Êdition de liens que le C, mais Êvite cette erreur en effectuant une dÊcoration de nom (name mangling) ou en modifiant le symbole utilisÊ pour nommer une fonction. D'une certaine façon, le C utilise dÊjà la dÊcoration de nom. Il ajoute un caractère de soulignement au nom de la fonction C lorsqu'il crÊe l'Êtiquette pour la fonction. Cependant, il dÊcorera le nom des deux fonctions de la Figure 7.10 de la même façon et produira une erreur. Le C++ utilise un procÊdÊ de dÊcoration plus sophistiquÊ qui produit deux Êtiquettes diffÊrentes pour les fonctions. Par exemple, la première fonction de la Figure 7.10 recevrait l'Êtiquette _f__Fi et la seconde, _f__Fd, sous DJGPP. Cela Êvite toute erreur d'Êdition de liens.
Malheureusement, il n'y a pas de standard sur la gestion des noms en C++ et des compilateurs diffÊrents dÊcorent les noms de façon diffÊrente.
Par exemple, Borland C++ utiliserait les Êtiquettes @f$qi et @f$qd pour les deux fonctions de la Figure 7.10. Cependant, les règles ne sont pas totalement arbitraires. Le nom dÊcorÊ encode la signature de la fonction. La signature d'une fonction est donnÊe par l'ordre et le type de ses paramètres. Notez que la fonction qui ne prend qu'un argument int a un i à la fin de son nom dÊcorÊ (à la fois sous DJGPP et Borland) et que celle qui prend un argument double a un d à la fin de son nom dÊcorÊ. S'il y avait une fonction appelÊe f avec le prototype suivant :
void f ( int x , int y , double z);DJGPP dĂŠcorerait son nom en _f__Fiid et Borland en @f$qiid.
Le type de la fonction ne fait pas partie de la signature d'une fonction et n'est pas encodÊ dans le nom dÊcorÊ. Ce fait explique une règle de la surcharge en C++. Seules les fonctions dont les signatures sont uniques peuvent être surchargÊes. Comme on le voit, si deux fonctions avec le même nom et la même signature sont dÊfinies en C++, elles donneront le même nom dÊcorÊ et crÊeront une erreur lors de l'Êdition de liens. Par dÊfaut, toutes les fonctions C++ sont dÊcorÊes, même celles qui ne sont pas surchargÊes. Lorsqu'il compile un fichier, le compilateur n'a aucun moyen de savoir si une fonction particulière est surchargÊe ou non, il dÊcore donc tous les noms. En fait, il dÊcore Êgalement les noms des variables globales en encodant le type de la variable d'une façon similaire à celle utilisÊe pour les signatures de fonctions.
Donc, si l'on dÊfinit une variable globale dans un fichier avec un certain type puis que l'on essaie de l'utiliser dans un autre fichier avec le mauvais type, l'Êditeur de liens produira une erreur. Cette caractÊristique du C++ est connue sous le nom de typesafe linking (Êdition de liens avec respect des types) . Cela crÊe un autre type d'erreurs, les prototypes inconsistants. Cela arrive lorsque la dÊfinition d'une fonction dans un module ne correspond pas avec le prototype utilisÊ par un autre module. En C, cela peut être un problème très difficile à corriger. Le C ne dÊtecte pas cette erreur. Le programme compilera et sera liÊ, mais aura un comportement imprÊvisible, car le code appelant placera sur la pile des types diffÊrents de ceux que la fonction attend. En C++ cela produira une erreur lors de l'Êdition de liens.
Lorsque le compilateur C++ analyse un appel de fonction, il recherche la fonction correspondante en observant les arguments qui lui sont passĂŠs(36).
S'il trouve une correspondance, il crÊe un CALL vers la fonction adÊquate en utilisant les règles de dÊcoration du compilateur.
Comme des compilateurs diffÊrents utilisent diffÊrentes règles de dÊcoration de nom, il est possible que des codes C++ compilÊs par des compilateurs diffÊrents ne puissent pas être liÊs ensemble. C'est important lorsque l'on a l'intention d'utiliser une bibliothèque C++ prÊcompilÊe ! Si l'on veut Êcrire une fonction en assembleur qui sera utilisÊe avec du code C++, il faut connaÎtre les règles de dÊcoration de nom du compilateur C++ utilisÊ (ou utiliser la technique expliquÊe plus bas).
L'Êtudiant astucieux pourrait se demander si le code de la Figure 7.10 fonctionnera de la façon attendue. Comme le C++ dÊcore toutes les fonctions, alors la fonction printf sera dÊcorÊe et le compilateur ne produira pas un CALL à l'Êtiquette _printf. C'est une question pertinente. Si le prototype de printf Êtait simplement placÊ au dÊbut du fichier, cela arriverait. Son prototype est :
int printf ( const char , ...);DJGPP dÊcorerait ce nom en _printf__FPCce (F pour fonction, P pour pointeur, C pour const, c pour char et e pour ellipse). Cela n'appellerait pas la fonction printf de la bibliothèque C standard ! Bien sÝr, il doit y avoir un moyen pour que le C++ puisse appeler du code C. C'est très important, car il existe une Ênorme quantitÊ de vieux code C utile. En plus de permettre l'accès au code hÊritÊ de C, le C++ permet Êgalement d'appeler du code assembleur en utilisant les conventions de dÊcoration standard du C.
Le C++ ĂŠtend le mot-clĂŠ extern pour lui permettre de spĂŠcifier que la fonction ou la variable globale qu'il modifie utilise les conventions C normales.
Dans la terminologie C++, la fonction ou la variable globale utilise une ĂŠdition de liens C. Par exemple, pour dĂŠclarer la fonction printf comme ayant une ĂŠdition de liens C, utilisez le prototype :
extern "C" int printf ( const char , ... );Cela impose au compilateur de ne pas utiliser les règles de dÊcoration de nom du C++ sur la fonction, mais d'utiliser les règles C à la place. Cependant, en faisant cela, la fonction printf ne peut pas être surchargÊe. Cela constitue la façon la plus simple d'interfacer du C++ et de l'assembleur, dÊfinir une fonction comme utilisant une Êdition de liens C puis utiliser la convention d'appel C.
Pour plus de facilitĂŠ, le C++ permet ĂŠgalement de dĂŠfinir une ĂŠdition de liens C sur un bloc de fonctions et de variables globales. Le bloc est indiquĂŠ en utilisant les accolades habituelles.
extern "C" {
/ variables globales et prototypes des fonctions ayant une ĂŠdition de liens C /
}Si l'on examine les fichiers d'en-tĂŞte ANSI C fournis avec les compilateurs C/C++ actuels, on trouve ce qui suit vers le dĂŠbut de chaque fichier d'entĂŞte :
#ifdef __cplusplus
extern "C" {
#endifEt une construction similaire, vers la fin, contenant une accolade fermante.
Les compilateurs C++ dÊfinissent la macro __cplusplus (avec deux caractères de soulignement au dÊbut). L'extrait ci-dessus entoure tout le fichier d'en-tête dans un bloc extern "C" si le fichier d'en-tête est compilÊ en C++, mais ne fait rien s'il est compilÊ en C (puisqu'un compilateur C gÊnèrerait une erreur de syntaxe sur extern "C"). La même technique peut être utilisÊe par n'importe quel programmeur pour crÊer un fichier d'en-tête pour des routines assembleur pouvant être utilisÊes en C ou en C++.
VIII-B-2. RĂŠfĂŠrences▲
Les rÊfÊrences sont une autre nouvelle fonctionnalitÊ du C++. Elles permettent de passer des paramètres à une fonction sans utiliser explicitement de pointeur. Par exemple, considÊrons le code de la Figure 7.11.

En fait, les paramètres par rÊfÊrence sont plutôt simples, ce sont des pointeurs. Le compilateur masque simplement ce fait aux yeux du programmeur (exactement de la même façon que les compilateurs Pascal qui implÊmentent les paramètres var comme des pointeurs). Lorsque le compilateur gÊnère l'assembleur pour l'appel de fonction ligne 7, il passe l'adresse de y. Si l'on Êcrivait la fonction f en assembleur, on ferait comme si le prototype Êtait(37) :
void f ( int xp);Les rÊfÊrences sont juste une facilitÊ qui est particulièrement utile pour la surcharge d'opÊrateurs. C'est une autre fonctionnalitÊ du C++ qui permet de donner une signification aux opÊrateurs de base lorsqu'ils sont appliquÊs à des structures ou des classes. Par exemple, une utilisation courante est de dÊfinir l'opÊrateur plus (+) de façon à ce qu'il concatène les objets string.
Donc, si a et b sont des strings, a + b renverra la concatÊnation des chaÎnes a et b. Le C++ appellerait en rÊalitÊ une fonction pour ce faire (en fait, cette expression pourrait être rÊÊcrite avec une notation fonction sous la forme operator +(a,b)). Pour plus d'efficacitÊ, il est souhaitable de passer l'adresse des objets string à la place de les passer par valeur. Sans rÊfÊrence, cela pourrait être fait en Êcrivant operator +(&a,&b), mais cela imposerait d'Êcrire l'opÊrateur avec la syntaxe &a + &b. Cela serait très maladroit et confus. Par contre, en utilisant les rÊfÊrences, il est possible d'Êcrire a + b, ce qui semble très naturel.
VIII-B-3. Fonctions inline▲
Les fonctions inline sont encore une autre fonctionnalitÊ du C++(38). Les fonctions inline sont destinÊes à remplacer les macros du prÊprocesseur qui prennent des paramètres, sources d'erreur. Sourvenez-vous en C, une macro qui Êlève un nombre au carrÊ ressemble à cela :
#dene SQR(x) ((x)(x))Comme le prÊprocesseur ne comprend pas le C et ne fait que de simples substitutions, les parenthèses sont requises pour calculer le rÊsultat correct dans la plupart des cas. Cependant, même cette version ne donnerait pas la bonne rÊponse pour SQR(x++).
Les macros sont utilisÊes, car elles Êliminent la surcharge d'un appel pour une fonction simple. Comme le chapitre sur les sous-programmes l'a dÊmontrÊ, effectuer un appel de fonction implique plusieurs Êtapes. Pour une fonction très simple, le temps passÊ à l'appeler peut être plus grand que celui passÊ dans la fonction ! Les fonctions inline sont une façon beaucoup plus pratique d'Êcrire du code qui ressemble à une fonction, mais qui n'effectue pas de CALL à un bloc commun. Au lieu de cela, les appels à des fonctions inline sont remplacÊs par le code de la fonction. Le C++ permet de rendre une fonction inline en plaçant le mot-clÊ inline au dÊbut de sa dÊfinition.
Par exemple, considĂŠrons les fonctions dĂŠclarĂŠes dans la Figure 7.12.

L'appel Ă la fonction f, ligne 10, est un appel de fonction normal (en assembleur, en supposant que x est Ă l'adresse ebp-8 et y en ebp-4) :
1 push dword [ebp-8]
2 call _f
3 pop ecx
4 mov [ebp-4], eaxCependant, l'appel Ă la fonction inline_f, ligne 11 ressemblerait Ă :
1 mov eax, [ebp-8]
2 imul eax, eax
3 mov [ebp-4], eaxDans ce cas, il y a deux avantages à inliner. Tout d'abord, la fonction inline est plus rapide. Aucun paramètre n'est placÊ sur la pile, aucun cadre de pile n'est crÊÊ puis dÊtruit, aucun branchement n'est effectuÊ. Ensuite, l'appel à la fonction inline utilise moins de code ! Ce dernier point est vrai pour cet exemple, mais ne reste pas vrai dans tous les cas.
La principal inconvÊnient de l'inlining est que le code inline n'est pas liÊ et donc le code d'une fonction inline doit être disponible pour tous les fichiers qui l'utilisent. L'exemple de code assembleur prÊcÊdent le montre. L'appel de la fonction non-inline ne nÊcessite que la connaissance des paramètres, du type de valeur de retour, de la convention d'appel et du nom de l'Êtiquette de la fonction. Toutes ces informations sont disponibles par le biais du prototype de la fonction. Cependant, l'utilisation de la fonction inline nÊcessite la connaissance de tout le code de la fonction. Cela signifie que si n'importe quelle partie de la fonction change, tous les fichiers source qui utilisent la fonction doivent être recompilÊs. Souvenez-vous que pour les fonctions non inline, si le prototype ne change pas, souvent les fichiers qui utilisent la fonction n'ont pas besoin d'être recompilÊs. Pour toutes ces raisons, le code des fonctions inline est gÊnÊralement placÊ dans les fichiers d'en-tête. Cette pratique est contraire à la règle stricte habituelle du C selon laquelle on ne doit jamais placer de code exÊcutable dans les fichiers d'en-tête.
VIII-B-4. Classes▲
Une classe C++ dÊcrit un type d'objet. Un objet possède à la fois des membres donnÊes et des membres fonctions(39). En d'autres termes, il s'agit d'une struct à laquelle sont associÊes des donnÊes et des fonctions. ConsidÊrons la classe simple dÊnie dans la Figure 7.13.

Une variable de type Simple ressemblerait Ă une struct C normale avec un seul membre int.
Les fonctions ne sont pas affectÊes à la structure en mÊmoire. Cependant, les fonctions membres sont diffÊrentes des autres fonctions. On leur passe un paramètre cachÊ. Ce paramètre est un pointeur vers l'objet sur lequel agit la fonction.
En fait, le C++ utilise le mot-clĂŠ this pour accĂŠder au pointeur vers l'objet lorsque l'on se trouve Ă l'intĂŠrieur d'une fonction membre.
Par exemple, considĂŠrons la mĂŠthode set_data de la classe Simple de la Figure 7.13. Si elle ĂŠtait ĂŠcrite en C, elle ressemblerait Ă une fonction Ă laquelle on passerait explicitement un pointeur vers l'objet sur lequel elle agit comme le montre le code de la Figure 7.14.

L'option -S du compilateur DJGPP (et des compilateurs gcc et Borland Êgalement) indique au compilateur de produire un fichier assembleur contenant l'Êquivalent assembleur du code. Pour DJGPP et gcc le fichier assembleur possède une extension .s et utilise malheureusement la syntaxe du langage assembleur AT&T qui est assez diffÊrente des syntaxes NASM et MASM(40) (les compilateurs Borland et MS gÊnèrent un fichier avec l'extension .asm utilisant la syntaxe MASM). La Figure 7.15 montre la sortie de DJGPP convertie en syntaxe NASM avec des commentaires supplÊmentaires pour clarifier le but des instructions.

Sur la toute première ligne, notez que la mÊthode set_data reçoit une Êtiquette dÊcorÊe qui encode le nom de la mÊthode, le nom de la classe et les paramètres.
Le nom de la classe est encodÊ, car d'autres classes peuvent avoir une mÊthode appelÊe set_data et les deux mÊthodes doivent recevoir des Êtiquettes diffÊrentes. Les paramètres sont encodÊs afin que la classe puisse surcharger la mÊthode set_data afin qu'elle prenne d'autres paramètres, comme les fonctions C++ normales. Cependant, comme prÊcÊdemment, des compilateurs diffÊrents encoderont ces informations diffÊremment dans l'Êtiquette.
Ensuite, aux lignes 2 et 3 nous retrouvons le prologue habituel. à la ligne 5, le premier paramètre sur la pile est stockÊ dans EAX. Ce n'est pas le paramètre x ! Il s'agit du paramètre cachÊ(41) qui pointe vers l'objet sur lequel on agit.
La ligne 6 stocke le paramètre x dans EDX et la ligne 7 stocke EDX dans le double-mot sur lequel pointe EAX. Il s'agit du membre data de l'objet Simple sur lequel on agit, qui, Êtant la seule donnÊe de la classe, est stockÊ au dÊplacement 0 de la structure Simple.
VIII-B-4-a. Exemple▲
Cette section utilise les idĂŠes de ce chapitre pour crĂŠer une classe C++ qui reprĂŠsente un entier non signĂŠ d'une taille arbitraire. Comme l'entier peut faire n'importe quelle taille, il sera stockĂŠ dans un tableau d'entiers non signĂŠs (doubles-mots). Il peut faire n'importe quelle taille en utilisant l'allocation dynamique. Les doubles-mots sont stockĂŠs dans l'ordre inverse(42) (i.e. le double-mot le moins significatif est au dĂŠplacement 0). La Figure 7.16 montre la dĂŠfinition de la classe Big_int(43).

La taille d'un Big_int est mesurĂŠe par la taille du tableau d'unsigned utilisĂŠ pour stocker les donnĂŠes.
La donnĂŠe membre size_ de la classe est affectĂŠe au dĂŠplacement 0 et le membre number_ est affectĂŠ au dĂŠplacement 4.
Pour simplifier l'exemple, seuls les objets ayant des tableaux de la mĂŞme taille peuvent ĂŞtre additionnĂŠs entre eux.
La classe a trois constructeurs : le premier (ligne 9) initialise l'instance de la classe en utilisant un entier non signÊ normal, le second (ligne 19) initalise l'instance en utilisant une chaÎne qui contient une valeur hexadÊcimale. Le troisième constructeur (ligne 22) est le constructeur par copie.
Cette explication se concentre sur la façon dont fonctionnent les opÊrateurs d'addition et de soustraction, car c'est là que l'on utilise de l'assembleur.
La Figure 7.17 montre les parties du fichier d'en-tĂŞte relatives Ă ces opĂŠrateurs.

Elles montrent comment les opÊrateurs sont paramÊtrÊs pour appeler des routines assembleur. Comme des compilateurs diffÊrents utilisent des règles de dÊcoration radicalement diffÊrentes pour les fonctions opÊrateur, des fonctions opÊrateur inline sont utilisÊes pour initialiser les appels aux routines assembleur liÊes au format C. Cela les rend relativement simples à porter sur des compilateurs diffÊrents et est aussi rapide qu'un appel direct.
Cette technique ĂŠlimine ĂŠgalement le besoin de soulever une exception depuis l'assembleur !
Pourquoi l'assembleur n'est-il utilisÊ qu'ici ? Souvenez-vous que pour effectuer de l'arithmÊtique en prÊcision multiple, la retenue doit être ajoutÊe au double mot significatif suivant. Le C++ (et le C) ne permet pas au programmeur d'accÊder au drapeau de retenue du processeur. On ne pourrait effectuer l'addition qu'en recalculant indÊpendamment en C++ la valeur du drapeau de retenue et en l'ajoutant de façon conditionnelle au double-mot suivant. Il est beaucoup plus efficace d'Êcrire le code en assembleur à partir duquel on peut accÊder au drapeau de retenue et utiliser l'instruction ADC qui ajoute automatiquement le drapeau de retenue.
Par concision, seule la routine assembleur add_big_ints sera expliquĂŠe ici. Voici le code de cette routine (contenu dans big_math.asm) :
1 segment .text
2 global add_big_ints, sub_big_ints
3 ?fine size_offset 0
4 ?fine number_offset 4
5
6 ?fine EXIT_OK 0
7 ?fine EXIT_OVERFLOW 1
8 ?fine EXIT_SIZE_MISMATCH 2
9
10 ; Paramètres des routines add et sub
11 ?fine res ebp+8
12 ?fine op1 ebp+12
13 ?fine op2 ebp+16
14
15 add_big_ints:
16 push ebp
17 mov ebp, esp
18 push ebx
19 push esi
20 push edi
21 ;
22 ; initialise esi pour pointer vers op1
23 ; edi pour pointer vers op2
24 ; ebx pour pointer vers res
25 mov esi, [op1]
26 mov edi, [op2]
27 mov ebx, [res]
28 ;
29 ; s'assure que les 3 Big_int ont la mĂŞme taille
30 ;
31 mov eax, [esi + size_offset]
32 cmp eax, [edi + size_offset]
33 jne sizes_not_equal ; op1.size_ != op2.size_
34 cmp eax, [ebx + size_offset]
35 jne sizes_not_equal ; op1.size_ != res.size_
36
37 mov ecx, eax ; ecx = taille des Big_int
38 ;
39 ; initialise les registres pour qu'ils pointent vers leurs tableaux respectifs
40 ; esi = op1.number_
41 ; edi = op2.number_
42 ; ebx = res.number_
43 ;
44 mov ebx, [ebx + number_offset]
45 mov esi, [esi + number_offset]
46 mov edi, [edi + number_offset]
47
48 clc ; met le drapeau de retenue Ă 0
49 xor edx, edx ; edx = 0
50 ;
51 ; boucle d'addition
52 add_loop:
53 mov eax, [edi+4*edx]
54 adc eax, [esi+4*edx]
55 mov [ebx + 4*edx], eax
56 inc edx ; ne modifie pas le drapeau de retenue
57 loop add_loop
58
59 jc overflow
60 ok_done:
61 xor eax, eax ; valeur de retour = EXIT_OK
62 jmp done
63 overflow:
64 mov eax, EXIT_OVERFLOW
65 jmp done
66 sizes_not_equal:
67 mov eax, EXIT_SIZE_MISMATCH
68 done:
69 pop edi
70 pop esi
71 pop ebx
72 leave
73 retHeureusement, la majoritĂŠ de ce code devrait ĂŞtre comprĂŠhensible pour le lecteur maintenant. Les lignes 25 Ă 27 stockent les pointeurs vers les objets Big_int passĂŠs Ă la fonction via des registres. Souvenez-vous que les rĂŠfĂŠrences sont des pointeurs. Les lignes 31 Ă 35 vĂŠrifient que les tailles des trois objets sont les mĂŞmes (notez que le dĂŠplacement de size_ est ajoutĂŠ au pointeur pour accĂŠder Ă la donnĂŠe membre). Les lignes 44 Ă 46 ajustent les registres pour qu'ils pointent vers les tableaux utilisĂŠs par leurs objets respectifs au lieu des objets eux-mĂŞmes (lĂ encore, le dĂŠplacement du membre number_ est ajoutĂŠ au pointeur sur l'objet).
La boucle des lignes 52 Ă 57 additionne les entiers stockĂŠs dans les tableaux en additionnant le double-mot le moins significatif en premier, puis les doubles-mots suivants, etc. L'addition doit ĂŞtre effectuĂŠe dans cet ordre pour l'arithmĂŠtique en prĂŠcision ĂŠtendue (voir Section III.A.5).
La ligne 59 vÊrifie qu'il n'y a pas de dÊpassement de capacitÊ, lors d'un dÊpassement de capacitÊ, le drapeau de retenue sera allumÊ par la dernière addition du double-mot le plus significatif. Comme les doubles-mots du tableau sont stockÊs dans l'ordre little endian, la boucle commence au dÊbut du tableau et avance jusqu'à la fin.
La Figure 7.18 montre un court exemple utilisant la classe Big_int.

Notez que les constantes de Big_int doivent ĂŞtre dĂŠclarĂŠes explicitement comme Ă la ligne 16. C'est nĂŠcessaire pour deux raisons. Tout d'abord, il n'y a pas de constructeur de conversion qui convertisse un entier non signĂŠ en Big_int. Ensuite, seuls les Big_int de mĂŞme taille peuvent ĂŞtre additionnĂŠs. Cela rend la conversion problĂŠmatique puisqu'il serait difficile de savoir vers quelle taille convertir. Une implĂŠmentation plus sophistiquĂŠe de la classe permettrait d'additionner n'importe quelle taille avec n'importe quelle autre. L'auteur ne voulait pas compliquer inutilement cet exemple en l'implĂŠmentant ici (cependant, le lecteur est encouragĂŠ Ă le faire).
VIII-B-5. HĂŠritage et polymorphisme▲
L'hĂŠritage permet Ă une classe d'hĂŠriter des donnĂŠes et des mĂŠthodes d'une autre. Par exemple, considĂŠrons le code de la Figure 7.19.

Il montre deux classes, A et B, oĂš la classe B hĂŠrite de A. La sortie du programme est :
Taille de a : 4 DĂŠplacement de ad : 0
Taille de b : 8 DĂŠplacement de ad: 0 DĂŠplacement de bd: 4
A::m()
A::m()Notez que les membres ad des deux classes (B l'hĂŠrite de A) sont au mĂŞme dĂŠplacement. C'est important puisque l'on peut passer Ă la fonction f soit un pointeur vers un objet A soit un pointeur vers un objet de n'importe quel type dĂŠrivĂŠ de (i.e. qui hĂŠrite de) A. La Figure 7.20 montre le code assembleur (ĂŠditĂŠ) de la fonction (gĂŠnĂŠrĂŠ par gcc).

Notez que la sortie de la mÊthode m de A a ÊtÊ produite à la fois par l'objet a et l'objet b. D'après l'assembleur, on peut voir que l'appel à A::m() est codÊ en dur dans la fonction. Dans le cadre d'une vraie programmation orientÊe objet, la mÊthode appelÊe devrait dÊpendre du type d'objet passÊ à la fonction. On appelle cela le polymorphisme. Le C++ dÊsactive cette fonctionnalitÊ par dÊfaut. On utilise le mot-clÊ virtual pour l'activer. La Figure 7.21 montre comment les deux classes seraient modifiÊes.

Rien dans le restet du code n'a besoin d'être changÊ. Le polymorphisme peut être implÊmentÊ de beaucoup de manières. Malheureusement, l'implÊmentation de gcc est en transition au moment d'Êcrire ces lignes et devient beaucoup plus compliquÊe que l'implÊmentation initiale. Afin de simplifier cette explication, l'auteur ne couvrira que l'implÊmentation du polymorphisme que les compilateurs Microsoft et Borland utilisent. Cette implÊmentation n'a pas changÊ depuis des annÊes et ne changera probablement pas dans un futur proche.
Avec ces changements, la sortie du programme change :
Size of a: 8 DĂŠplacement de ad : 4
Size of b: 12 DĂŠplacement de ad : 4 DĂŠplacement de bd : 8
A::m()
B::m()Maintenant, le second appel à f appelle la mÊthode B::m(), car on lui passe un objet B. Ce n'est pas le seul changement cependant. La taille d'un A vaut maintenant 8 (et 12 pour B). De plus, le dÊplacement de ad vaut maintenant 4, plus 0. Qu'y a-t-il au dÊplacement 0 ? La rÊponse à cette question est liÊe à la façon dont est implÊmentÊ le polymorphisme.
Une classe C++ qui a une (ou plusieurs) mĂŠthode(s) virtuelle(s) a un champ cachĂŠ qui est un pointeur vers un tableau de pointeurs sur des mĂŠthodes(44). Cette table est souvent appelĂŠe la vtable. Pour les classes A et B ce pointeur est stockĂŠ au dĂŠplacement 0. Les compilateurs Windows placent toujours ce pointeur au dĂŠbut de la classe au sommet de l'arbre d'hĂŠritage.
En regardant le code assembleur (Figure 7.22) gĂŠnĂŠrĂŠ pour la fonction f (de la Figure 7.19) dans la version du programme avec les mĂŠthodes virtuelles, on peut voir que l'appel Ă la mĂŠthode m ne se fait pas via une ĂŠtiquette.

La ligne 9 trouve l'adresse de la vtable de l'objet. L'adresse de l'objet est placÊe sur la pile ligne 11. La ligne 12 appelle la mÊthode virtuelle en se branchant à la première adresse dans la vtable(45). Cet appel n'utilise pas d'Êtiquette, il se branche à l'adresse du code sur lequel pointe EDX. Ce type d'appel est un exemple de liaison tardive (late binding). La liaison tardive repousse le choix de la mÊthode à appeler au moment de l'exÊcution du code. Cela permet d'appeler la mÊthode correspondant à l'objet. Le cas normal (Figure 7.20) code en dur un appel à une certaine mÊthode et est appelÊ liaison prÊcoce (early binding), car la mÊthode est liÊe au moment de la compilation.
Le lecteur attentif se demandera pourquoi les mÊthodes de classe de la Figure 7.21 sont explicitement dÊclarÊes pour utiliser la convention d'appel C en utilisant le mot-clÊ __cdecl. Par dÊfaut, Microsoft utilise une convention diffÊrente de la convention C standard pour les mÊthodes de classe C++. Il passe le pointeur sur l'objet sur lequel agit la mÊthode via le registre ECX au lieu d'utiliser la pile. La pile est toujours utilisÊe pour les autres paramètres explicites de la mÊthode. Le modificateur __cdecl demande l'utilisation de la convention d'appel C standard. Borland C++ utilise la convention d'appel C par dÊfaut.
Observons maintenant un exemple lÊgèrement plus compliquÊ (Figure 7.23).

Dans celui-lĂ , les classes A et B ont chacune deux mĂŠthodes : m1 et m2. Souvenez-vous que comme la classe B ne dĂŠfinit pas sa propre mĂŠthode m2, elle hĂŠrite de la mĂŠthode de classe de A. La Figure 7.24 montre comment l'objet b apparaĂŽt en mĂŠmoire.
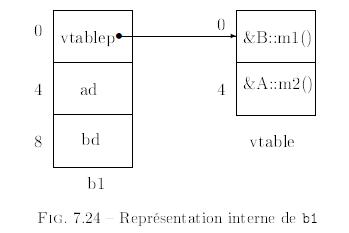
La Figure 7.25 montre la sortie du programme.
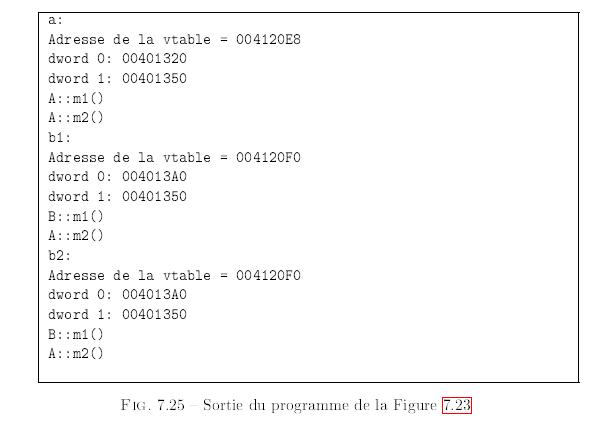
Tout d'abord, regardons l'adresse de la vtable de chaque objet. Les adresses des deux objets B sont les mĂŞmes, ils partagent donc la mĂŞme vtable. Une vtable appartient Ă une classe pas Ă un objet (comme une donnĂŠe membre static). Ensuite, regardons les adresses dans les vtables. En regardant la sortie assembleur, on peut dĂŠterminer que le pointeur sur la mĂŠthode m1 est au dĂŠplacement 0 (ou dword 0) et celui sur m2 est au dĂŠplacement 4 (dword 1). Les pointeurs sur la mĂŠthode m2 sont les mĂŞmes pour les vtables des classes A et B, car la classe B hĂŠrite de la mĂŠthode m2 de la classe A.
Les lignes 25 à 32 montrent comment l'on pourrait appeler une fonction virtuelle en lisant son adresse depuis la vtable de l'objet(46). L'adresse de la mÊthode est stockÊe dans un pointeur de fonction de type C avec un pointeur this explicite. D'après la sortie de la Figure 7.25, on peut voir comment cela fonctionne. Cependant, s'il vous plaÎt, n'Êcrivez pas de code de ce genre ! Il n'est utilisÊ que pour illustrer le fait que les mÊthodes virtuelles utilisent la vtable.
Il y a plusieurs leçons pratiques à tirer de cela. Un fait important est qu'il faut être très attentif lorsque l'on Êcrit ou qu'on lit des variables de type classe depuis un fichier binaire. On ne peut pas utiliser simplement une lecture ou une Êcriture binaire, car cela lirait ou Êcrirait le pointeur vtable depuis le fichier ! C'est un pointeur sur l'endroit oÚ la vtable rÊside dans la mÊmoire du programme et il varie d'un programme à l'autre. La même chose peut arriver avec les structures en C, mais en C, les structures n'ont des pointeurs que si le programmeur en dÊfinit explicitement. Il n'y a pas de pointeurs explicites dÊclarÊs dans les classes A ou B.
Une fois encore, il est nĂŠcessaire de rĂŠaliser que des compilateurs diffĂŠrents implĂŠmentent les mĂŠthodes virtuelles diffĂŠremment. Sous Windows, les objets de la classe COM (Component Object Model) utilisent des vtables pour implĂŠmenter les interfaces COM(47). Seuls les compilateurs qui implĂŠmentent les vtables des mĂŠthodes virtuelles comme le fait Microsoft peuvent crĂŠer des classes COM. C'est pourquoi Borland utilise la mĂŞme implĂŠmentation que Microsoft et une des raisons pour lesquelles gcc ne peut pas ĂŞtre utilisĂŠ pour crĂŠer des classes COM.
Le code des mĂŠthodes virtuelles est identique Ă celui des mĂŠthodes non virtuelles.
Seul le code d'appel est diffĂŠrent. Si le compilateur peut ĂŞtre absolument sĂťr de la mĂŠthode virtuelle qui sera appelĂŠe, il peut ignorer la vtable et appeler la mĂŠthode directement (p.e., en utilisant la liaison prĂŠcoce).
VIII-B-6. Autres fonctionnalitĂŠs C++▲
Le fonctionnement des autres fonctionnalitĂŠs du C++ (p.e., le RunTime Type Information, la gestion des exceptions et l'hĂŠritage multiple) dĂŠpasse le cadre de ce livre. Si le lecteur veut aller plus loin, The Annotated C++ Reference Manual de Ellis et Stroustrup et The Design and Evolution of C++ de Stroustrup constituent un bon point de dĂŠpart.
IX. Annexe A : Instructions 80x86▲
IX-A. Instructions hors virgule flottante▲
Cette section liste et dĂŠcrit les actions et les formats des instructions hors virgule flottante de la famille de processeurs Intel 80x86.
Les formats utilisent les abrĂŠviations suivantes :

Elles peuvent ĂŞtre combinĂŠes pour les instructions Ă plusieurs opĂŠrandes. Par exemple, le format R,R signifie que l'instruction prend deux opĂŠrandes de type registre. Beaucoup d'instructions Ă deux opĂŠrandes acceptent les mĂŞmes opĂŠrandes. L'abrĂŠviation O2 est utilisĂŠe pour reprĂŠsenter ces opĂŠrandes : R,R R,M R,I M,R M,I. Si un registre 8 bits ou un octet en mĂŠmoire peuvent ĂŞtre utilisĂŠs comme opĂŠrande, l'abrĂŠviation R/M8 est utilisĂŠe.
Le tableau montre Êgalement comment les diffÊrents bits du registre FLAGS sont modifiÊs par chaque instruction. Si la colonne est vide, le bit correspondant n'est pas modifiÊ du tout. Si le bit est toujours positionnÊ à une valeur particulière, un 1 ou un 0 figure dans la colonne. Si le bit est positionnÊ à une valeur qui dÊpend des opÊrandes de l'instruction, un C figure dans la colonne. Enfin, si le bit est modifiÊ de façon indÊfinie, un  ?  figure dans la colonne. Comme les seules instructions qui changent le drapeau de direction sont CLD et STD, il ne figure pas parmi les colonnes FLAGS.
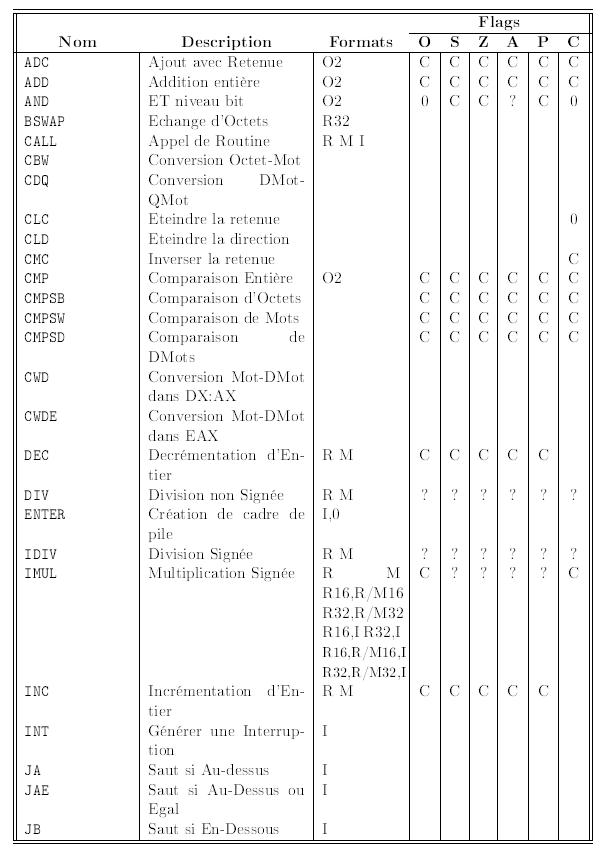



IX-B. Instruction en virgule flottante▲
Dans cette section, la plupart des instructions du coprocesseur mathÊmatique du 80x86 sont dÊcrites. La section description dÊcrit brièvement l'opÊration effectuÊe par l'instruction. Pour Êconomiser de la place, il n'est pas prÊcisÊ si l'instruction dÊcale la pile ou non.
La colonne format indique le type d'opĂŠrande pouvant ĂŞtre utilisĂŠ avec chaque instruction. Les abrĂŠviations suivantes sont utilisĂŠes :

Les instructions nĂŠcessitant un Pentium Pro ou supĂŠrieur sont signalĂŠes par un astĂŠrisque (*).